CoVLA: Comprehensive Vision-Language-Action Dataset for Autonomous Driving
作者: Hidehisa Arai, Keita Miwa, Kento Sasaki, Yu Yamaguchi, Kohei Watanabe, Shunsuke Aoki, Issei Yamamoto
分类: cs.CV
发布日期: 2024-08-19 (更新: 2025-10-14)
备注: WACV 2025, Project Page: https://turingmotors.github.io/covla-ad/
💡 一句话要点
提出CoVLA数据集,用于训练自动驾驶中具备视觉-语言-动作能力的模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 视觉-语言-动作模型 多模态学习 数据集 端到端路径规划
📋 核心要点
- 自动驾驶需要复杂的推理和规划能力,但缺乏大规模的视觉、语言和动作数据集限制了多模态大语言模型在端到端路径规划中的应用。
- CoVLA数据集通过自动数据处理和字幕生成流程,生成包含驾驶轨迹和自然语言描述的大规模真实驾驶数据。
- 实验结果表明,使用CoVLA训练的模型能够生成连贯的语言和动作输出,验证了视觉-语言-动作模型在自动驾驶中的潜力。
📝 摘要(中文)
本文提出了一个名为CoVLA(Comprehensive Vision-Language-Action)的综合性数据集,旨在解决自动驾驶领域中,特别是复杂和突发场景下,对具备推理和规划能力的多模态大型语言模型(MLLM)的需求。由于缺乏包含视觉、语言和动作的大规模标注数据集,MLLM在端到端路径规划中的应用受到限制。CoVLA数据集包含超过80小时的真实驾驶视频,利用自动数据处理和字幕生成流程,生成精确的驾驶轨迹,并配以详细的驾驶环境和操作的自然语言描述。该数据集规模和标注丰富度超越了现有数据集。研究结果表明,使用CoVLA训练的模型在生成连贯的语言和动作输出方面表现出色,证明了视觉-语言-动作(VLA)模型在自动驾驶领域的潜力。该数据集为训练和评估VLA模型提供了一个全面的平台,有助于构建更安全、更可靠的自动驾驶系统。
🔬 方法详解
问题定义:现有自动驾驶研究,特别是端到端路径规划,面临缺乏大规模、高质量的视觉-语言-动作(VLA)数据集的挑战。现有数据集规模有限,标注信息不够丰富,难以有效训练和评估具备复杂推理和规划能力的VLA模型。这阻碍了MLLM在自动驾驶领域的更广泛应用。
核心思路:本文的核心思路是构建一个大规模、高质量的CoVLA数据集,该数据集包含真实驾驶场景的视频、详细的自然语言描述以及精确的驾驶动作。通过自动化数据处理和字幕生成流程,降低数据标注成本,提高数据规模和标注质量,从而为VLA模型的训练和评估提供充足的数据支持。
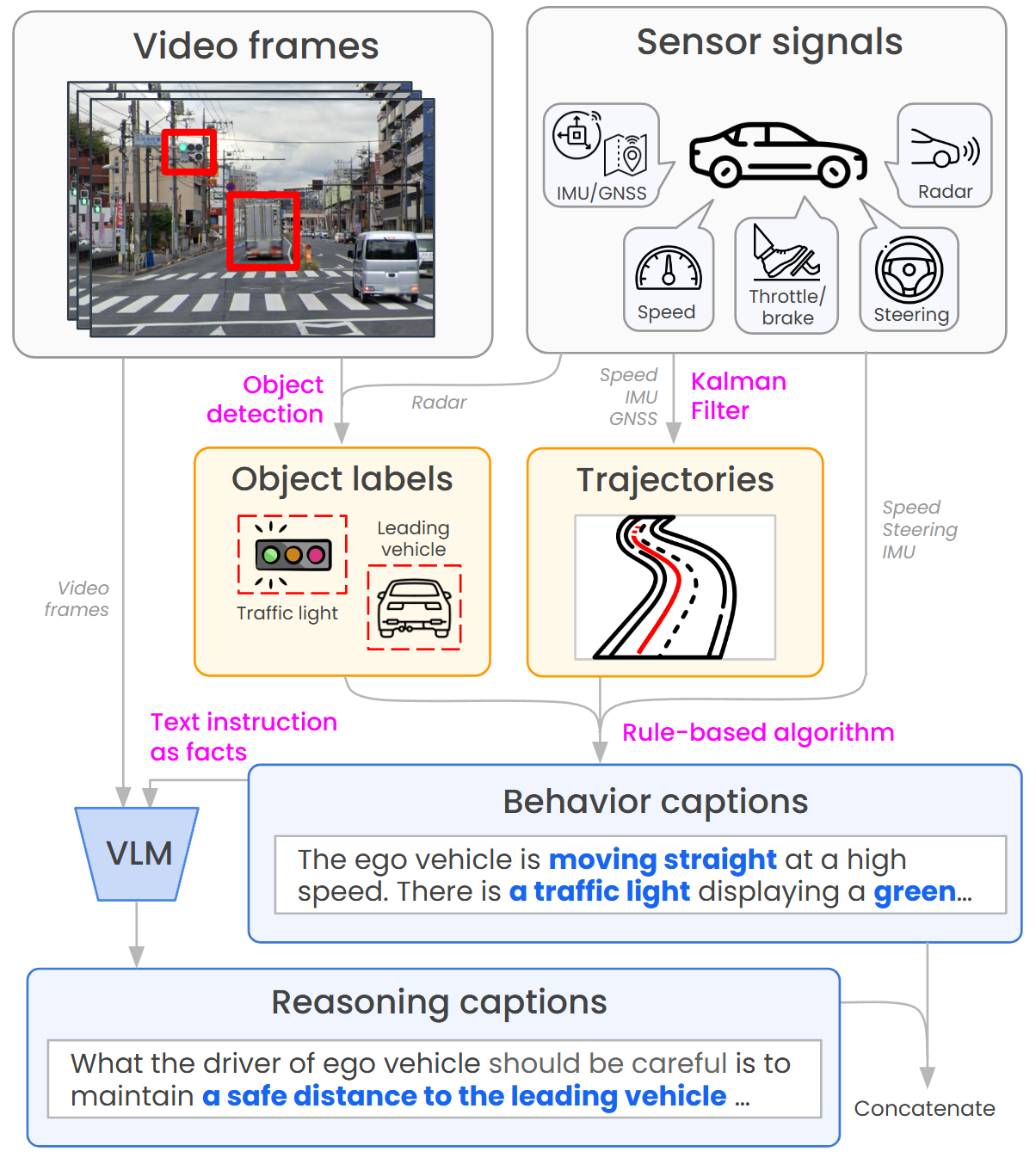
技术框架:CoVLA数据集的构建主要包含以下几个阶段:1) 数据采集:利用车载传感器记录真实驾驶视频数据。2) 自动化数据处理:对原始传感器数据进行处理,提取驾驶轨迹等信息。3) 字幕生成:利用自然语言生成技术,为每个驾驶场景生成详细的自然语言描述。4) 数据集整合:将视频、驾驶轨迹和自然语言描述整合到CoVLA数据集中。
关键创新:CoVLA数据集的关键创新在于其大规模和高质量的标注。通过自动化数据处理和字幕生成流程,实现了低成本、高效率的数据标注。此外,CoVLA数据集包含了丰富的驾驶场景和驾驶动作,能够有效训练和评估VLA模型在复杂驾驶环境下的表现。
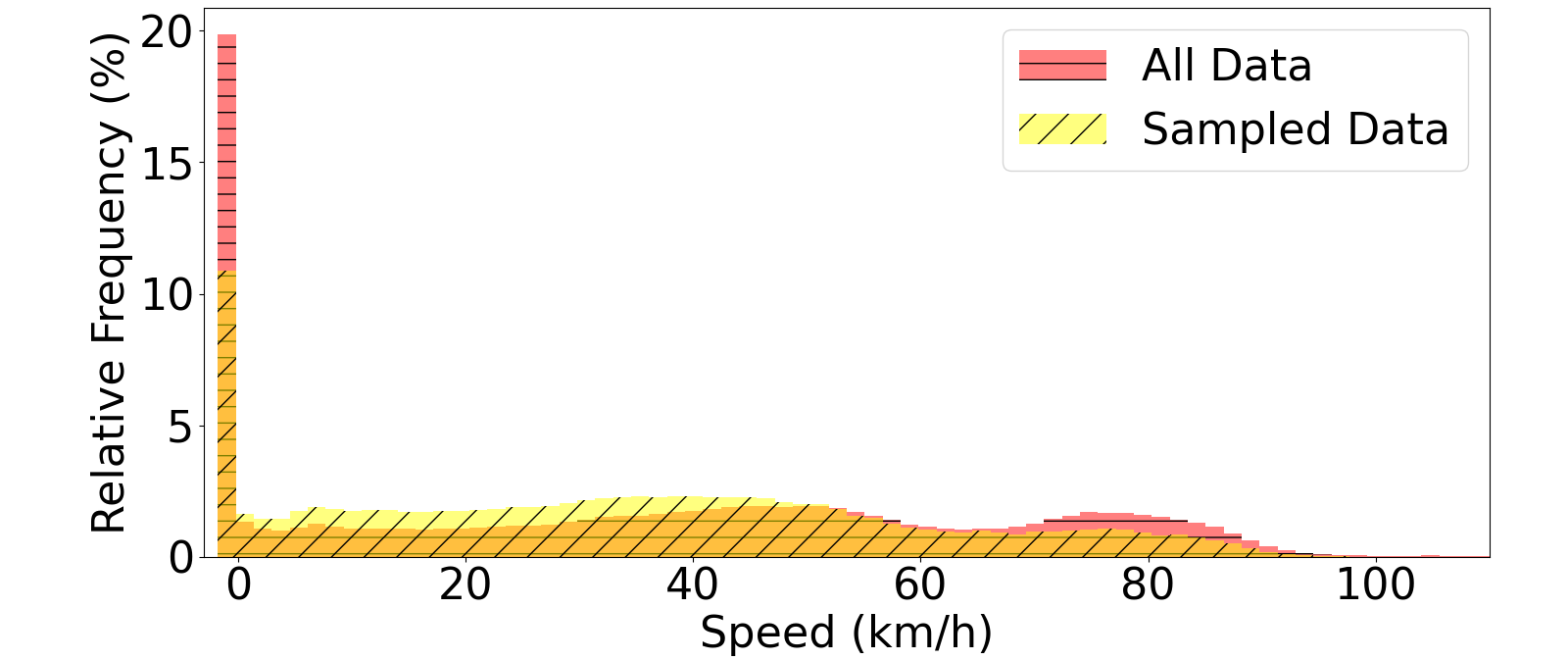
关键设计:字幕生成流程是CoVLA数据集构建的关键环节。具体的技术细节未知,但可以推测可能使用了预训练的语言模型,并结合驾驶场景的视觉信息和驾驶轨迹信息,生成准确、流畅的自然语言描述。数据集规模超过80小时,保证了模型训练的充分性。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了使用CoVLA数据集训练的VLA模型在生成连贯的语言和动作输出方面的强大能力。虽然没有提供具体的性能指标,但强调了模型在各种驾驶场景下的出色表现,证明了CoVLA数据集在推动VLA模型发展方面的潜力。
🎯 应用场景
CoVLA数据集可用于训练和评估自动驾驶系统中的视觉-语言-动作模型,提高自动驾驶车辆在复杂和突发场景下的决策能力和安全性。该数据集还可应用于人机交互、驾驶员行为分析等领域,为智能交通系统的发展提供数据支持。
📄 摘要(原文)
Autonomous driving, particularly navigating complex and unanticipated scenarios, demands sophisticated reasoning and planning capabilities. While Multi-modal Large Language Models (MLLMs) offer a promising avenue for this, their use has been largely confined to understanding complex environmental contexts or generating high-level driving commands, with few studies extending their application to end-to-end path planning. A major research bottleneck is the lack of large-scale annotated datasets encompassing vision, language, and action. To address this issue, we propose CoVLA (Comprehensive Vision-Language-Action) Dataset, an extensive dataset comprising real-world driving videos spanning more than 80 hours. This dataset leverages a novel, scalable approach based on automated data processing and a caption generation pipeline to generate accurate driving trajectories paired with detailed natural language descriptions of driving environments and maneuvers. This approach utilizes raw in-vehicle sensor data, allowing it to surpass existing datasets in scale and annotation richness. Using CoVLA, we investigate the driving capabilities of MLLMs that can handle vision, language, and action in a variety of driving scenarios. Our results illustrate the strong proficiency of our model in generating coherent language and action outputs, emphasizing the potential of Vision-Language-Action (VLA) models in the field of autonomous driving. This dataset establishes a framework for robust, interpretable, and data-driven autonomous driving systems by providing a comprehensive platform for training and evaluating VLA models, contributing to safer and more reliable self-driving vehicles. The dataset is released for academic purpose.