Combo: Co-speech holistic 3D human motion generation and efficient customizable adaptation in harmony
作者: Chao Xu, Mingze Sun, Zhi-Qi Cheng, Fei Wang, Yang Liu, Baigui Sun, Ruqi Huang, Alexander Hauptmann
分类: cs.CV
发布日期: 2024-08-18 (更新: 2025-09-18)
备注: Accepted to TPAMI
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Combo:和谐的语音驱动整体3D人体运动生成与高效可定制化适配框架
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 语音驱动 3D人体运动生成 面部表情 身体运动 参数高效微调 Transformer 多模态融合
📋 核心要点
- 现有语音驱动人体运动生成模型难以有效处理语音、身份和情感等多重输入。
- Combo框架通过预训练和X-Adapter微调,以及DU-Trans结构,解耦并协调处理多重输入和面部/身体运动。
- 实验表明,Combo在生成高质量运动的同时,能高效迁移身份和情感,性能优于现有方法。
📝 摘要(中文)
本文提出了一个名为Combo的新框架,用于和谐的语音驱动整体3D人体运动生成和高效的可定制化适配。我们发现,生成模型的一个根本挑战在于其多输入多输出(MIMO)的特性。具体来说,在输入端,模型通常需要同时处理语音信号和角色引导信息(如身份和情感),这不仅对学习能力提出了挑战,也阻碍了模型进一步适应不同的引导信息;在输出端,整体人体运动主要由面部表情和身体运动组成,它们内在相关,但在当前的数据驱动生成过程中难以协调。为了应对上述挑战,我们针对输入和输出端都提出了定制化的设计。对于输入端,我们建议首先在固定身份和中性情感的数据上进行预训练,然后将可定制的条件(身份和情感)的整合推迟到微调阶段,并通过我们新颖的X-Adapter来实现参数高效的微调。对于输出端,我们提出了一个简单而有效的Transformer设计,DU-Trans,它首先分为两个分支来学习面部表情和身体运动的个体特征,然后将它们联合起来学习联合双向分布,并直接预测组合系数。在BEAT2和SHOW数据集上的评估表明,Combo在生成高质量运动方面非常有效,并且在迁移身份和情感方面也很高效。
🔬 方法详解
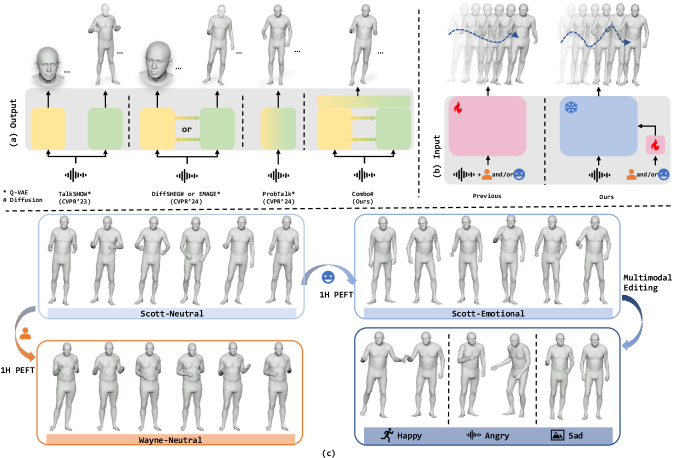
问题定义:论文旨在解决语音驱动的整体3D人体运动生成问题,特别是如何有效地整合语音信息、角色身份和情感引导,并生成协调的面部表情和身体运动。现有方法通常难以同时处理多种输入,且生成的面部和身体运动缺乏自然协调性。
核心思路:论文的核心思路是将多输入问题解耦,先在固定身份和情感的数据上进行预训练,然后再通过高效的微调方法(X-Adapter)来整合身份和情感信息。同时,设计专门的网络结构(DU-Trans)来分别学习面部和身体运动的特征,并最终融合生成协调的运动。
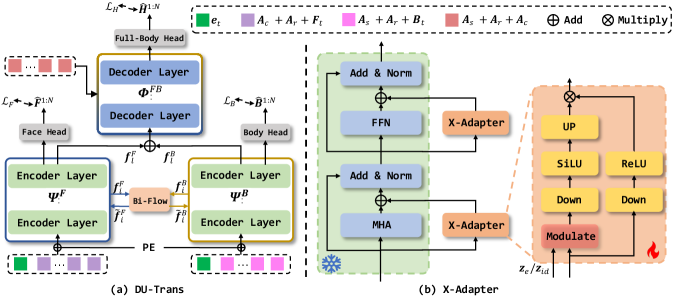
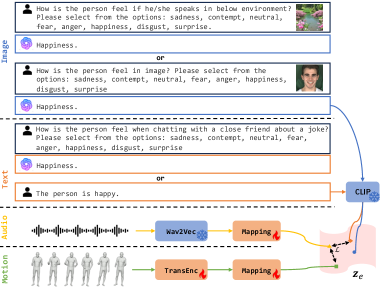
技术框架:Combo框架主要包含两个阶段:预训练阶段和微调阶段。在预训练阶段,模型学习在固定身份和情感下的语音到运动的映射关系。在微调阶段,使用X-Adapter将模型适配到不同的身份和情感。DU-Trans模块负责生成最终的3D人体运动,包括面部表情和身体运动。
关键创新:Combo的关键创新在于:1) 提出了X-Adapter,一种参数高效的微调方法,可以快速将模型适配到新的身份和情感;2) 设计了DU-Trans模块,可以分别学习面部和身体运动的特征,并生成协调的运动。与现有方法相比,Combo能够更好地处理多输入问题,并生成更自然、协调的运动。
关键设计:X-Adapter的具体实现未知,但强调了参数高效性。DU-Trans模块包含两个分支,分别处理面部和身体运动,然后通过Transformer结构进行融合。损失函数的设计也未知,但推测会考虑面部和身体运动的协调性。
🖼️ 关键图片
📊 实验亮点
Combo在BEAT2和SHOW数据集上进行了评估,实验结果表明,Combo能够生成高质量的3D人体运动,并且在迁移身份和情感方面表现出色。具体的性能数据和对比基线未知,但论文强调了Combo的有效性和高效性。
🎯 应用场景
Combo框架可应用于虚拟形象生成、游戏角色动画、人机交互等领域。通过语音输入,即可生成具有特定身份和情感的3D人体运动,从而提升用户体验和交互的自然性。该研究对于开发更智能、更逼真的人工智能应用具有重要价值。
📄 摘要(原文)
In this paper, we propose a novel framework, Combo, for harmonious co-speech holistic 3D human motion generation and efficient customizable adaption. In particular, we identify that one fundamental challenge as the multiple-input-multiple-output (MIMO) nature of the generative model of interest. More concretely, on the input end, the model typically consumes both speech signals and character guidance (e.g., identity and emotion), which not only poses challenge on learning capacity but also hinders further adaptation to varying guidance; on the output end, holistic human motions mainly consist of facial expressions and body movements, which are inherently correlated but non-trivial to coordinate in current data-driven generation process. In response to the above challenge, we propose tailored designs to both ends. For the former, we propose to pre-train on data regarding a fixed identity with neutral emotion, and defer the incorporation of customizable conditions (identity and emotion) to fine-tuning stage, which is boosted by our novel X-Adapter for parameter-efficient fine-tuning. For the latter, we propose a simple yet effective transformer design, DU-Trans, which first divides into two branches to learn individual features of face expression and body movements, and then unites those to learn a joint bi-directional distribution and directly predicts combined coefficients. Evaluated on BEAT2 and SHOW datasets, Combo is highly effective in generating high-quality motions but also efficient in transferring identity and emotion. Project website: \href{https://xc-csc101.github.io/combo/}{Combo}.