Knowledge Distillation with Refined Logits
作者: Wujie Sun, Defang Chen, Siwei Lyu, Genlang Chen, Chun Chen, Can Wang
分类: cs.CV
发布日期: 2024-08-14 (更新: 2025-07-27)
备注: ICCV 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出精炼Logit蒸馏(RLD)方法,提升知识蒸馏效果并保持类间相关性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 模型压缩 Logit蒸馏 教师模型 学生模型
📋 核心要点
- 现有logit蒸馏方法受限于教师模型可能产生的错误预测,导致学生模型学习目标不一致。
- RLD方法通过标签信息动态精炼教师logits,消除误导信息,同时保留重要的类间相关性。
- 在CIFAR-100和ImageNet上的实验表明,RLD方法显著优于现有的知识蒸馏方法。
📝 摘要(中文)
本文提出精炼Logit蒸馏(RLD)方法,旨在解决现有logit蒸馏方法的局限性。观察到即使是高性能的教师模型也可能做出错误的预测,导致标准蒸馏损失与交叉熵损失之间产生更大的差异,从而损害学生模型学习目标的一致性。以往尝试使用标签来经验性地纠正教师预测的方法可能会破坏类间相关性。相比之下,RLD利用标签信息动态地精炼教师logits。通过这种方式,该方法可以有效地消除来自教师模型的误导信息,同时保留关键的类间相关性,从而提高蒸馏知识的价值和效率。在CIFAR-100和ImageNet上的实验结果表明,RLD优于现有方法。代码已开源。
🔬 方法详解
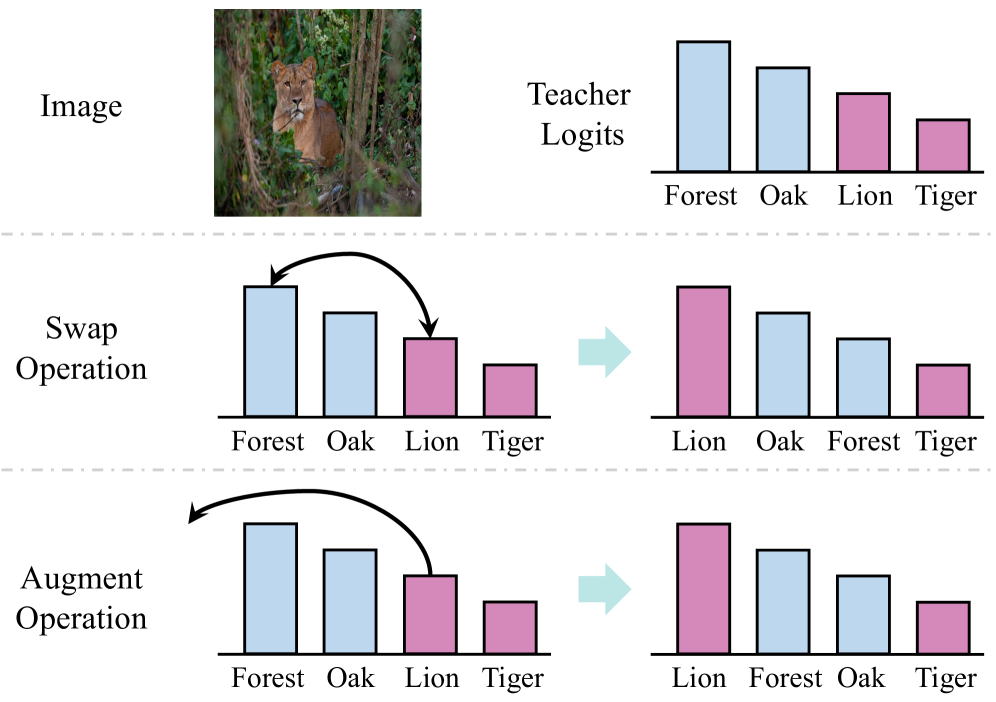
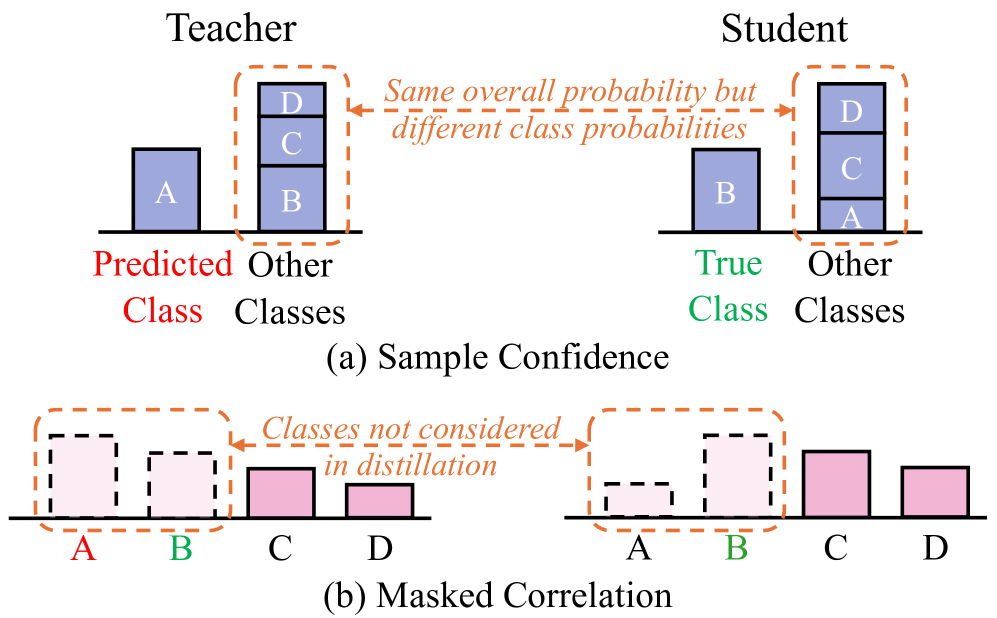
问题定义:知识蒸馏旨在将大型教师模型的知识迁移到小型学生模型。现有的logit蒸馏方法直接使用教师模型的logits作为学习目标,但教师模型并非完美,其错误的预测会误导学生模型的学习,降低蒸馏效果。此外,简单地使用one-hot标签修正教师模型的预测会破坏类别之间的相关性,损失有用的信息。
核心思路:RLD的核心思路是利用标签信息,动态地“精炼”教师模型的logits,使其更接近真实标签分布,同时保留类别之间的相关性。通过这种方式,可以减少教师模型错误预测对学生模型的误导,提高知识蒸馏的效率和效果。
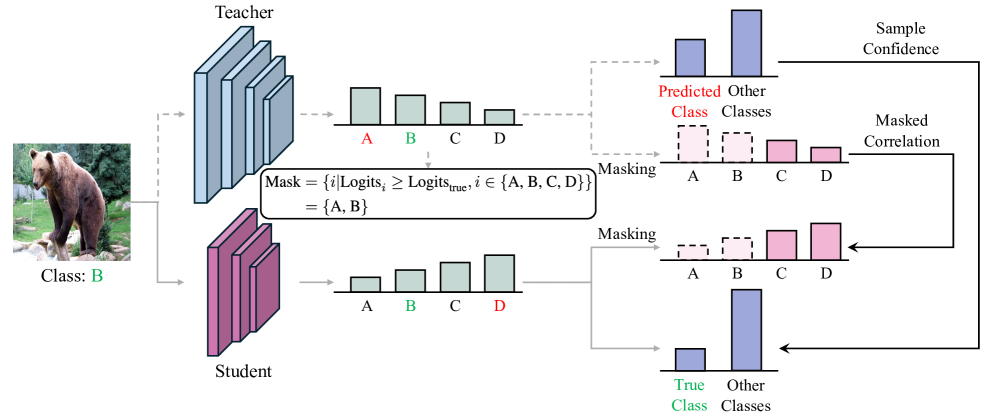
技术框架:RLD的整体框架与标准的logit蒸馏类似,主要区别在于损失函数的设计。在计算蒸馏损失时,RLD首先根据标签信息对教师模型的logits进行精炼,然后使用精炼后的logits作为学生模型的学习目标。具体流程包括:1) 获取教师模型的logits;2) 根据标签信息,使用特定的策略对logits进行调整;3) 计算学生模型logits与精炼后的教师模型logits之间的蒸馏损失。
关键创新:RLD的关键创新在于动态精炼教师模型logits的策略。与直接使用one-hot标签修正不同,RLD旨在保留类别之间的相关性,同时纠正教师模型的错误预测。具体的精炼策略可以根据不同的任务和数据集进行调整,例如,可以采用加权平均的方式,将教师模型的logits与基于标签的logits进行融合。
关键设计:RLD的关键设计包括:1) 精炼策略的选择:如何有效地利用标签信息来调整教师模型的logits,同时保留类别之间的相关性;2) 损失函数的选择:如何设计蒸馏损失函数,以更好地利用精炼后的logits;3) 超参数的设置:例如,用于控制logits调整幅度的权重参数等。
🖼️ 关键图片
📊 实验亮点
在CIFAR-100和ImageNet数据集上的实验结果表明,RLD方法显著优于现有的知识蒸馏方法。例如,在CIFAR-100上,使用ResNet-8作为学生模型,RLD方法相比于传统的logit蒸馏方法,Top-1准确率提升了超过2%。在ImageNet上,RLD也取得了类似的提升效果,证明了其有效性。
🎯 应用场景
RLD方法可广泛应用于模型压缩和知识迁移领域,尤其适用于需要将大型模型部署到资源受限设备上的场景。例如,可以将预训练的图像分类模型蒸馏到移动设备上,实现高效的图像识别。此外,RLD还可以应用于其他任务,如目标检测、语义分割等,提高模型在这些任务上的性能。
📄 摘要(原文)
Recent research on knowledge distillation has increasingly focused on logit distillation because of its simplicity, effectiveness, and versatility in model compression. In this paper, we introduce Refined Logit Distillation (RLD) to address the limitations of current logit distillation methods. Our approach is motivated by the observation that even high-performing teacher models can make incorrect predictions, creating an exacerbated divergence between the standard distillation loss and the cross-entropy loss, which can undermine the consistency of the student model's learning objectives. Previous attempts to use labels to empirically correct teacher predictions may undermine the class correlations. In contrast, our RLD employs labeling information to dynamically refine teacher logits. In this way, our method can effectively eliminate misleading information from the teacher while preserving crucial class correlations, thus enhancing the value and efficiency of distilled knowledge. Experimental results on CIFAR-100 and ImageNet demonstrate its superiority over existing methods. Our code is available at https://github.com/zju-SWJ/RLD.