OpenScan: A Benchmark for Generalized Open-Vocabulary 3D Scene Understanding
作者: Youjun Zhao, Jiaying Lin, Shuquan Ye, Qianshi Pang, Rynson W. H. Lau
分类: cs.CV
发布日期: 2024-08-20 (更新: 2025-11-24)
备注: Accepted by AAAI 2026. Project Page: https://youjunzhao.github.io/OpenScan/
💡 一句话要点
提出OpenScan基准,用于广义开放词汇3D场景理解
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇3D场景理解 广义开放词汇 3D场景理解 对象属性 OpenScan基准
📋 核心要点
- 现有OV-3D方法主要关注对象类别内的开放词汇,缺乏对场景整体理解的全面评估。
- 提出GOV-3D任务和OpenScan基准,利用细粒度属性的语言查询来探索更广泛的开放词汇知识。
- 实验表明现有OV-3D方法难以理解GOV-3D任务的抽象词汇,需要新的方法来解决。
📝 摘要(中文)
开放词汇3D场景理解(OV-3D)旨在定位和分类超出对象类别闭集的新对象。然而,现有的方法和基准主要关注对象类别范围内的开放词汇问题,这不足以全面评估模型对3D场景的理解程度。本文提出了一个更具挑战性的任务,称为广义开放词汇3D场景理解(GOV-3D),以探索超出对象类别的开放词汇问题。它包含一个开放且多样化的广义知识集合,表示为细粒度和特定于对象的属性的语言查询。为此,我们贡献了一个名为OpenScan的新基准,它由跨越八个代表性语言方面的3D对象属性组成,包括可供性、属性和材料。我们进一步在OpenScan基准上评估了最先进的OV-3D方法,并发现这些方法难以理解GOV-3D任务的抽象词汇,这是一个不能简单地通过在训练期间扩大对象类别来解决的挑战。我们强调了现有方法的局限性,并探索了克服已发现缺点的有希望的方向。
🔬 方法详解
问题定义:现有开放词汇3D场景理解方法主要集中在识别预定义的对象类别之外的新对象,而忽略了对场景中对象更细粒度的属性和关系的理解。这些方法无法回答诸如“哪个物体可以用来坐?”或“这个物体的材质是什么?”之类的问题,限制了其在复杂场景中的应用。
核心思路:本文的核心思路是将开放词汇3D场景理解扩展到更广义的知识范畴,即GOV-3D。通过引入细粒度的对象属性(如可供性、属性和材料)作为语言查询的目标,促使模型学习理解和推理场景中对象之间的复杂关系和属性。
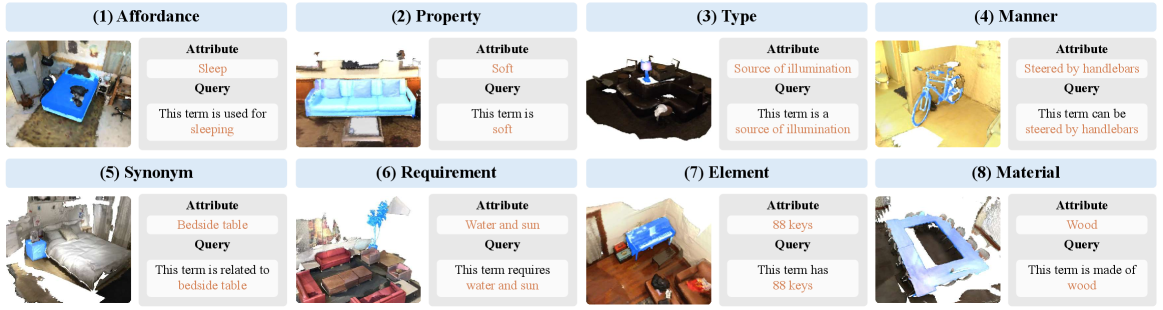
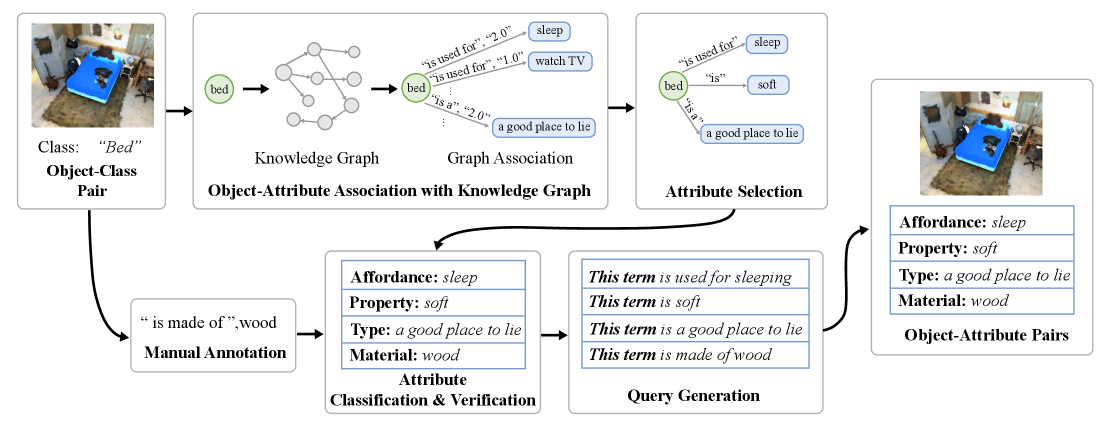
技术框架:OpenScan基准包含3D场景数据,以及与场景中对象相关的、涵盖八个语言方面的属性标注。这些属性包括可供性(affordance)、属性(property)、材料(material)等。研究人员可以使用OpenScan来训练和评估模型,使其能够根据给定的语言查询,定位并识别场景中具有特定属性的对象。
关键创新:该论文的关键创新在于提出了GOV-3D任务,它超越了传统的对象类别识别,关注于对场景中对象属性的细粒度理解。OpenScan基准的构建为评估和改进GOV-3D模型提供了数据基础。
关键设计:OpenScan基准的设计考虑了属性的多样性和代表性,涵盖了八个不同的语言方面,以确保模型能够学习到广泛的场景知识。基准的标注过程也经过精心设计,以保证标注的准确性和一致性。具体的损失函数和网络结构的选择取决于所使用的OV-3D模型,但通常需要针对GOV-3D任务进行调整,例如引入属性预测分支或使用更强大的语言编码器。
🖼️ 关键图片

📊 实验亮点
论文构建了OpenScan基准,包含八个语言方面的3D对象属性。实验结果表明,现有的OV-3D方法在OpenScan基准上表现不佳,表明这些方法难以理解抽象词汇和细粒度属性。这突出了现有方法在广义开放词汇场景理解方面的局限性,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、虚拟现实等领域。例如,机器人可以根据用户的自然语言指令,找到具有特定属性的物体,从而更好地完成任务。在智能家居中,系统可以理解用户的需求,并根据场景中的物体属性提供个性化服务。在虚拟现实中,用户可以与场景中的物体进行更自然的交互。
📄 摘要(原文)
Open-vocabulary 3D scene understanding (OV-3D) aims to localize and classify novel objects beyond the closed set of object classes. However, existing approaches and benchmarks primarily focus on the open vocabulary problem within the context of object classes, which is insufficient in providing a holistic evaluation to what extent a model understands the 3D scene. In this paper, we introduce a more challenging task called Generalized Open-Vocabulary 3D Scene Understanding (GOV-3D) to explore the open vocabulary problem beyond object classes. It encompasses an open and diverse set of generalized knowledge, expressed as linguistic queries of fine-grained and object-specific attributes. To this end, we contribute a new benchmark named \textit{OpenScan}, which consists of 3D object attributes across eight representative linguistic aspects, including affordance, property, and material. We further evaluate state-of-the-art OV-3D methods on our OpenScan benchmark and discover that these methods struggle to comprehend the abstract vocabularies of the GOV-3D task, a challenge that cannot be addressed simply by scaling up object classes during training. We highlight the limitations of existing methodologies and explore promising directions to overcome the identified shortcomings.