Near, far: Patch-ordering enhances vision foundation models' scene understanding
作者: Valentinos Pariza, Mohammadreza Salehi, Gertjan Burghouts, Francesco Locatello, Yuki M. Asano
分类: cs.CV, cs.AI
发布日期: 2024-08-20 (更新: 2025-04-17)
备注: Accepted at ICLR25. The webpage is accessible at: https://vpariza.github.io/NeCo/
💡 一句话要点
提出NeCo损失函数,通过patch排序增强视觉基础模型场景理解能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自监督学习 视觉基础模型 场景理解 patch邻域一致性 可微排序
📋 核心要点
- 现有对比学习方法仅提供二元学习信号,限制了模型对空间信息的细粒度理解。
- NeCo通过引入patch邻域一致性损失,利用可微排序,使模型学习patch间的相对关系。
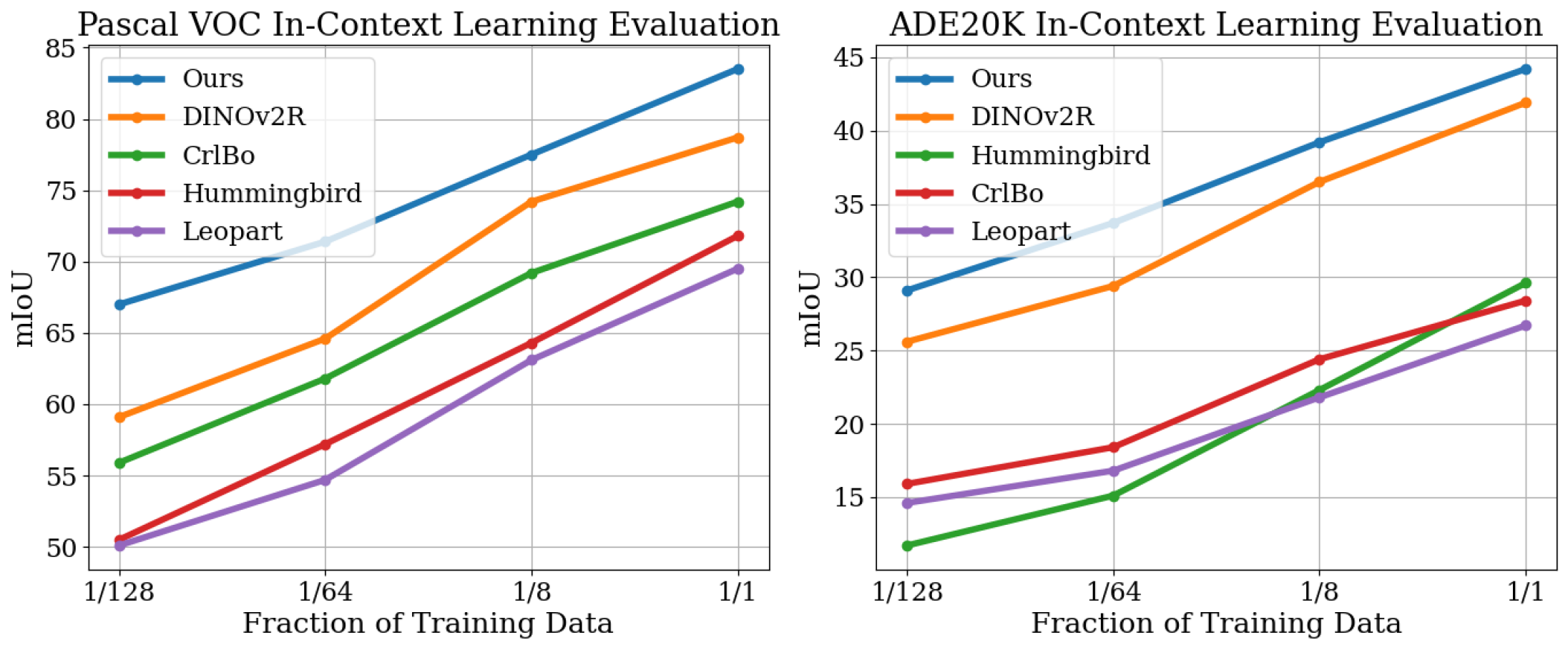
- 实验表明,NeCo在语义分割、线性分割和3D理解任务上均取得了显著的性能提升。
📝 摘要(中文)
本文提出了一种新颖的自监督训练损失函数NeCo(Patch Neighbor Consistency),它强制学生模型和教师模型之间patch级别的最近邻一致性。与仅产生二元学习信号(“吸引”和“排斥”)的对比方法相比,NeCo受益于更细粒度的学习信号,即相对于参考patch对空间密集特征进行排序。该方法利用可微分排序应用于预训练表示(例如DINOv2-registers)之上,以引导学习信号并进一步改进它们。这种密集的后预训练在各种模型和数据集上都带来了卓越的性能,尽管仅需在单个GPU上运行19个小时。该方法生成高质量的密集特征编码器,并建立了多个新的state-of-the-art结果,例如在ADE20k和Pascal VOC上进行非参数上下文语义分割分别提升+5.5%和+6%,在COCO-Things和-Stuff上进行线性分割评估分别提升+7.2%和+5.7%,以及在SPair-71k上进行多视图一致性的3D理解提升超过1.5%。
🔬 方法详解
问题定义:现有自监督学习方法,特别是对比学习,通常只提供二元的学习信号(吸引或排斥),缺乏对图像中patch之间细粒度空间关系的建模能力。这限制了模型对场景的深入理解,尤其是在需要理解上下文信息的任务中,例如语义分割。
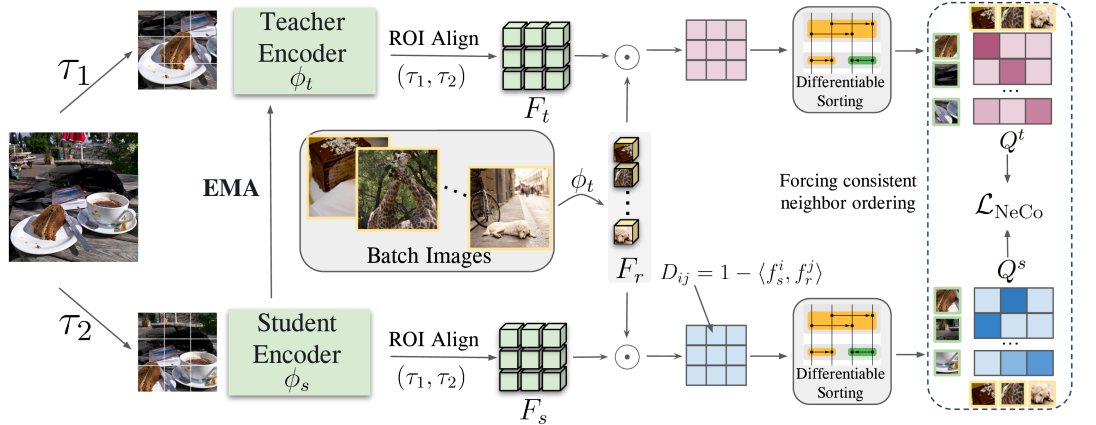
核心思路:本文的核心思路是利用patch邻域的一致性。具体来说,如果两个patch在空间上相邻,那么它们在特征空间中也应该具有相似的邻域结构。通过强制学生模型和教师模型在patch邻域结构上保持一致,可以使学生模型学习到更丰富的空间信息。
技术框架:NeCo方法的整体框架包括以下几个步骤:1) 使用预训练的视觉模型(如DINOv2)提取图像的patch特征。2) 对提取的特征进行可微排序,得到每个patch的邻域结构。3) 计算学生模型和教师模型在patch邻域结构上的差异,作为NeCo损失。4) 使用NeCo损失训练学生模型,使其学习到与教师模型一致的patch邻域结构。
关键创新:NeCo的关键创新在于引入了patch邻域一致性损失,并利用可微排序来计算patch的邻域结构。与传统的对比学习方法相比,NeCo可以提供更细粒度的学习信号,从而使模型学习到更丰富的空间信息。此外,NeCo可以很容易地应用于各种预训练的视觉模型,并进一步提升它们的性能。
关键设计:NeCo损失函数的设计是关键。它基于学生模型和教师模型提取的patch特征,通过可微排序算法确定每个patch的最近邻。然后,计算两个模型预测的邻域结构之间的差异,例如使用交叉熵损失。教师模型的参数通常采用动量更新的方式,以保证训练的稳定性。此外,论文还探索了不同的排序算法和邻域大小对性能的影响。
🖼️ 关键图片

📊 实验亮点
NeCo在多个数据集上取得了显著的性能提升。在ADE20k和Pascal VOC上的非参数上下文语义分割分别提升了+5.5%和+6%,在COCO-Things和-Stuff上的线性分割评估分别提升了+7.2%和+5.7%,在SPair-71k上的多视图一致性3D理解提升超过1.5%。这些结果表明,NeCo能够有效提升视觉模型的场景理解能力。
🎯 应用场景
该研究成果可广泛应用于计算机视觉领域,例如图像分割、目标检测、场景理解等。高质量的密集特征编码器能够提升下游任务的性能,尤其是在需要理解上下文信息的任务中。此外,该方法还可以应用于机器人导航、自动驾驶等领域,帮助机器人更好地理解周围环境。
📄 摘要(原文)
We introduce NeCo: Patch Neighbor Consistency, a novel self-supervised training loss that enforces patch-level nearest neighbor consistency across a student and teacher model. Compared to contrastive approaches that only yield binary learning signals, i.e., 'attract' and 'repel', this approach benefits from the more fine-grained learning signal of sorting spatially dense features relative to reference patches. Our method leverages differentiable sorting applied on top of pretrained representations, such as DINOv2-registers to bootstrap the learning signal and further improve upon them. This dense post-pretraining leads to superior performance across various models and datasets, despite requiring only 19 hours on a single GPU. This method generates high-quality dense feature encoders and establishes several new state-of-the-art results such as +5.5% and +6% for non-parametric in-context semantic segmentation on ADE20k and Pascal VOC, +7.2% and +5.7% for linear segmentation evaluations on COCO-Things and -Stuff and improvements in the 3D understanding of multi-view consistency on SPair-71k, by more than 1.5%.