Unseen No More: Unlocking the Potential of CLIP for Generative Zero-shot HOI Detection
作者: Yixin Guo, Yu Liu, Jianghao Li, Weimin Wang, Qi Jia
分类: cs.CV
发布日期: 2024-08-12
备注: Accepted by ACM MM 2024
🔗 代码/项目: GITHUB
💡 一句话要点
HOIGen:首个基于CLIP生成模型的零样本HOI检测方法,缓解了seen-unseen混淆问题。
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 零样本学习 人-物交互检测 CLIP 生成模型 特征生成 原型学习 计算机视觉
📋 核心要点
- 现有基于CLIP嵌入的零样本HOI检测方法存在seen-unseen混淆问题,限制了模型在未见类别上的泛化能力。
- HOIGen通过CLIP注入的特征生成器合成HOI特征,并与真实特征混合,实现已见和未见类别的联合训练。
- HOIGen构建了生成原型库和多知识原型库,丰富了HOI分数,并在HICO-DET上取得了显著的性能提升。
📝 摘要(中文)
本文提出了一种名为HOIGen的基于生成模型的零样本人-物交互(HOI)检测方法,旨在解决现有方法中存在的seen-unseen混淆问题。现有方法通常利用CLIP嵌入来提升零样本HOI检测性能,但仅在已见类别上训练分类器,导致模型在推理时对已见和未见类别产生混淆。此外,prompt-tuning和adapters的使用进一步加剧了这种差距。HOIGen通过CLIP注入的特征生成器,生成人、物和联合特征,并将真实的已见样本特征与合成特征混合,从而允许模型联合训练已见和未见类别。为了丰富HOI分数,构建了成对HOI识别分支中的生成原型库和图像级HOI识别分支中的多知识原型库。在HICO-DET基准上的实验表明,HOIGen在各种零样本设置下,对已见和未见类别均取得了优于其他方法的性能。
🔬 方法详解
问题定义:零样本人-物交互(HOI)检测旨在识别训练集中未出现的HOI类别。现有基于CLIP的方法,虽然利用了CLIP强大的zero-shot能力,但通常只在已见类别上训练分类器,导致模型在推理时难以区分已见和未见的HOI类别,造成seen-unseen混淆。此外,prompt tuning等技术的使用进一步扩大了已见和未见类别之间的性能差距。
核心思路:HOIGen的核心思路是利用CLIP的生成能力,生成未见类别的HOI特征,从而实现已见和未见类别的联合训练。通过将合成的未见类别特征与真实的已见类别特征混合,模型可以学习到更具泛化性的HOI表示,从而缓解seen-unseen混淆问题。
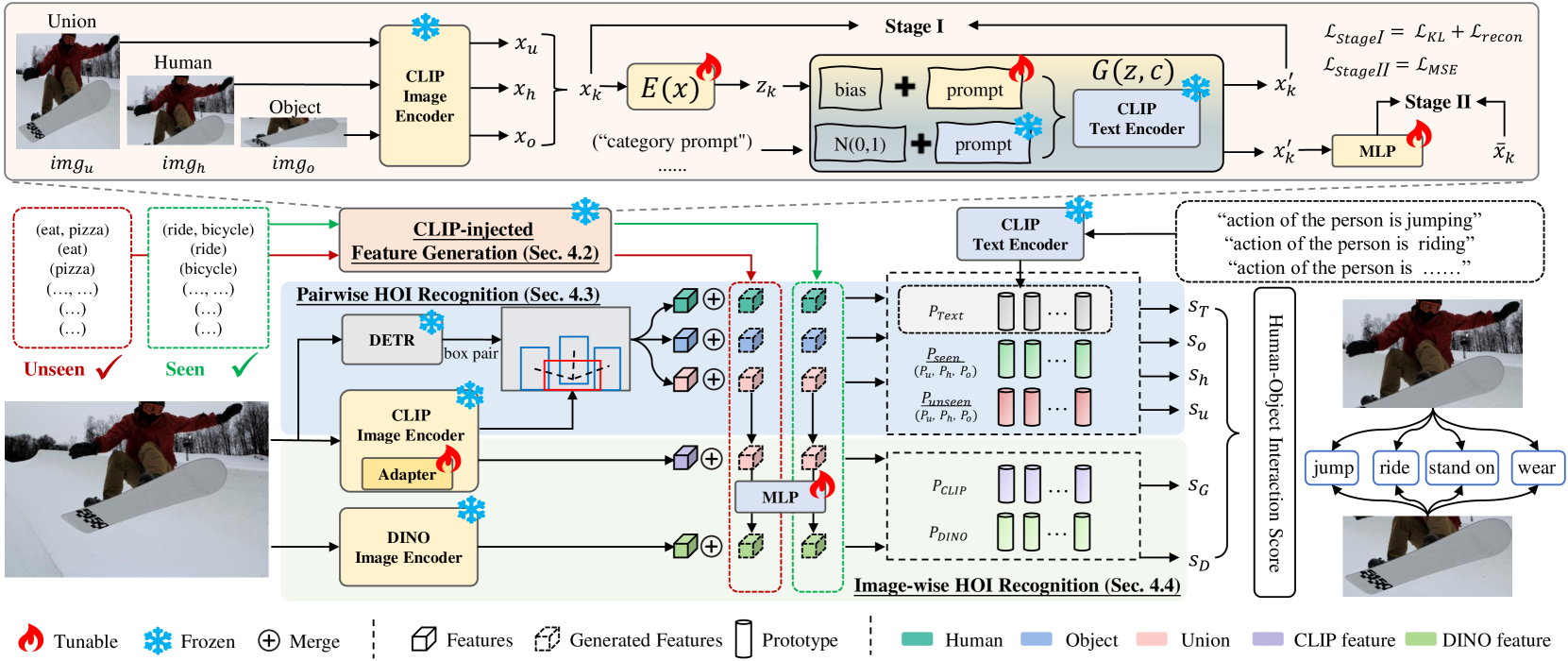
技术框架:HOIGen包含一个CLIP注入的特征生成器,用于生成人、物和联合特征。该生成器以CLIP的文本嵌入作为条件,生成对应的视觉特征。然后,将生成的特征与真实的已见类别特征混合,输入到HOI检测器中进行训练。HOIGen还包含两个HOI识别分支:一个成对HOI识别分支和一个图像级HOI识别分支。成对HOI识别分支使用生成原型库来丰富HOI分数,图像级HOI识别分支使用多知识原型库来进一步提升性能。
关键创新:HOIGen的关键创新在于利用CLIP进行特征生成,而不是仅仅进行特征提取。这是首个基于生成模型的零样本HOI检测方法。通过生成未见类别的HOI特征,HOIGen能够有效地缓解seen-unseen混淆问题,提升模型在未见类别上的泛化能力。此外,生成原型库和多知识原型库的设计也进一步提升了HOI分数的准确性。
关键设计:CLIP注入的特征生成器使用一个多层感知机(MLP)将CLIP的文本嵌入映射到视觉特征空间。生成器使用对抗训练的方式进行训练,以保证生成特征的真实性。生成原型库包含每个HOI类别的原型特征,用于计算HOI分数。多知识原型库包含来自不同知识源的原型特征,例如视觉特征、文本特征和关系特征,用于进一步提升HOI分数的准确性。损失函数包括HOI检测损失、HOI识别损失和对抗损失。
🖼️ 关键图片

📊 实验亮点
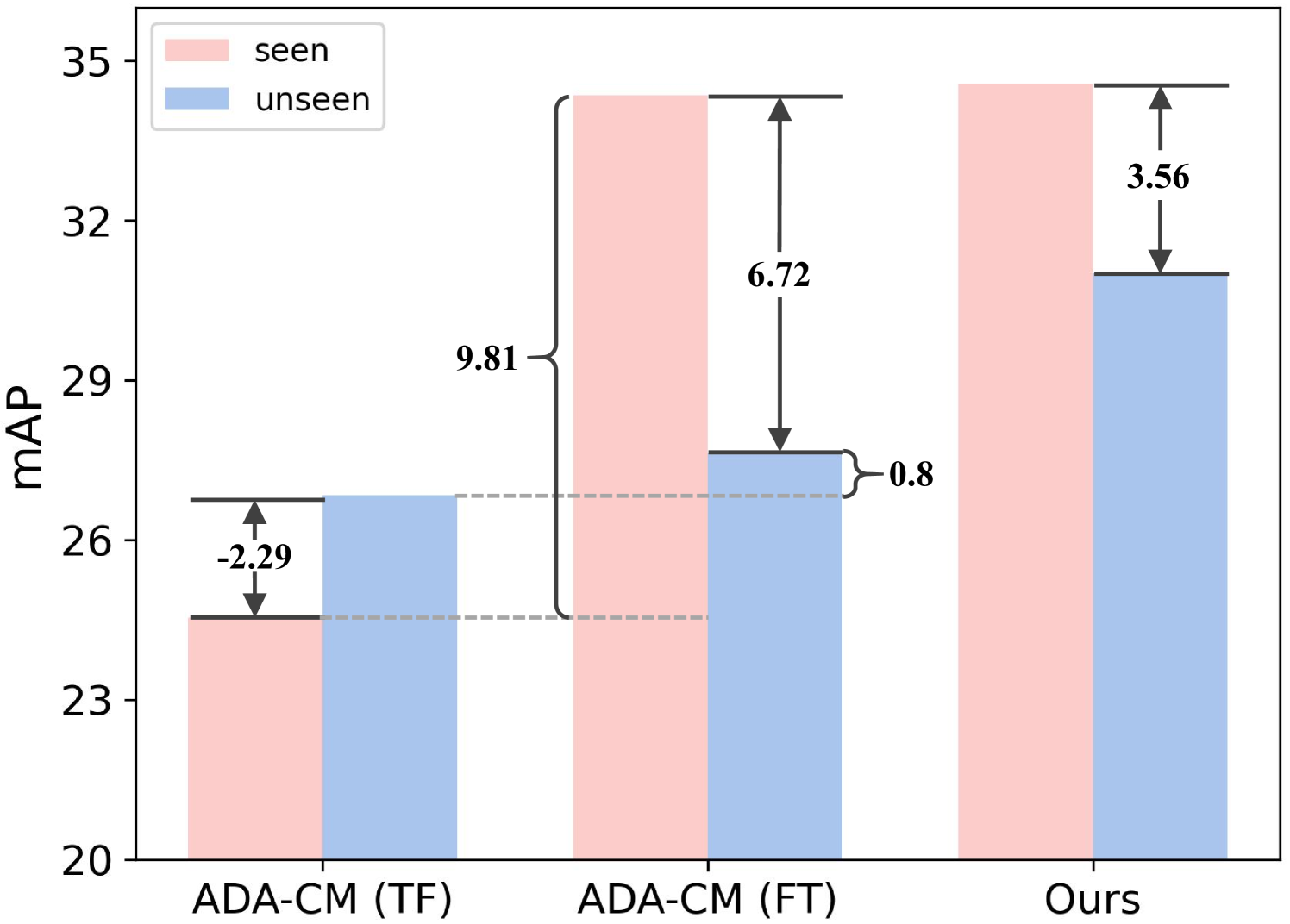
HOIGen在HICO-DET基准上取得了显著的性能提升。在zero-shot设置下,HOIGen在未见类别上的mAP超过了现有最佳方法,并且在已见类别上的性能也得到了提升。实验结果表明,HOIGen能够有效地缓解seen-unseen混淆问题,提升模型在未见类别上的泛化能力。
🎯 应用场景
HOIGen在机器人交互、视频监控、图像检索等领域具有广泛的应用前景。例如,在机器人交互中,HOIGen可以帮助机器人理解人类的动作意图,从而实现更自然的人机交互。在视频监控中,HOIGen可以用于检测异常行为,例如盗窃、打架等。在图像检索中,HOIGen可以用于根据HOI类别检索图像。
📄 摘要(原文)
Zero-shot human-object interaction (HOI) detector is capable of generalizing to HOI categories even not encountered during training. Inspired by the impressive zero-shot capabilities offered by CLIP, latest methods strive to leverage CLIP embeddings for improving zero-shot HOI detection. However, these embedding-based methods train the classifier on seen classes only, inevitably resulting in seen-unseen confusion for the model during inference. Besides, we find that using prompt-tuning and adapters further increases the gap between seen and unseen accuracy. To tackle this challenge, we present the first generation-based model using CLIP for zero-shot HOI detection, coined HOIGen. It allows to unlock the potential of CLIP for feature generation instead of feature extraction only. To achieve it, we develop a CLIP-injected feature generator in accordance with the generation of human, object and union features. Then, we extract realistic features of seen samples and mix them with synthetic features together, allowing the model to train seen and unseen classes jointly. To enrich the HOI scores, we construct a generative prototype bank in a pairwise HOI recognition branch, and a multi-knowledge prototype bank in an image-wise HOI recognition branch, respectively. Extensive experiments on HICO-DET benchmark demonstrate our HOIGen achieves superior performance for both seen and unseen classes under various zero-shot settings, compared with other top-performing methods. Code is available at: https://github.com/soberguo/HOIGen