VrdONE: One-stage Video Visual Relation Detection
作者: Xinjie Jiang, Chenxi Zheng, Xuemiao Xu, Bangzhen Liu, Weiying Zheng, Huaidong Zhang, Shengfeng He
分类: cs.CV
发布日期: 2024-08-18 (更新: 2024-10-16)
备注: 12 pages, 8 figures, accepted by ACM Multimedia 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出VrdONE单阶段模型,解决视频视觉关系检测中时空关系建模难题。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视频视觉关系检测 单阶段模型 时空关系建模 实例分割 视频理解
📋 核心要点
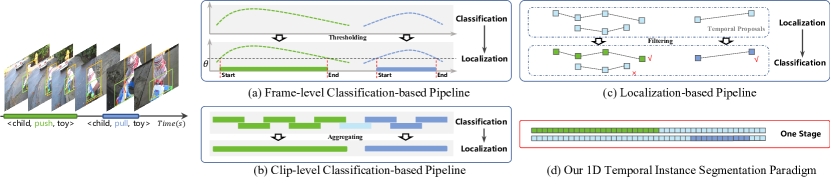
- 传统VidVRD方法将关系类别识别和时间边界确定分离,忽略了二者联系,限制了模型性能。
- VrdONE将谓词检测转化为组合特征上的1D实例分割,单阶段完成关系识别和时间定位。
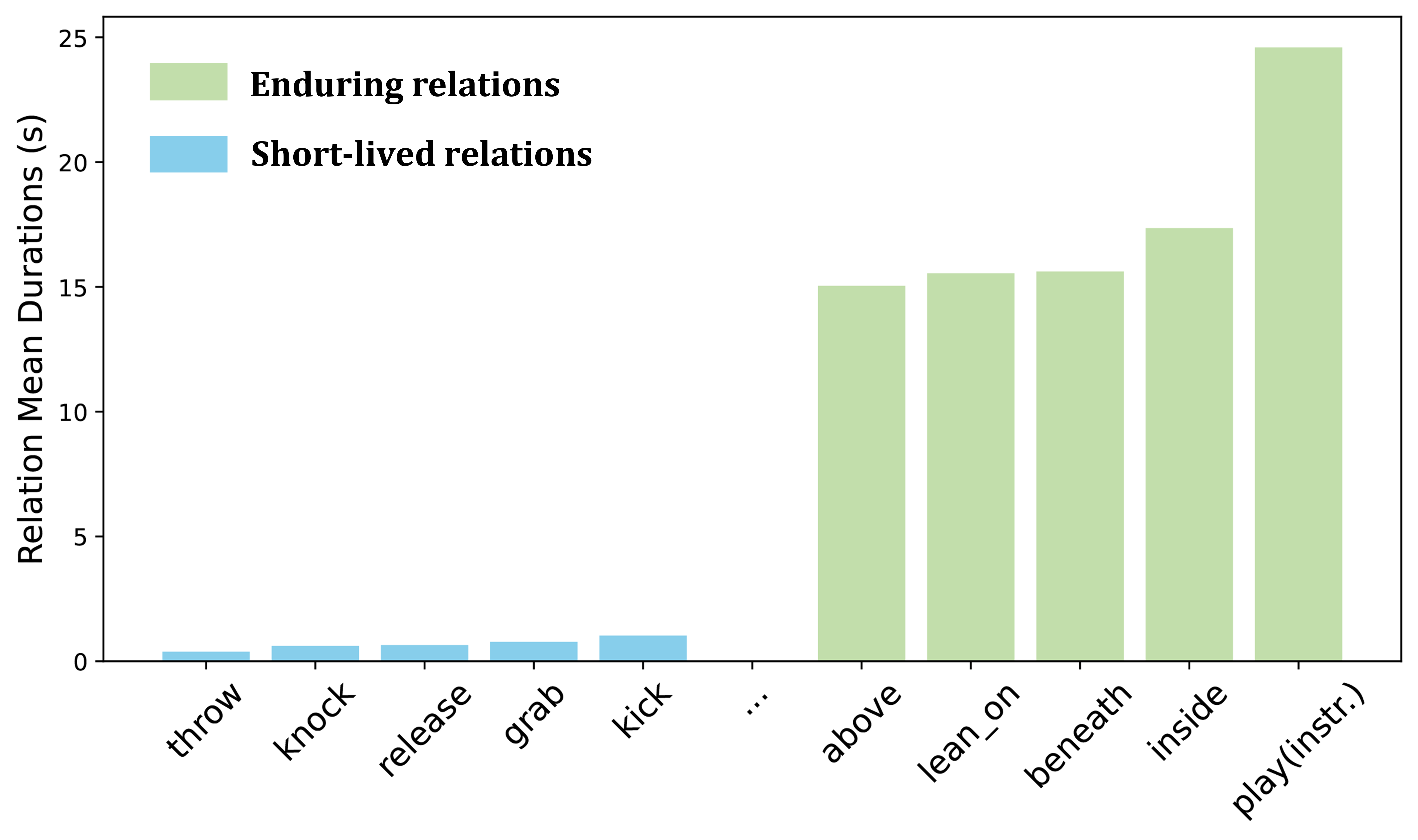
- VrdONE通过跨帧特征交互和SOS模块,有效提升了模型对不同时间尺度关系的识别能力。
📝 摘要(中文)
视频视觉关系检测(VidVRD)旨在理解视频中实体随时间和空间的交互方式,这是深入理解视频场景的关键一步。传统VidVRD方法通常将任务分解为关系类别识别和时间边界确定两个部分,忽略了它们之间的内在联系。为了识别实体对在不同时间跨度上的时空交互,我们提出了VrdONE,一个精简而有效的单阶段模型。VrdONE结合了主体和客体的特征,将谓词检测转化为其组合表示上的1D实例分割,从而一次性完成关系类别识别和二值掩码生成,无需额外的提议生成或后处理步骤。VrdONE促进了跨帧特征的交互,能够很好地捕捉短暂和持久的关系。此外,我们引入了主体-客体协同(SOS)模块,以增强主体和客体在组合前的相互感知。VrdONE在VidOR和ImageNet-VidVRD基准测试上取得了最先进的性能,展示了其在识别不同时间尺度关系方面的卓越能力。代码已开源。
🔬 方法详解
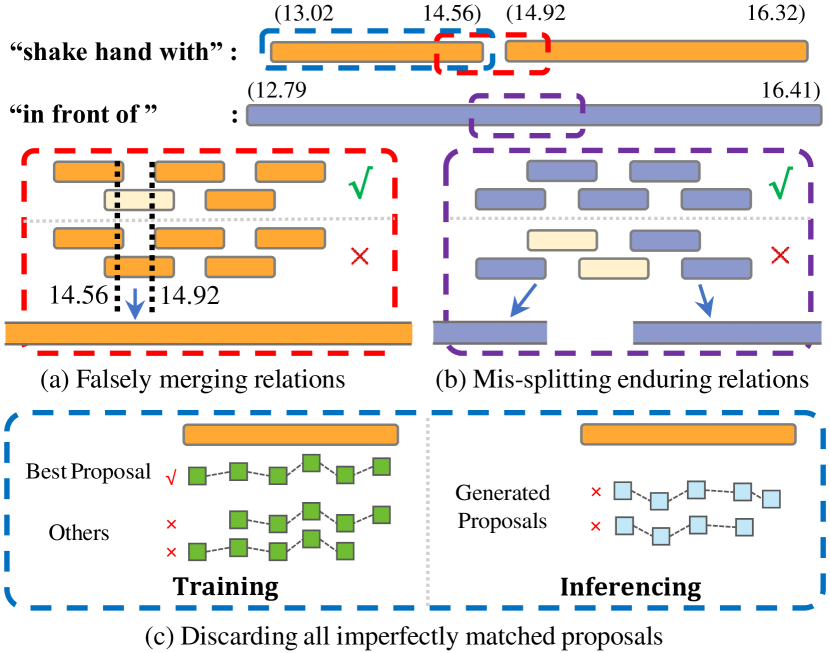
问题定义:视频视觉关系检测(VidVRD)旨在识别视频中主体和客体之间的关系,并确定这些关系发生的时间范围。现有方法通常采用两阶段策略,首先生成候选关系,然后进行分类和时间定位。这种方法的痛点在于忽略了关系类别和时间边界之间的内在联系,导致性能瓶颈。此外,如何有效地建模不同时间尺度的关系也是一个挑战。
核心思路:VrdONE的核心思路是将关系检测视为一个单阶段的实例分割问题。具体来说,它将主体和客体的特征进行融合,然后在此融合特征上进行1D实例分割,直接预测关系类别和对应的时间掩码。这种方法避免了传统两阶段方法的复杂性,并能够更好地利用关系类别和时间信息之间的关联。
技术框架:VrdONE的整体框架包括以下几个主要步骤:1) 提取视频帧中主体和客体的视觉特征;2) 使用Subject-Object Synergy (SOS)模块增强主体和客体特征的相互感知;3) 将增强后的主体和客体特征进行融合;4) 在融合特征上进行1D实例分割,预测关系类别和时间掩码。整个过程在一个阶段内完成,无需额外的提议生成或后处理。
关键创新:VrdONE的关键创新在于其单阶段的设计和SOS模块的引入。单阶段设计简化了流程,提高了效率,并能够更好地利用关系类别和时间信息之间的关联。SOS模块通过让主体和客体在特征融合前相互感知,增强了模型对关系的理解能力。与现有方法的本质区别在于,VrdONE避免了复杂的两阶段流程,直接预测关系类别和时间掩码。
关键设计:SOS模块的具体实现方式未知,论文中可能没有详细描述。损失函数的设计可能包括关系分类损失和时间掩码预测损失。网络结构方面,可能采用了Transformer或类似的序列建模方法来处理视频帧序列,并使用卷积神经网络或全连接层来进行特征融合和1D实例分割。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
VrdONE在VidOR和ImageNet-VidVRD基准测试上取得了state-of-the-art的性能,证明了其在视频视觉关系检测方面的有效性。具体性能数据和提升幅度未知,需要在论文中查找。该模型尤其擅长识别不同时间尺度的关系,表明其在时序建模方面具有优势。
🎯 应用场景
VrdONE在视频监控、智能安防、自动驾驶、视频内容分析等领域具有广泛的应用前景。例如,在视频监控中,可以利用VrdONE自动识别视频中的异常行为,如打架、盗窃等。在自动驾驶中,可以帮助车辆理解周围环境,识别车辆、行人之间的关系,从而做出更安全的决策。此外,VrdONE还可以用于视频内容分析,例如自动生成视频摘要、视频标签等。
📄 摘要(原文)
Video Visual Relation Detection (VidVRD) focuses on understanding how entities interact over time and space in videos, a key step for gaining deeper insights into video scenes beyond basic visual tasks. Traditional methods for VidVRD, challenged by its complexity, typically split the task into two parts: one for identifying what relation categories are present and another for determining their temporal boundaries. This split overlooks the inherent connection between these elements. Addressing the need to recognize entity pairs' spatiotemporal interactions across a range of durations, we propose VrdONE, a streamlined yet efficacious one-stage model. VrdONE combines the features of subjects and objects, turning predicate detection into 1D instance segmentation on their combined representations. This setup allows for both relation category identification and binary mask generation in one go, eliminating the need for extra steps like proposal generation or post-processing. VrdONE facilitates the interaction of features across various frames, adeptly capturing both short-lived and enduring relations. Additionally, we introduce the Subject-Object Synergy (SOS) module, enhancing how subjects and objects perceive each other before combining. VrdONE achieves state-of-the-art performances on the VidOR benchmark and ImageNet-VidVRD, showcasing its superior capability in discerning relations across different temporal scales. The code is available at https://github.com/lucaspk512/vrdone.