SceneGPT: A Language Model for 3D Scene Understanding
作者: Shivam Chandhok
分类: cs.CV
发布日期: 2024-08-13
备注: UBC Report
💡 一句话要点
SceneGPT:一种用于3D场景理解的语言模型,无需3D预训练。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting)
关键词: 3D场景理解 语言模型 上下文学习 场景图 空间推理
📋 核心要点
- 现有3D场景理解模型依赖大量3D监督数据,训练成本高昂且泛化性受限。
- SceneGPT利用预训练语言模型的先验知识,通过上下文学习实现3D空间推理,无需额外3D预训练。
- 实验表明,SceneGPT在对象和场景理解任务上表现出潜力,能够理解对象语义、物理属性和空间关系。
📝 摘要(中文)
由于缺乏用于3D监督训练的数据源和大规模训练机制,构建能够理解和推理3D场景的模型非常困难。本文探讨了如何在没有任何3D预训练的情况下,利用预训练语言模型中的知识进行3D场景理解。本文旨在确定预训练的LLM是否具备在3D空间中推理所需的先验知识/知识,以及如何提示它们,使其可用于3D中的通用空间推理和对象理解。为此,我们提出了SceneGPT,一种基于LLM的场景理解系统,无需训练或显式3D监督即可执行3D空间推理。我们框架的关键组件是:1)3D场景图,作为场景表示,编码场景中的对象及其空间关系;2)一个预训练的LLM,可以通过上下文学习进行调整,以进行3D空间推理。我们在对象和场景理解任务(包括对象语义、物理属性和可供性(对象级别)和空间理解(场景级别))上对我们的框架进行了定性评估。
🔬 方法详解
问题定义:现有3D场景理解方法依赖于大量的3D标注数据进行训练,这不仅成本高昂,而且模型的泛化能力受到限制。此外,如何有效地利用已有的预训练语言模型(LLM)的知识来提升3D场景理解能力是一个挑战。
核心思路:SceneGPT的核心思路是利用预训练LLM的强大语言理解和推理能力,通过上下文学习的方式,使其能够理解和推理3D场景。该方法避免了对3D数据进行预训练的需求,从而降低了训练成本并提高了模型的泛化能力。
技术框架:SceneGPT的整体框架包含两个主要组件:3D场景图和预训练LLM。首先,使用3D场景图来表示3D场景,其中节点表示场景中的对象,边表示对象之间的空间关系。然后,将场景图的信息以文本形式输入到预训练LLM中,通过上下文学习的方式,让LLM理解场景中的对象及其空间关系,并进行推理。
关键创新:SceneGPT的关键创新在于它提出了一种无需3D预训练,直接利用预训练LLM进行3D场景理解的方法。与现有方法相比,该方法避免了对3D数据的依赖,降低了训练成本,并提高了模型的泛化能力。
关键设计:SceneGPT的关键设计包括:1)如何有效地将3D场景图的信息编码成文本形式,以便LLM能够理解;2)如何设计合适的上下文学习提示,引导LLM进行3D空间推理。具体的参数设置、损失函数和网络结构等技术细节在论文中没有详细说明,属于未知信息。
🖼️ 关键图片


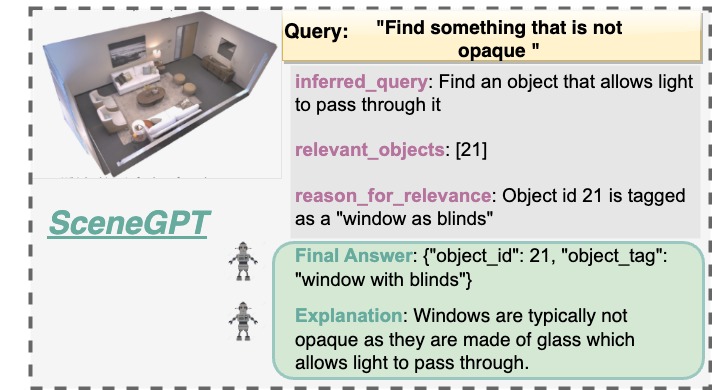
📊 实验亮点
论文主要进行了定性评估,展示了SceneGPT在对象语义、物理属性和可供性(对象级别)以及空间理解(场景级别)等任务上的潜力。虽然没有提供具体的性能数据和对比基线,但结果表明,即使没有3D预训练,预训练LLM也能通过上下文学习进行有效的3D场景理解。
🎯 应用场景
SceneGPT在机器人导航、虚拟现实、增强现实、自动驾驶等领域具有广泛的应用前景。它可以帮助机器人更好地理解周围环境,从而实现更智能的导航和交互。在虚拟现实和增强现实中,它可以提供更逼真的场景体验。在自动驾驶领域,它可以帮助车辆更好地理解交通场景,从而提高驾驶安全性。
📄 摘要(原文)
Building models that can understand and reason about 3D scenes is difficult owing to the lack of data sources for 3D supervised training and large-scale training regimes. In this work we ask - How can the knowledge in a pre-trained language model be leveraged for 3D scene understanding without any 3D pre-training. The aim of this work is to establish whether pre-trained LLMs possess priors/knowledge required for reasoning in 3D space and how can we prompt them such that they can be used for general purpose spatial reasoning and object understanding in 3D. To this end, we present SceneGPT, an LLM based scene understanding system which can perform 3D spatial reasoning without training or explicit 3D supervision. The key components of our framework are - 1) a 3D scene graph, that serves as scene representation, encoding the objects in the scene and their spatial relationships 2) a pre-trained LLM that can be adapted with in context learning for 3D spatial reasoning. We evaluate our framework qualitatively on object and scene understanding tasks including object semantics, physical properties and affordances (object-level) and spatial understanding (scene-level).