SHARP: Segmentation of Hands and Arms by Range using Pseudo-Depth for Enhanced Egocentric 3D Hand Pose Estimation and Action Recognition
作者: Wiktor Mucha, Michael Wray, Martin Kampel
分类: cs.CV
发布日期: 2024-08-19
备注: Accepted at 27th International Conference on Pattern Recognition (ICPR)
💡 一句话要点
SHARP:利用伪深度分割手部和手臂,提升以自我为中心的3D手势估计和动作识别。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 3D手势估计 动作识别 伪深度 单目深度估计 Transformer网络 以自我为中心视觉 手部分割
📋 核心要点
- 以自我为中心的视角下,手势姿态是动作识别的关键信息,但现有方法在复杂场景中精度不足。
- 该方法利用单RGB图像深度估计生成伪深度图,并以此分割手部和手臂,减少背景干扰。
- 实验表明,该方法在H2O数据集上实现了91.73%的动作识别准确率,优于现有技术,且手势估计误差为28.66mm。
📝 摘要(中文)
本文提出了一种通过伪深度图像来改进以自我为中心的3D手势估计的方法,该方法仅基于RGB图像。通过结合最先进的单RGB图像深度估计技术,我们生成帧的伪深度表示,并利用距离信息来分割场景中不相关的部分。生成的深度图被用作RGB帧的分割掩码。在H2O数据集上的实验结果证实了我们的方法在动作识别任务中估计姿势的高精度。3D手势姿势与来自对象检测的信息一起,由基于Transformer的动作识别网络处理,从而达到91.73%的准确率,优于所有最先进的方法。3D手势姿势的估计结果与现有方法相比具有竞争力的性能,平均姿势误差为28.66毫米。该方法为在以自我为中心的3D手势估计中利用距离信息开辟了新的可能性,而无需依赖深度传感器。
🔬 方法详解
问题定义:现有以自我为中心的3D手势估计方法,在仅使用RGB图像时,容易受到复杂背景的干扰,导致手势姿态估计精度下降,进而影响动作识别的准确性。缺乏有效的手段来区分手部和场景中其他物体,是现有方法的痛点。
核心思路:论文的核心思路是利用单目深度估计技术,从RGB图像中生成伪深度图,并利用深度信息作为先验知识,对图像进行分割,从而提取出手部和手臂的区域。通过减少背景干扰,提高后续手势姿态估计的准确性。
技术框架:该方法主要包含以下几个阶段:1) 使用单目深度估计模型(具体模型未明确说明,属于state-of-the-art技术)从RGB图像中生成伪深度图;2) 基于伪深度图,设定距离阈值,分割出手部和手臂的区域,生成分割掩码;3) 将分割掩码应用于原始RGB图像,提取出手部和手臂的图像区域;4) 使用手势姿态估计模型(具体模型未明确说明)估计3D手势姿态;5) 将3D手势姿态和物体检测信息输入到基于Transformer的动作识别网络中进行动作识别。
关键创新:该方法最重要的创新点在于将伪深度信息引入到以自我为中心的3D手势估计中,并将其用于手部和手臂的分割。与传统方法直接在原始RGB图像上进行手势姿态估计相比,该方法能够有效减少背景干扰,提高手势姿态估计的准确性。本质区别在于利用了深度信息作为先验知识,辅助手势分割。
关键设计:论文中关于深度估计模型的选择、距离阈值的设定、手势姿态估计模型的选择以及Transformer网络结构的具体参数设置等关键设计细节并未详细描述。距离阈值的选择可能需要根据具体场景和数据集进行调整。损失函数和网络结构等细节未知。
🖼️ 关键图片
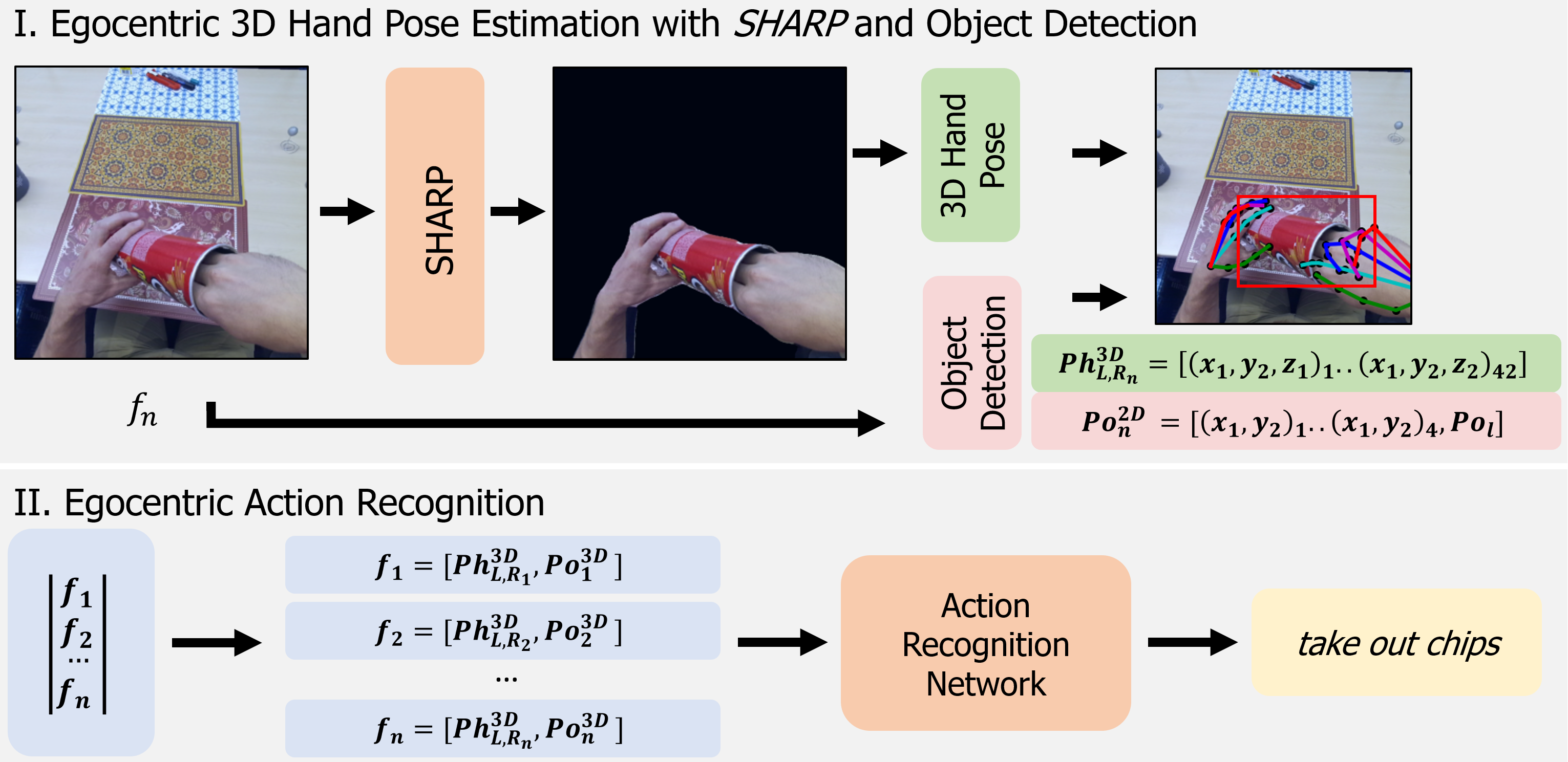


📊 实验亮点
该方法在H2O数据集上取得了显著的成果。在动作识别任务中,该方法达到了91.73%的准确率,超越了当前最先进的方法。同时,3D手势姿态估计的平均姿势误差为28.66毫米,与现有方法相比具有竞争力。这些结果表明,利用伪深度信息进行手部和手臂分割能够有效提升以自我为中心的3D手势估计和动作识别的性能。
🎯 应用场景
该研究成果可应用于人机交互、虚拟现实/增强现实、机器人控制等领域。例如,在VR/AR游戏中,可以更准确地识别用户的手势,从而实现更自然、更流畅的交互体验。在机器人控制中,可以帮助机器人更好地理解人类的意图,从而实现更安全、更高效的协作。未来,该技术有望进一步发展,实现更复杂、更精细的手势识别和动作理解。
📄 摘要(原文)
Hand pose represents key information for action recognition in the egocentric perspective, where the user is interacting with objects. We propose to improve egocentric 3D hand pose estimation based on RGB frames only by using pseudo-depth images. Incorporating state-of-the-art single RGB image depth estimation techniques, we generate pseudo-depth representations of the frames and use distance knowledge to segment irrelevant parts of the scene. The resulting depth maps are then used as segmentation masks for the RGB frames. Experimental results on H2O Dataset confirm the high accuracy of the estimated pose with our method in an action recognition task. The 3D hand pose, together with information from object detection, is processed by a transformer-based action recognition network, resulting in an accuracy of 91.73%, outperforming all state-of-the-art methods. Estimations of 3D hand pose result in competitive performance with existing methods with a mean pose error of 28.66 mm. This method opens up new possibilities for employing distance information in egocentric 3D hand pose estimation without relying on depth sensors.