VITA: Towards Open-Source Interactive Omni Multimodal LLM
作者: Chaoyou Fu, Haojia Lin, Zuwei Long, Yunhang Shen, Yuhang Dai, Meng Zhao, Yi-Fan Zhang, Shaoqi Dong, Yangze Li, Xiong Wang, Haoyu Cao, Di Yin, Long Ma, Xiawu Zheng, Rongrong Ji, Yunsheng Wu, Ran He, Caifeng Shan, Xing Sun
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-08-09 (更新: 2025-05-30)
备注: Project Page: https://vita-home.github.io
💡 一句话要点
VITA:首个开源交互式全模态多模态大语言模型,支持视频、图像、文本和音频同步处理与交互。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 开源模型 人机交互 视频理解 音频理解 视觉理解 指令微调 多任务学习
📋 核心要点
- 现有开源模型在多模态处理能力和交互体验方面存在不足,难以满足实际应用需求。
- VITA通过两阶段多任务学习,将Mixtral 8x7B扩展为支持视频、图像、文本和音频的全模态交互模型。
- 实验表明,VITA在多语言、视觉和音频理解方面表现出色,并在多模态人机交互体验方面取得进展。
📝 摘要(中文)
GPT-4o卓越的多模态能力和交互体验凸显了它们在实际应用中的必要性,然而开源模型在这两方面鲜有突出表现。本文介绍了VITA,这是首个开源的多模态大语言模型(MLLM),擅长同时处理和分析视频、图像、文本和音频模态,并具有先进的多模态交互体验。VITA以Mixtral 8x7B作为语言基础,首先扩展了其中文词汇,然后进行了双语指令微调。我们通过多模态对齐和指令微调的两阶段多任务学习,进一步赋予了语言模型视觉和音频能力。VITA在多语言、视觉和音频理解方面展示了强大的基础能力,这体现在其在各种单模态和多模态基准测试中的出色表现。除了基础能力之外,我们在增强自然的多模态人机交互体验方面取得了显著进展。VITA是开源社区探索多模态理解和交互无缝融合的第一步。虽然要使VITA接近闭源模型还有很多工作要做,但我们希望它作为先驱能够成为后续研究的基石。项目主页:https://vita-home.github.io。
🔬 方法详解
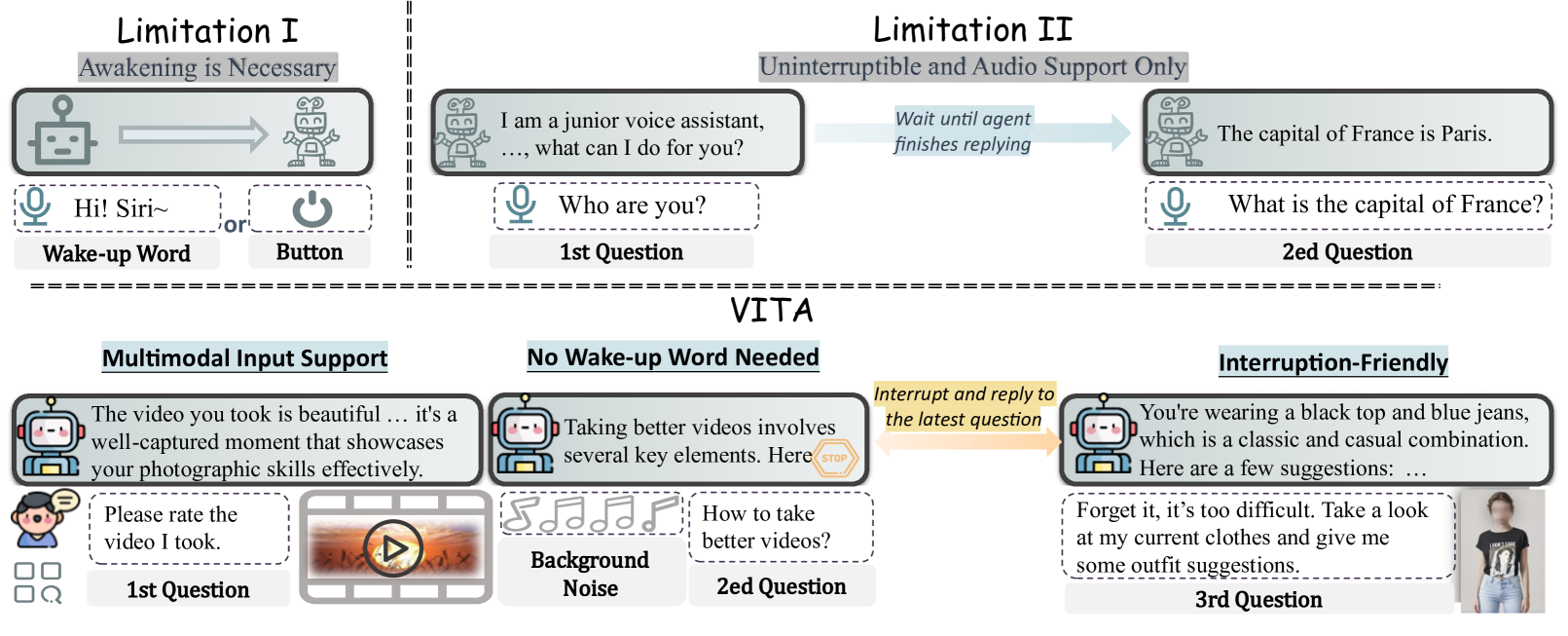
问题定义:现有开源多模态大语言模型在同时处理多种模态信息(视频、图像、文本、音频)以及提供自然的人机交互体验方面存在明显不足。这限制了它们在实际应用中的潜力,例如智能助手、多媒体内容创作等。
核心思路:VITA的核心思路是基于一个强大的开源语言模型(Mixtral 8x7B),通过多阶段的训练,逐步赋予其处理和理解多种模态信息的能力,并优化其人机交互体验。这种方法旨在弥合开源模型与闭源模型在多模态能力上的差距。
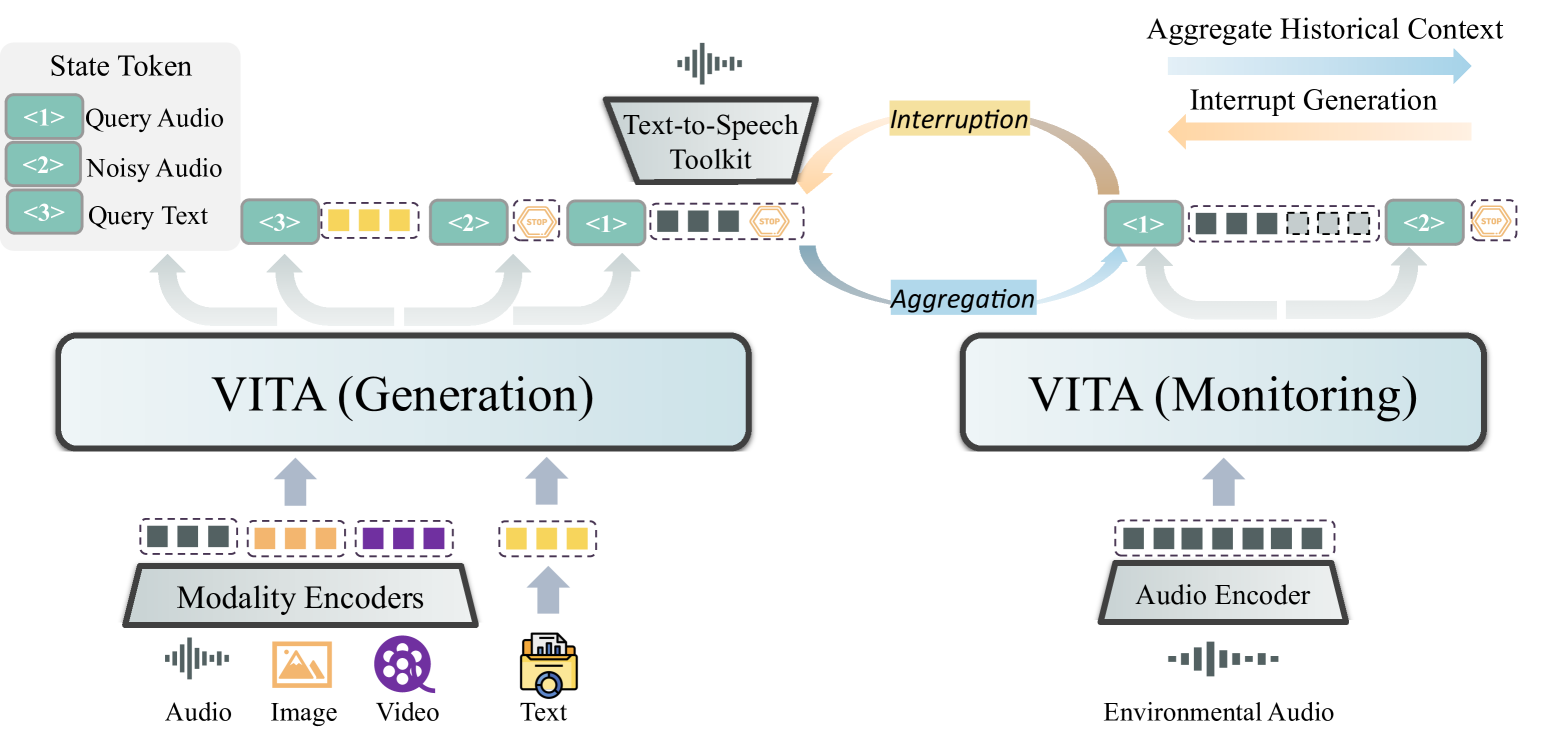
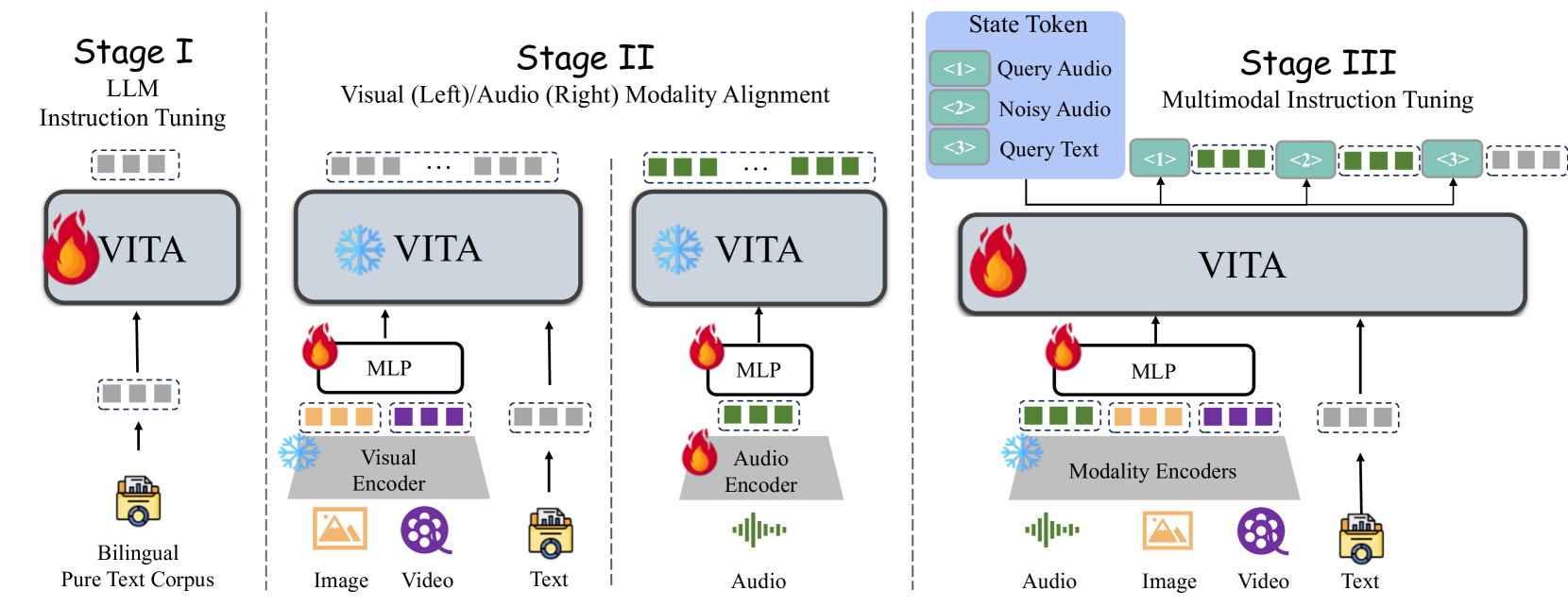
技术框架:VITA的整体框架包含以下几个主要阶段: 1. 语言基础扩展:基于Mixtral 8x7B,扩展中文词汇,增强其对中文的理解能力。 2. 双语指令微调:进行双语指令微调,提升模型在多语言环境下的表现。 3. 多模态对齐:通过多任务学习,将视觉和音频信息与语言模型对齐,使其能够理解这些模态的信息。 4. 指令微调:进一步进行指令微调,优化模型的多模态交互能力。
关键创新:VITA的关键创新在于其是首个开源的、能够同时处理视频、图像、文本和音频的全模态多模态大语言模型,并具备先进的交互体验。它通过两阶段多任务学习,有效地将多种模态的信息融合到语言模型中,使其能够理解和生成与这些模态相关的内容。
关键设计:具体的技术细节包括: * 多模态对齐:采用多任务学习,同时优化视觉和音频信息的对齐。 * 指令微调:使用精心设计的指令数据集,提升模型的多模态交互能力。 * 损失函数:针对不同的任务,设计合适的损失函数,以优化模型的训练效果。 * 数据选择:选择高质量的多模态数据,以提升模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
VITA在多项单模态和多模态基准测试中表现出色,证明了其强大的多语言、视觉和音频理解能力。虽然论文中没有给出具体的性能数据和提升幅度,但强调了VITA在多模态人机交互体验方面取得了显著进展,为开源社区探索多模态理解和交互的无缝融合奠定了基础。
🎯 应用场景
VITA的潜在应用领域广泛,包括智能助手、多媒体内容创作、教育、医疗诊断等。例如,它可以用于创建能够理解和响应用户语音和视觉指令的智能助手,辅助医生进行医学影像分析,或者帮助学生进行多媒体学习。VITA的开源特性将促进多模态人工智能技术的发展和普及。
📄 摘要(原文)
The remarkable multimodal capabilities and interactive experience of GPT-4o underscore their necessity in practical applications, yet open-source models rarely excel in both areas. In this paper, we introduce VITA, the first-ever open-source Multimodal Large Language Model (MLLM) adept at simultaneous processing and analysis of Video, Image, Text, and Audio modalities, and meanwhile has an advanced multimodal interactive experience. Starting from Mixtral 8x7B as a language foundation, we expand its Chinese vocabulary followed by bilingual instruction tuning. We further endow the language model with visual and audio capabilities through two-stage multi-task learning of multimodal alignment and instruction tuning. VITA demonstrates robust foundational capabilities of multilingual, vision, and audio understanding, as evidenced by its strong performance across a range of both unimodal and multimodal benchmarks. Beyond foundational capabilities, we have made considerable progress in enhancing the natural multimodal human-computer interaction experience. VITA is the first step for the open-source community to explore the seamless integration of multimodal understanding and interaction. While there is still lots of work to be done on VITA to get close to close-source counterparts, we hope that its role as a pioneer can serve as a cornerstone for subsequent research. Project Page: https://vita-home.github.io.