Event Stream-based Sign Language Translation: A High-Definition Benchmark Dataset and A Novel Baseline
作者: Shiao Wang, Xiao Wang, Duoqing Yang, Yao Rong, Fuling Wang, Jianing Li, Lin Zhu, Bo Jiang
分类: cs.CV, cs.AI, cs.CL, cs.NE
发布日期: 2024-08-20 (更新: 2025-11-27)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Event-CSL事件流手语翻译数据集和EvSLT基线模型,解决光照和隐私问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 手语翻译 事件相机 事件流 Mamba架构 时空融合 Event-CSL数据集 EvSLT框架
📋 核心要点
- 传统手语翻译方法依赖可见光视频,易受光照、快速运动和隐私泄露影响。
- 提出EvSLT框架,利用事件相机数据,结合Mamba记忆聚合和图引导时空融合。
- 构建Event-CSL数据集,包含多种场景和条件,实验证明EvSLT性能优于现有方法。
📝 摘要(中文)
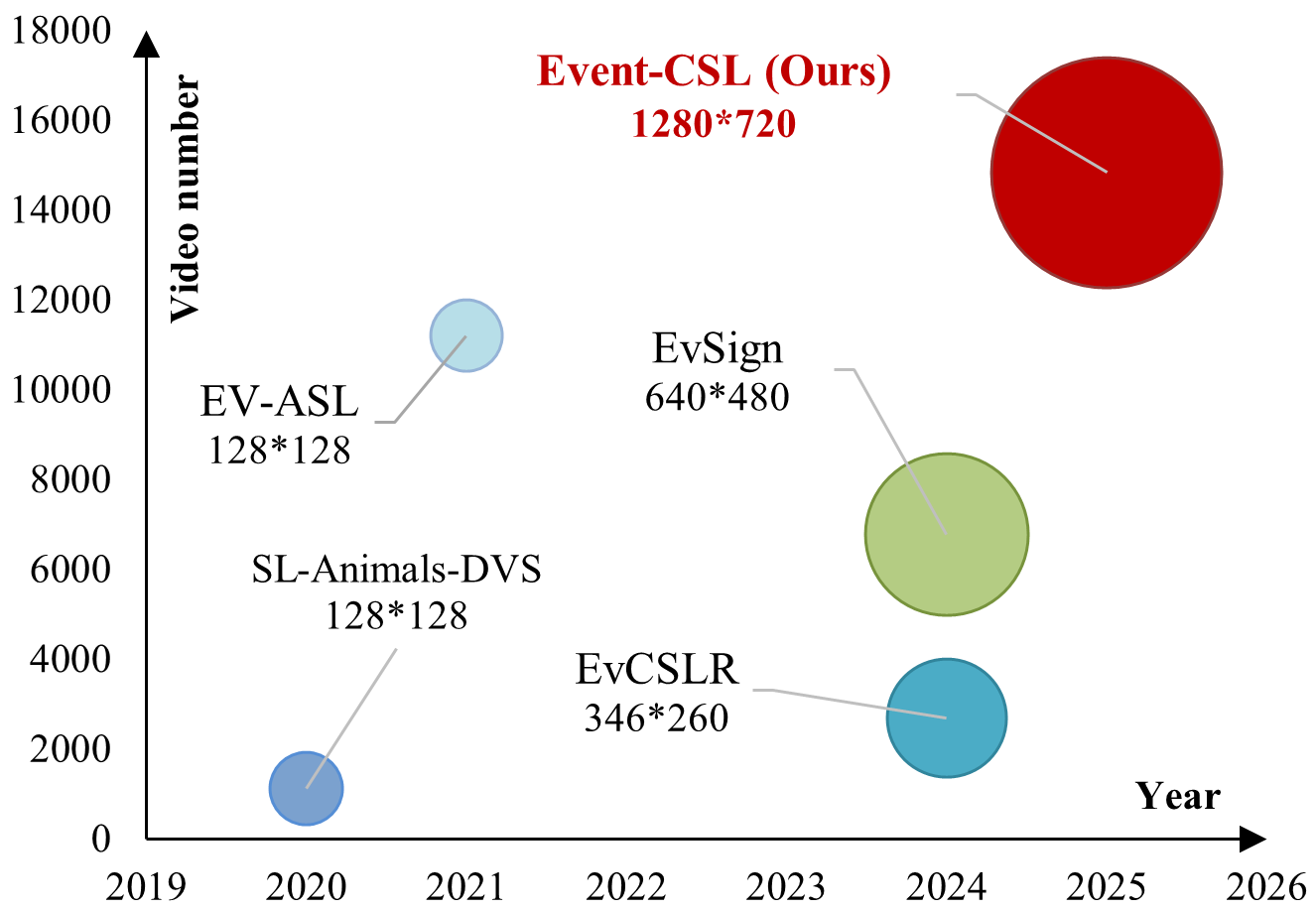
本文针对传统基于可见光视频的手语翻译(SLT)方法易受光照变化、快速手部运动和隐私问题影响的缺点,提出使用仿生事件相机。为此,我们构建了一个新的高清晰度事件流手语数据集Event-CSL,有效缓解了该领域的数据稀缺问题。该数据集包含14827个视频,14821个手语词汇,以及文本词汇表中2544个中文词语。样本采集于不同的室内外场景,覆盖多个视角、光照条件和相机运动。我们还在该数据集上对现有的主流SLT方法进行了基准测试,以促进未来研究的公平比较。此外,我们提出了一个名为EvSLT的新的基于事件的手语翻译框架。该框架首先将连续视频特征分割成片段,并采用基于Mamba的记忆聚合模块来压缩和聚合片段级别的空间细节特征。随后,这些空间特征与来自时间卷积的时间表示通过图引导的时空融合模块进行融合。在Event-CSL以及其他公开数据集上的大量实验表明,我们的方法具有优越的性能。数据集和源代码将在https://github.com/Event-AHU/OpenESL上发布。
🔬 方法详解
问题定义:传统手语翻译方法依赖于可见光视频,容易受到光照变化、快速手部运动以及潜在的隐私泄露等因素的影响。这些因素会降低翻译的准确性和鲁棒性。现有方法难以有效处理这些问题,尤其是在复杂或受限的环境中。
核心思路:本文的核心思路是利用事件相机捕获的事件流数据来替代传统的可见光视频。事件相机对光照变化不敏感,能够捕捉快速运动,并且由于其数据形式的特殊性,在一定程度上保护了隐私。EvSLT框架旨在有效地处理和利用事件流数据进行手语翻译。
技术框架:EvSLT框架主要包含以下几个阶段:1) 视频特征分割:将连续的事件流视频分割成多个片段。2) 基于Mamba的记忆聚合:使用Mamba模块压缩和聚合每个片段的空间细节特征,Mamba架构擅长处理序列数据,能够有效捕捉事件流中的时空依赖关系。3) 时空特征融合:通过图引导的时空融合模块,将空间特征与时间卷积提取的时间表示进行融合,从而获得更全面的时空信息。
关键创新:该方法最重要的创新点在于将事件相机和Mamba架构引入手语翻译领域。事件相机的使用解决了传统方法对光照敏感的问题,而Mamba架构则能够有效地处理事件流数据中的时空依赖关系。此外,图引导的时空融合模块能够更好地整合空间和时间信息,从而提高翻译的准确性。
关键设计:在Mamba模块中,采用了特定的参数设置来优化记忆聚合的效果。时间卷积层可能采用了不同的卷积核大小和数量,以捕捉不同时间尺度的信息。图引导的时空融合模块可能使用了特定的图结构和融合策略,以更好地整合空间和时间特征。具体的损失函数选择和训练策略未知,需要在代码中进一步分析。
🖼️ 关键图片


📊 实验亮点
论文构建了大规模高清晰度事件流手语数据集Event-CSL,并提出了EvSLT基线模型。实验结果表明,EvSLT在Event-CSL数据集以及其他公开数据集上均取得了优越的性能,证明了事件相机和Mamba架构在手语翻译任务中的有效性。具体的性能提升幅度未知,需要在论文中查找详细的实验数据。
🎯 应用场景
该研究成果可应用于AI辅助残疾人领域,例如开发实时手语翻译系统,帮助听力障碍人士与健听人进行无障碍交流。此外,该技术还可应用于智能监控、人机交互等领域,尤其是在光照条件不佳或需要保护隐私的场景下具有重要价值。未来,该研究有望推动手语翻译技术的普及和应用,提升残疾人的生活质量。
📄 摘要(原文)
Sign Language Translation (SLT) is a core task in the field of AI-assisted disability. Traditional SLT methods are typically based on visible light videos, which are easily affected by factors such as lighting variations, rapid hand movements, and privacy concerns. This paper proposes the use of bio-inspired event cameras to alleviate the aforementioned issues. Specifically, we introduce a new high-definition event-based sign language dataset, termed Event-CSL, which effectively addresses the data scarcity in this research area. The dataset comprises 14,827 videos, 14,821 glosses, and 2,544 Chinese words in the text vocabulary. These samples are collected across diverse indoor and outdoor scenes, covering multiple viewpoints, lighting conditions, and camera motions. We have also benchmarked existing mainstream SLT methods on this dataset to facilitate fair comparisons in future research.Furthermore, we propose a novel event-based sign language translation framework, termed EvSLT. The framework first segments continuous video features into clips and employs a Mamba-based memory aggregation module to compress and aggregate spatial detail features at the clip level. Subsequently, these spatial features, along with temporal representations obtained from temporal convolution, are then fused by a graph-guided spatiotemporal fusion module. Extensive experiments on Event-CSL, as well as other publicly available datasets, demonstrate the superior performance of our method. The dataset and source code will be released on https://github.com/Event-AHU/OpenESL