CrossFi: A Cross Domain Wi-Fi Sensing Framework Based on Siamese Network
作者: Zijian Zhao, Tingwei Chen, Zhijie Cai, Xiaoyang Li, Hang Li, Qimei Chen, Guangxu Zhu
分类: cs.CV, cs.AI, cs.LG, eess.SP
发布日期: 2024-08-20 (更新: 2025-02-14)
DOI: 10.1109/JIOT.2025.3542850
🔗 代码/项目: GITHUB
💡 一句话要点
提出CrossFi,一种基于孪生网络的跨域Wi-Fi感知框架,解决领域迁移问题。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: Wi-Fi感知 跨域学习 孪生网络 注意力机制 少样本学习
📋 核心要点
- 现有Wi-Fi感知方法受限于数据集规模,模型易过拟合训练集,泛化能力差,难以适应跨域场景。
- CrossFi基于孪生网络,通过CSi-Net计算样本相似度,并利用Weight-Net生成类模板,提升跨域泛化能力。
- 实验表明,CrossFi在手势识别任务中,跨域少样本和零样本场景下均取得SOTA性能,显著提升泛化能力。
📝 摘要(中文)
近年来,Wi-Fi感知因其隐私保护、低成本和穿透能力等优点而备受关注。该领域已进行了广泛的研究,重点关注手势识别、人员识别和跌倒检测等领域。然而,许多数据驱动的方法都面临着与领域迁移相关的挑战,即模型在与训练数据不同的环境中表现不佳。造成这个问题的一个主要因素是Wi-Fi感知数据集的可用性有限,这使得模型学习了过多的无关信息并过度拟合训练集。不幸的是,跨不同场景收集大规模Wi-Fi感知数据集是一项具有挑战性的任务。为了解决这个问题,我们提出了一种基于孪生网络的CrossFi方法,该方法在域内和跨域场景(包括少样本、零样本场景,甚至是在测试集包含新类别的少样本新类场景)中都表现出色。CrossFi的核心组件是一个名为CSi-Net的样本相似度计算网络,它通过使用注意力机制来捕获相似度信息,而不是简单地计算距离或余弦相似度,从而改进了孪生网络的结构。在此基础上,我们开发了一个额外的Weight-Net,它可以为每个类生成一个模板,以便我们的CrossFi可以在不同的场景中工作。实验结果表明,我们的CrossFi在各种场景中都取得了最先进的性能。在手势识别任务中,我们的CrossFi在域内场景中实现了98.17%的准确率,在单样本跨域场景中实现了91.72%的准确率,在零样本跨域场景中实现了64.81%的准确率,在单样本新类场景中实现了84.75%的准确率。我们的模型代码已在https://github.com/RS2002/CrossFi上公开。
🔬 方法详解
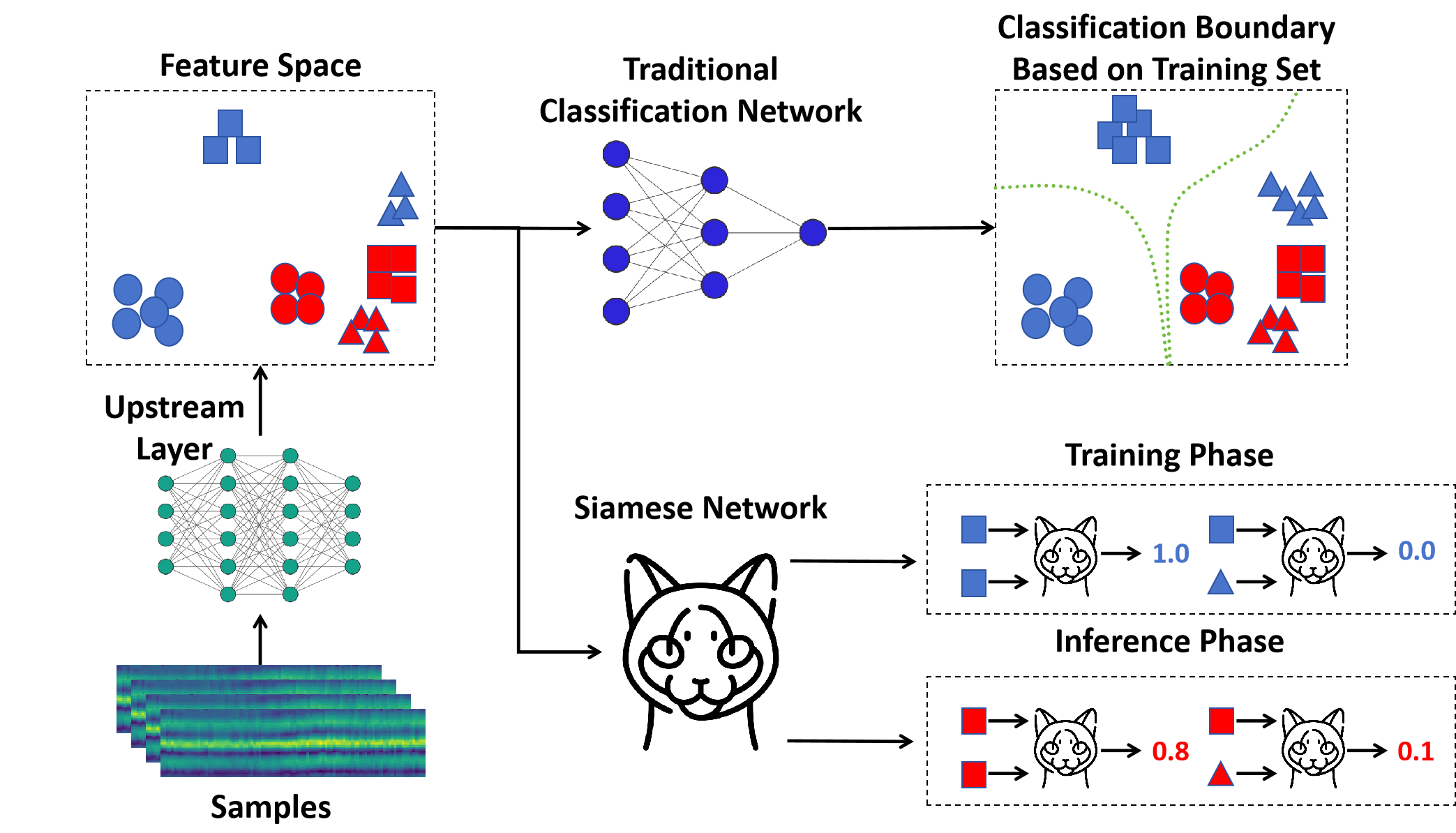
问题定义:Wi-Fi感知技术在实际应用中面临严重的领域迁移问题。由于不同环境的Wi-Fi信号特征差异较大,导致在特定环境下训练的模型在其他环境中性能显著下降。现有方法难以有效利用有限的数据集,容易过拟合,缺乏跨域泛化能力。
核心思路:CrossFi的核心思路是学习样本之间的相似性,而不是直接学习样本的类别。通过孪生网络结构,将样本映射到特征空间,并计算特征之间的相似度。此外,引入Weight-Net生成类模板,用于表示每个类别的典型特征,从而实现跨域泛化。这种方法能够有效减少对特定环境的依赖,提高模型在不同场景下的适应性。
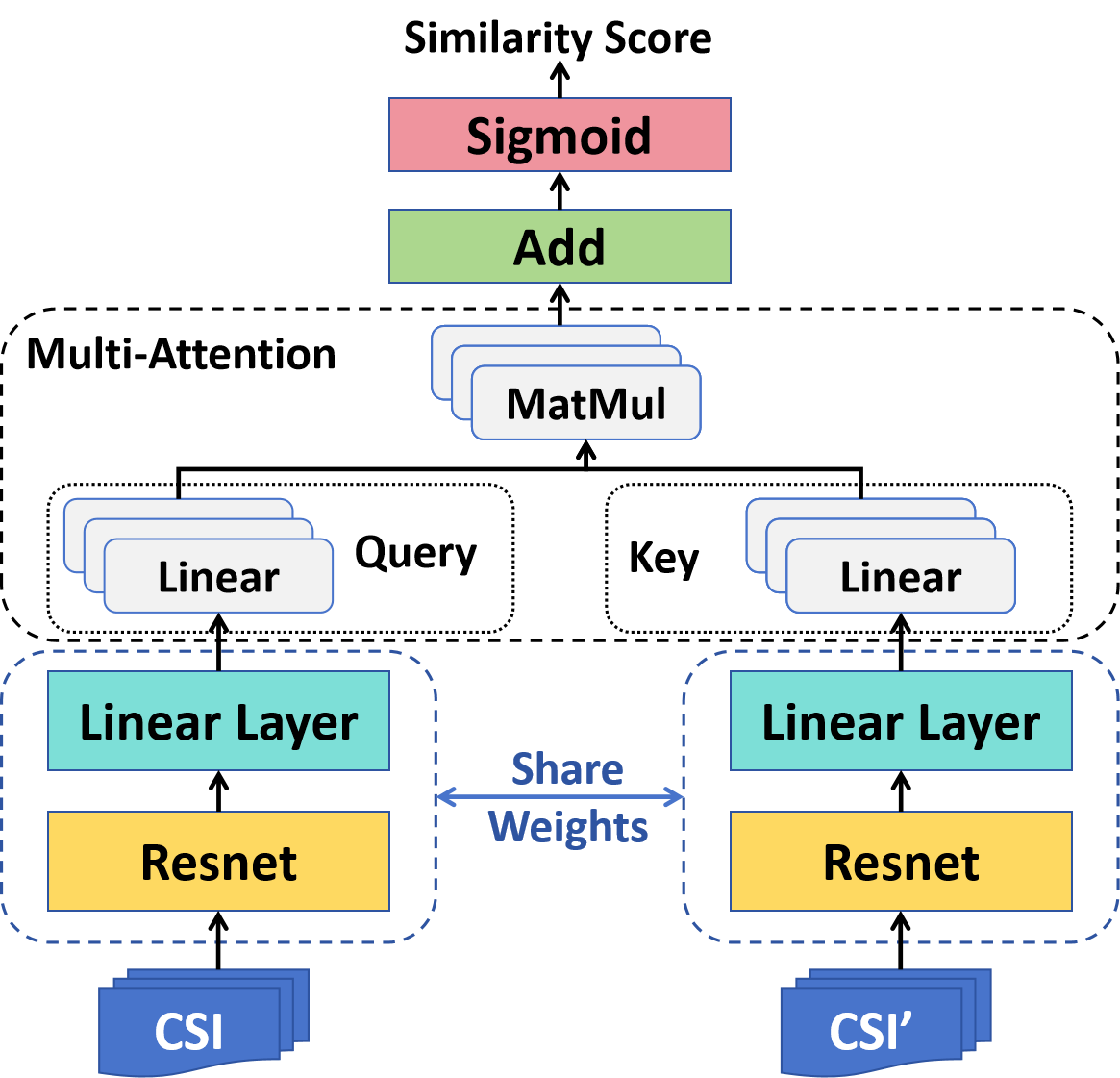
技术框架:CrossFi的整体框架包含两个主要模块:CSi-Net和Weight-Net。CSi-Net是一个基于孪生网络的样本相似度计算网络,用于提取样本的特征并计算相似度。Weight-Net用于生成每个类别的模板,该模板代表了该类别的典型特征。在训练阶段,CSi-Net学习样本之间的相似度关系,Weight-Net学习如何生成能够代表每个类别的模板。在测试阶段,将测试样本与各个类别的模板进行比较,选择相似度最高的类别作为预测结果。
关键创新:CrossFi的关键创新在于CSi-Net和Weight-Net的结合。CSi-Net通过注意力机制改进了传统的孪生网络,能够更有效地捕获样本之间的相似度信息。Weight-Net的引入使得模型能够学习到每个类别的典型特征,从而实现跨域泛化。与现有方法相比,CrossFi不需要大量的标注数据,能够在少样本和零样本场景下取得良好的性能。
关键设计:CSi-Net使用注意力机制来计算样本之间的相似度,具体来说,它首先将样本映射到特征空间,然后使用注意力机制来关注特征中最重要的部分,最后计算加权特征之间的相似度。Weight-Net使用一个简单的神经网络来生成类模板,该网络的输入是类别的标签,输出是类模板。损失函数包括相似度损失和分类损失,相似度损失用于约束CSi-Net学习样本之间的相似度关系,分类损失用于约束Weight-Net生成能够代表每个类别的模板。
🖼️ 关键图片

📊 实验亮点
CrossFi在手势识别任务中取得了显著的性能提升。在域内场景中,CrossFi的准确率达到了98.17%。在跨域场景中,CrossFi在单样本学习场景下达到了91.72%的准确率,在零样本学习场景下达到了64.81%的准确率,在单样本新类场景下达到了84.75%的准确率。这些结果表明,CrossFi在跨域泛化方面具有显著优势,能够有效解决领域迁移问题。
🎯 应用场景
CrossFi在智能家居、智慧医疗、安全监控等领域具有广泛的应用前景。例如,可以用于实现无需穿戴设备的手势控制、跌倒检测、人员身份识别等功能。该研究成果有助于推动Wi-Fi感知技术在实际场景中的应用,提升用户体验和生活质量。未来,CrossFi可以进一步扩展到其他感知任务,例如人体姿态估计、行为识别等。
📄 摘要(原文)
In recent years, Wi-Fi sensing has garnered significant attention due to its numerous benefits, such as privacy protection, low cost, and penetration ability. Extensive research has been conducted in this field, focusing on areas such as gesture recognition, people identification, and fall detection. However, many data-driven methods encounter challenges related to domain shift, where the model fails to perform well in environments different from the training data. One major factor contributing to this issue is the limited availability of Wi-Fi sensing datasets, which makes models learn excessive irrelevant information and over-fit to the training set. Unfortunately, collecting large-scale Wi-Fi sensing datasets across diverse scenarios is a challenging task. To address this problem, we propose CrossFi, a siamese network-based approach that excels in both in-domain scenario and cross-domain scenario, including few-shot, zero-shot scenarios, and even works in few-shot new-class scenario where testing set contains new categories. The core component of CrossFi is a sample-similarity calculation network called CSi-Net, which improves the structure of the siamese network by using an attention mechanism to capture similarity information, instead of simply calculating the distance or cosine similarity. Based on it, we develop an extra Weight-Net that can generate a template for each class, so that our CrossFi can work in different scenarios. Experimental results demonstrate that our CrossFi achieves state-of-the-art performance across various scenarios. In gesture recognition task, our CrossFi achieves an accuracy of 98.17% in in-domain scenario, 91.72% in one-shot cross-domain scenario, 64.81% in zero-shot cross-domain scenario, and 84.75% in one-shot new-class scenario. The code for our model is publicly available at https://github.com/RS2002/CrossFi.