FLAME: Learning to Navigate with Multimodal LLM in Urban Environments
作者: Yunzhe Xu, Yiyuan Pan, Zhe Liu, Hesheng Wang
分类: cs.CV, cs.AI, cs.CL, cs.RO
发布日期: 2024-08-20 (更新: 2025-01-21)
备注: Accepted to AAAI 2025 (Oral)
💡 一句话要点
FLAME:一种基于多模态LLM的城市环境导航学习方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态LLM 视觉-语言导航 城市环境 具身智能 三阶段微调
📋 核心要点
- 现有VLN方法在处理复杂城市环境导航时,依赖特定模型,通用性不足,难以有效利用LLM的强大泛化能力。
- FLAME通过三阶段微调策略,将多模态LLM适配到城市VLN任务,包括单感知、多感知和端到端训练,提升导航性能。
- 实验表明,FLAME在Touchdown数据集上超越了现有SOTA方法,任务完成度提升7.3%,验证了多模态LLM在复杂导航任务中的潜力。
📝 摘要(中文)
大型语言模型(LLM)在视觉-语言导航(VLN)任务中展现了潜力,但当前的应用面临挑战。尽管LLM擅长通用对话场景,但在专门的导航任务中表现不佳,与专门的VLN模型相比,性能欠佳。我们提出了FLAME(基于FLAMingo架构的具身智能体),一种新颖的基于多模态LLM的智能体和架构,专为城市VLN任务设计,可以有效地处理多个观测。我们的方法采用三阶段微调技术,以有效适应导航任务,包括用于街景描述的单感知微调、用于路线总结的多感知微调以及VLN数据集上的端到端训练。增强数据集是自动合成的。实验结果表明,FLAME优于现有方法,在Touchdown数据集上的任务完成度提高了7.3%,超过了最先进的方法。这项工作展示了多模态LLM(MLLM)在复杂导航任务中的潜力,代表了MLLM在具身智能领域应用方面的一项进步。
🔬 方法详解
问题定义:论文旨在解决视觉-语言导航(VLN)任务中,现有方法难以有效利用大型语言模型(LLM)的泛化能力,导致在复杂城市环境中导航性能不佳的问题。现有方法通常依赖于专门设计的VLN模型,缺乏通用性和灵活性。
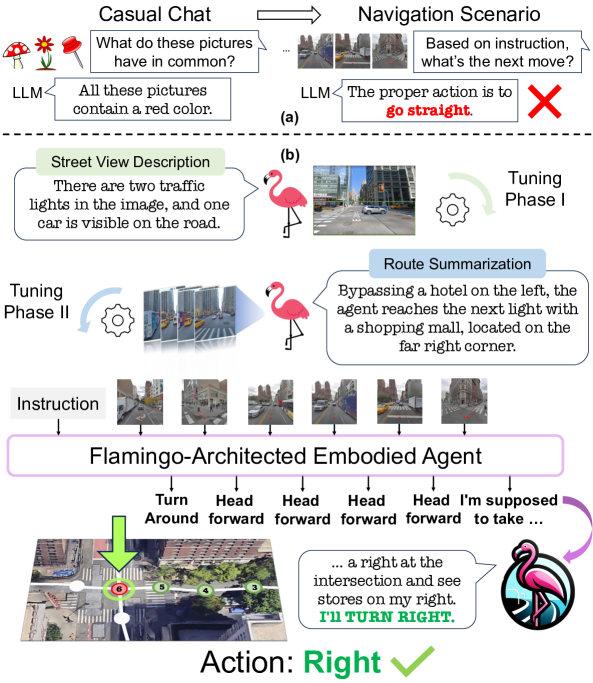
核心思路:论文的核心思路是利用多模态LLM(MLLM)的强大能力,通过针对性的微调策略,使其适应城市VLN任务。通过将视觉信息与语言指令相结合,使智能体能够理解导航指令,并根据环境感知做出合理的导航决策。
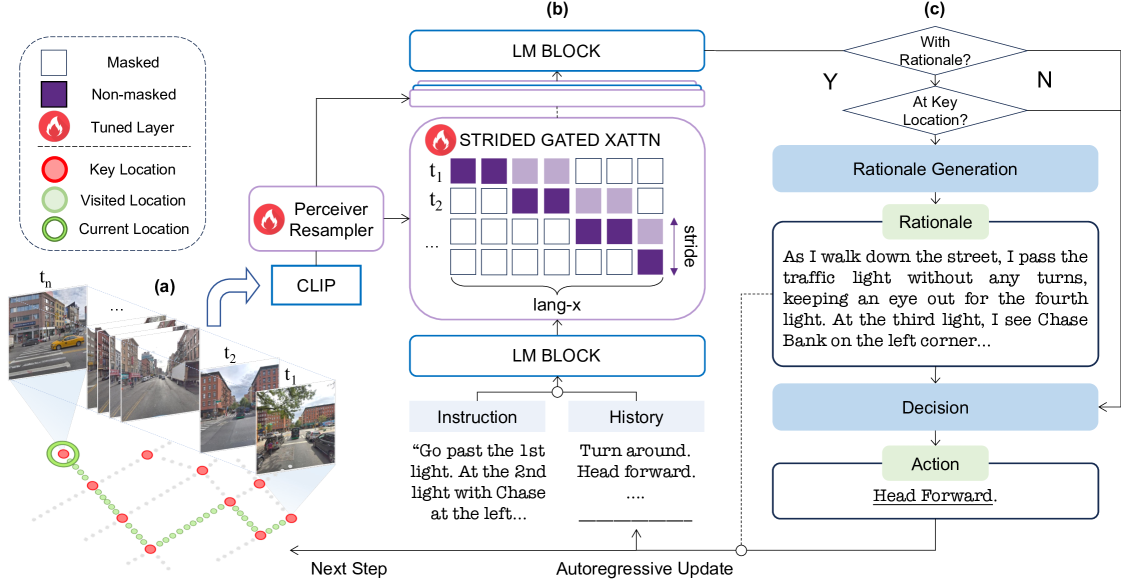
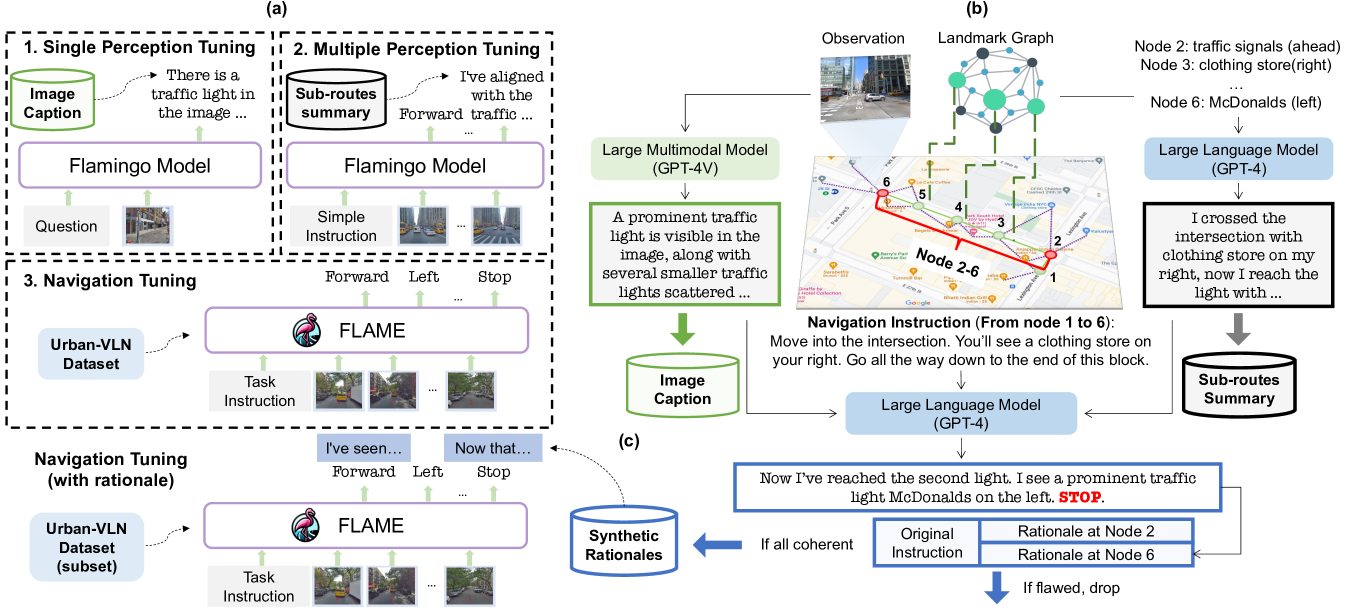
技术框架:FLAME的整体架构包含三个主要阶段:1) 单感知微调:利用街景图像和文本描述数据,训练MLLM理解单个图像的语义信息。2) 多感知微调:利用路线中的多个图像和对应的文本描述,训练MLLM进行路线总结和理解。3) 端到端训练:在VLN数据集上进行端到端训练,优化智能体的导航策略。整个流程通过自动合成增强数据集来提升模型的泛化能力。
关键创新:FLAME的关键创新在于其三阶段微调策略,该策略能够有效地将多模态LLM适配到城市VLN任务。与传统的端到端训练方法相比,这种分阶段的训练方式能够更好地利用LLM的先验知识,并逐步提升其在导航任务中的性能。此外,自动合成增强数据集也是一个重要的创新点,可以有效缓解数据稀缺问题。
关键设计:在单感知微调阶段,使用了街景图像和对应的文本描述数据,目标是让MLLM能够准确地描述图像内容。在多感知微调阶段,使用了路线中的多个图像和对应的文本描述,目标是让MLLM能够理解路线的整体语义信息。在端到端训练阶段,使用了VLN数据集,并设计了合适的损失函数来优化智能体的导航策略。具体的网络结构基于FLAMingo架构,并针对VLN任务进行了调整。
🖼️ 关键图片
📊 实验亮点
FLAME在Touchdown数据集上取得了显著的性能提升,任务完成度提高了7.3%,超过了现有最先进的方法。这一结果表明,多模态LLM在复杂导航任务中具有巨大的潜力。此外,FLAME的三阶段微调策略和自动合成增强数据集的方法也为其他研究者提供了有价值的参考。
🎯 应用场景
FLAME的研究成果可应用于自动驾驶、机器人导航、虚拟现实等领域。例如,可以利用该技术开发更智能的导航系统,帮助人们在复杂的城市环境中更轻松地找到目的地。此外,该技术还可以应用于机器人领域,使机器人能够在未知环境中自主导航和完成任务。未来,该研究有望推动具身智能的发展,使智能体能够更好地理解和适应真实世界。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated potential in Vision-and-Language Navigation (VLN) tasks, yet current applications face challenges. While LLMs excel in general conversation scenarios, they struggle with specialized navigation tasks, yielding suboptimal performance compared to specialized VLN models. We introduce FLAME (FLAMingo-Architected Embodied Agent), a novel Multimodal LLM-based agent and architecture designed for urban VLN tasks that efficiently handles multiple observations. Our approach implements a three-phase tuning technique for effective adaptation to navigation tasks, including single perception tuning for street view description, multiple perception tuning for route summarization, and end-to-end training on VLN datasets. The augmented datasets are synthesized automatically. Experimental results demonstrate FLAME's superiority over existing methods, surpassing state-of-the-art methods by a 7.3% increase in task completion on Touchdown dataset. This work showcases the potential of Multimodal LLMs (MLLMs) in complex navigation tasks, representing an advancement towards applications of MLLMs in the field of embodied intelligence.