MathScape: Benchmarking Multimodal Large Language Models in Real-World Mathematical Contexts
作者: Hao Liang, Linzhuang Sun, Minxuan Zhou, Zirong Chen, Meiyi Qiang, Mingan Lin, Tianpeng Li, Fan Yang, Zenan Zhou, Wentao Zhang
分类: cs.CV, cs.CL
发布日期: 2024-08-14 (更新: 2025-08-10)
💡 一句话要点
MathScape:提出真实世界数学场景多模态大语言模型评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大语言模型 数学推理 真实世界场景 基准测试
📋 核心要点
- 现有数学推理基准主要依赖数字渲染内容,无法充分评估模型在真实世界场景下的能力。
- MathScape构建了一个包含真实世界图像和数学问题的新基准,更贴近实际教育场景的挑战。
- 实验表明,现有SOTA模型在MathScape上的表现远低于人类水平,揭示了模型在真实场景推理上的不足。
📝 摘要(中文)
随着多模态大语言模型(MLLM)的快速发展,评估其数学推理能力变得越来越重要。视觉-文本数学推理是衡量MLLM理解和解决复杂、多步骤定量问题的关键指标。现有的基准测试,如MathVista和MathVerse,虽然推动了多模态数学能力的评估,但主要依赖于数字渲染内容,未能捕捉到真实世界场景的复杂性。为了弥补这一差距,我们推出了MathScape,这是一个新的基准测试,专注于评估MLLM在真实数学环境中的推理能力。MathScape包含1369个高质量的数学问题,并配有人工拍摄的真实世界图像,紧密反映了实际教育环境中遇到的挑战。我们对九个领先的闭源MLLM、三个超过200亿参数的开源MLLM和七个较小规模的MLLM进行了全面的多维度评估。结果表明,即使是最先进的模型在真实世界的数学任务中也表现不佳,落后于人类水平,突显了当前模型能力的局限性。此外,我们发现模型在合成或数字渲染图像上的出色表现并不能保证其在真实世界任务中的有效性。这突显了MathScape在下一阶段多模态数学推理中的必要性。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在真实世界数学场景下的推理能力评估问题。现有基准测试主要使用数字渲染图像,与真实场景存在差距,无法有效评估模型在实际应用中的表现。这些基准忽略了真实世界图像的复杂性和多样性,例如光照变化、遮挡、噪声等,导致模型在这些基准上表现良好,但在实际场景中却表现不佳。
核心思路:论文的核心思路是构建一个更贴近真实世界的数学推理基准,即MathScape。该基准使用人工拍摄的真实世界图像,并配以相应的数学问题,从而更全面地评估MLLM在真实场景下的推理能力。通过在MathScape上评估MLLM,可以更好地了解模型在实际应用中的局限性,并为未来的研究提供方向。
技术框架:MathScape基准测试包含以下几个主要组成部分:1) 数据收集:收集包含真实世界图像和数学问题的数据集。2) 数据标注:对收集到的数据进行标注,包括数学问题的答案和图像中的相关信息。3) 模型评估:使用MathScape评估各种MLLM的性能。4) 结果分析:分析评估结果,找出模型的优势和不足。整个流程旨在提供一个全面、可靠的MLLM真实世界数学推理能力评估平台。
关键创新:MathScape的关键创新在于其真实性。与现有基准测试相比,MathScape使用人工拍摄的真实世界图像,更贴近实际应用场景。这种真实性使得MathScape能够更有效地评估MLLM在真实场景下的推理能力,并揭示模型在实际应用中的局限性。此外,MathScape还提供了多样化的数学问题,涵盖了不同的数学概念和难度级别,从而更全面地评估MLLM的数学推理能力。
关键设计:MathScape的数据集包含1369个高质量的数学问题,并配有人工拍摄的真实世界图像。图像涵盖了各种场景,例如教室、图书馆、户外等。数学问题涵盖了不同的数学概念,例如代数、几何、微积分等。为了保证数据的质量,所有数据都经过了人工审核和验证。评估指标包括准确率、召回率、F1值等。论文还对九个领先的闭源MLLM、三个超过200亿参数的开源MLLM和七个较小规模的MLLM进行了评估,并分析了评估结果。
🖼️ 关键图片
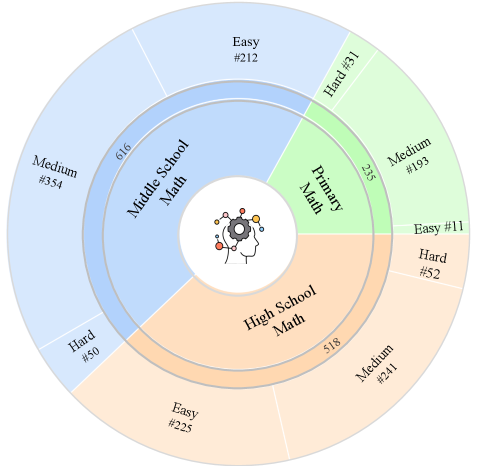


📊 实验亮点
实验结果表明,即使是SOTA模型在MathScape上的表现也远低于人类水平,突显了当前模型在真实世界数学推理方面的局限性。例如,某些模型在数字渲染图像上的准确率超过90%,但在MathScape上的准确率仅为50%左右。此外,实验还发现,模型在合成数据上的表现与在真实数据上的表现之间存在显著差异,表明现有模型对真实世界场景的泛化能力较差。
🎯 应用场景
MathScape的研究成果可应用于教育领域,帮助开发更智能的教育辅助工具,例如自动解题系统、个性化学习平台等。此外,该研究还可以促进多模态大语言模型在其他领域的应用,例如机器人导航、图像理解等。通过提高模型在真实世界场景下的推理能力,可以使其更好地服务于人类社会。
📄 摘要(原文)
With the rapid progress of Multimodal LLMs, evaluating their mathematical reasoning capabilities has become an increasingly important research direction. In particular, visual-textual mathematical reasoning serves as a key indicator of an MLLM's ability to comprehend and solve complex, multi-step quantitative problems. While existing benchmarks such as MathVista and MathVerse have advanced the evaluation of multimodal math proficiency, they primarily rely on digitally rendered content and fall short in capturing the complexity of real-world scenarios. To bridge this gap, we introduce MathScape, a novel benchmark focused on assessing MLLMs' reasoning ability in realistic mathematical contexts. MathScape comprises 1,369 high-quality math problems paired with human-captured real-world images, closely reflecting the challenges encountered in practical educational settings. We conduct a thorough multi-dimensional evaluation across nine leading closed-source MLLMs, three open-source MLLMs with over 20 billion parameters, and seven smaller-scale MLLMs. Our results show that even SOTA models struggle with real-world math tasks, lagging behind human performance -- highlighting critical limitations in current model capabilities. Moreover, we find that strong performance on synthetic or digitally rendered images does not guarantee similar effectiveness on real-world tasks. This underscores the necessity of MathScape in the next stage of multimodal mathematical reasoning.