Learning Collaborative Knowledge with Multimodal Representation for Polyp Re-Identification
作者: Suncheng Xiang, Jiale Guan, Shilun Cai, Jiacheng Ruan, Dahong Qian
分类: cs.CV
发布日期: 2024-08-12 (更新: 2025-10-21)
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于多模态协作学习的息肉Re-ID框架,提升结直肠癌辅助诊断性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 息肉Re-ID 多模态学习 协作学习 特征融合 计算机辅助诊断
📋 核心要点
- 传统Re-ID方法在结肠镜息肉Re-ID任务中表现不佳,主要原因是领域差距大,且忽略了多模态信息的互补性。
- 论文提出一种深度多模态协作学习框架DMCL,旨在促进多模态知识的协作,从而提升模型在医学场景下的泛化能力。
- 实验结果表明,所提出的多模态方法优于现有的单模态Re-ID模型,尤其是在结合协作多模态融合策略时。
📝 摘要(中文)
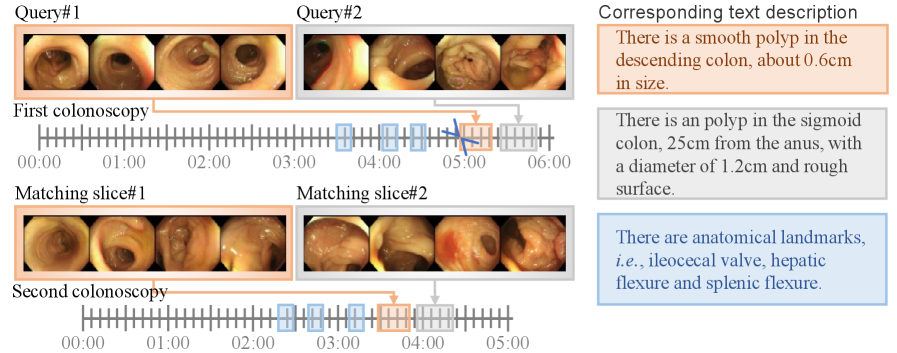
结肠镜息肉Re-ID旨在从大型图库中匹配同一息肉的不同视角图像,这些图像由不同的相机拍摄,这在计算机辅助诊断中对结直肠癌的预防和治疗起着重要作用。然而,由于较大的领域差距,直接采用在ImageNet数据集上训练的CNN模型的传统Re-ID方法通常在结肠镜数据集上产生不令人满意的检索性能。更糟糕的是,这些解决方案通常在视觉样本的基础上学习单模态表示,这未能探索来自其他不同模态的互补信息。为了应对这一挑战,我们提出了一种新的深度多模态协作学习框架DMCL用于息肉Re-ID,它可以有效地促进多模态知识协作并增强医学场景中的泛化能力。在此基础上,引入了一种动态多模态特征融合策略,通过端到端训练来利用优化的视觉-文本表示进行多模态融合。在标准基准上的实验表明,多模态设置优于最先进的单模态Re-ID模型,特别是与协作多模态融合策略相结合时。
🔬 方法详解
问题定义:结肠镜息肉Re-ID旨在解决在不同视角和不同相机下拍摄的同一息肉图像的匹配问题。现有方法主要基于在ImageNet上预训练的CNN模型,但由于结肠镜图像与自然图像存在较大的领域差异,导致性能不佳。此外,现有方法通常只利用视觉信息,忽略了其他模态(如文本描述)可能提供的互补信息。
核心思路:论文的核心思路是利用多模态信息(视觉和文本)进行协作学习,从而提升息肉Re-ID的性能。通过多模态信息的融合,模型可以学习到更鲁棒和更具判别性的特征表示,从而更好地应对领域差异和视角变化带来的挑战。
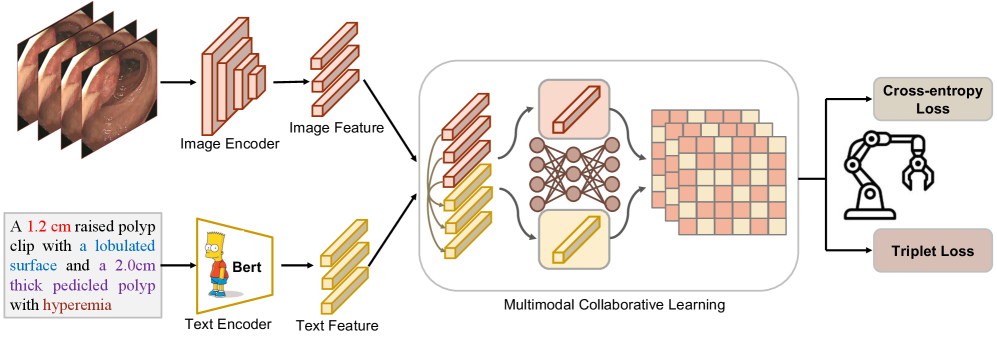
技术框架:DMCL框架主要包含以下几个模块:1) 多模态特征提取模块:用于提取视觉和文本特征;2) 多模态知识协作模块:用于促进不同模态之间的知识共享和协作;3) 动态多模态特征融合模块:用于将不同模态的特征进行融合,得到最终的特征表示。整个框架采用端到端的方式进行训练。
关键创新:论文的关键创新在于提出了多模态协作学习框架DMCL,该框架能够有效地促进多模态知识的协作,从而提升模型在医学场景下的泛化能力。此外,论文还提出了一种动态多模态特征融合策略,能够自适应地调整不同模态特征的权重,从而更好地利用多模态信息。
关键设计:在多模态特征提取模块中,可以使用预训练的CNN模型(如ResNet)提取视觉特征,使用预训练的语言模型(如BERT)提取文本特征。在多模态知识协作模块中,可以使用注意力机制或图神经网络等方法来促进不同模态之间的知识共享。在动态多模态特征融合模块中,可以使用门控机制或注意力机制来动态地调整不同模态特征的权重。损失函数可以采用三元组损失或对比损失等常用的Re-ID损失函数。
🖼️ 关键图片

📊 实验亮点
论文在标准数据集上进行了实验,结果表明,所提出的DMCL框架优于现有的单模态Re-ID模型。通过结合协作多模态融合策略,模型的性能得到了进一步提升。具体性能提升数据未知,但摘要中明确说明了多模态设置的优越性。
🎯 应用场景
该研究成果可应用于计算机辅助诊断领域,辅助医生进行结直肠癌的筛查和诊断。通过准确地识别同一息肉的不同图像,可以帮助医生更好地跟踪息肉的生长情况,从而制定更有效的治疗方案。此外,该方法还可以扩展到其他医学图像Re-ID任务中,具有广泛的应用前景。
📄 摘要(原文)
Colonoscopic Polyp Re-Identification aims to match the same polyp from a large gallery with images from different views taken using different cameras, which plays an important role in the prevention and treatment of colorectal cancer in computer-aided diagnosis. However, traditional methods for object ReID directly adopting CNN models trained on the ImageNet dataset usually produce unsatisfactory retrieval performance on colonoscopic datasets due to the large domain gap. Worsely, these solutions typically learn unimodal modal representations on the basis of visual samples, which fails to explore complementary information from other different modalities. To address this challenge, we propose a novel Deep Multimodal Collaborative Learning framework named DMCL for polyp re-identification, which can effectively encourage multimodal knowledge collaboration and reinforce generalization capability in medical scenarios. On the basis of it, a dynamic multimodal feature fusion strategy is introduced to leverage the optimized visual-text representations for multimodal fusion via end-to-end training. Experiments on the standard benchmarks show the benefits of the multimodal setting over state-of-the-art unimodal ReID models, especially when combined with the collaborative multimodal fusion strategy. The code is publicly available at https://github.com/JeremyXSC/DMCL.