Handwritten Code Recognition for Pen-and-Paper CS Education
作者: Md Sazzad Islam, Moussa Koulako Bala Doumbouya, Christopher D. Manning, Chris Piech
分类: cs.CV, cs.AI, cs.CY, cs.HC
发布日期: 2024-08-07
🔗 代码/项目: GITHUB
💡 一句话要点
提出结合OCR、缩进识别与语言模型的手写代码识别方法,提升手写CS教育体验。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手写代码识别 光学字符识别 缩进识别 语言模型 计算机科学教育
📋 核心要点
- 现有手写代码识别方法在OCR精度、缩进处理和错误校正方面存在不足,导致识别错误率高,影响代码运行。
- 论文提出结合OCR、缩进识别和语言模型的方法,以及端到端的多模态语言模型,提升手写代码识别的准确性和鲁棒性。
- 实验结果表明,该方法将手写代码识别的错误率从30%降低到5%,显著优于现有技术,且避免了对学生代码的过度修正。
📝 摘要(中文)
本文旨在解决手写代码在计算机科学(CS)教育中的应用难题。手写编程具有专注学习、锻炼思维等优点,尤其适合计算机基础薄弱或缺乏计算机资源的学生。然而,缺乏对手写程序的教学方法和支持软件是一大障碍。手写代码的光学字符识别(OCR)极具挑战,细微的OCR错误会导致代码无法运行,且缩进识别对于Python等语言至关重要,但手写代码的水平间距不一致使其难以实现。本文提出两种创新方法:一是将OCR与缩进识别模块和语言模型相结合,用于OCR后错误校正,避免引入幻觉,该方法优于现有系统,将错误率从现有技术的30%降低到5%,且对学生程序的逻辑修复极少;二是利用多模态语言模型以端到端的方式识别手写程序。我们希望这项研究能促进教学研究,并为实现CS教育的普及做出贡献。我们发布了一个手写程序和代码数据集,以支持未来的研究,地址为https://github.com/mdoumbouya/codeocr。
🔬 方法详解
问题定义:论文旨在解决手写代码识别在计算机科学教育中的难题。现有方法在处理手写代码时,OCR精度不高,难以准确识别缩进,且在错误校正过程中容易引入不必要的修改,导致学生代码的逻辑被改变。这些问题严重影响了手写代码在教学中的应用。
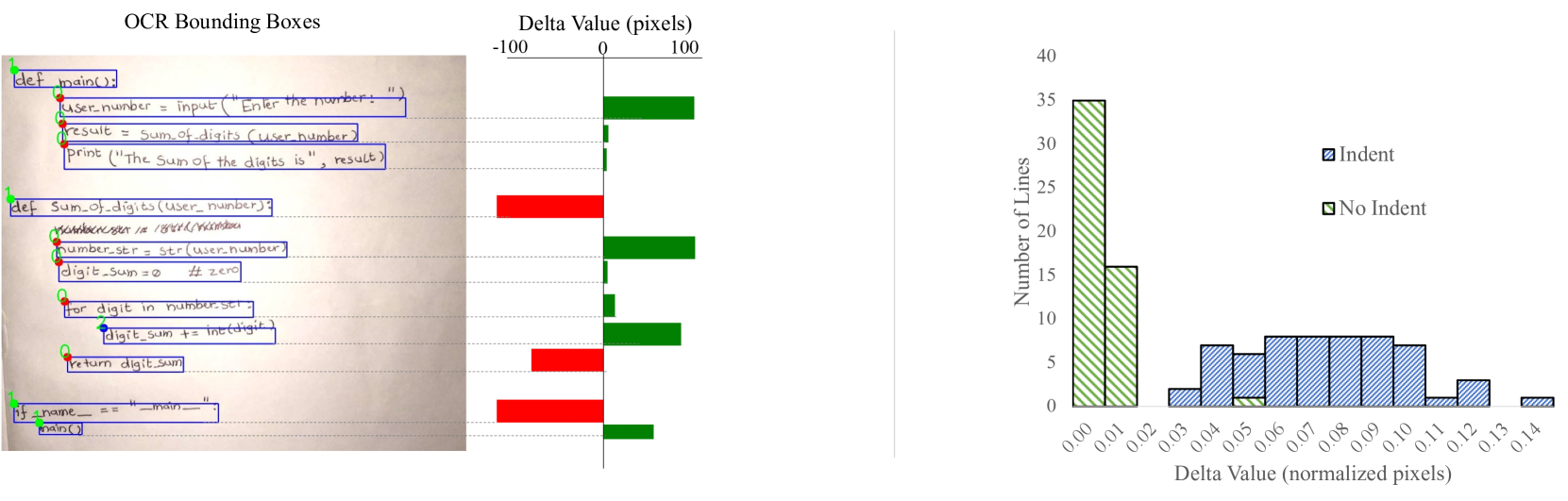
核心思路:论文的核心思路是结合传统OCR技术与语言模型,并针对手写代码的特点进行优化。通过加入缩进识别模块,提高对Python等依赖缩进的语言的识别准确率。同时,利用语言模型进行后处理,纠正OCR错误,并避免引入与学生原意不符的修改。
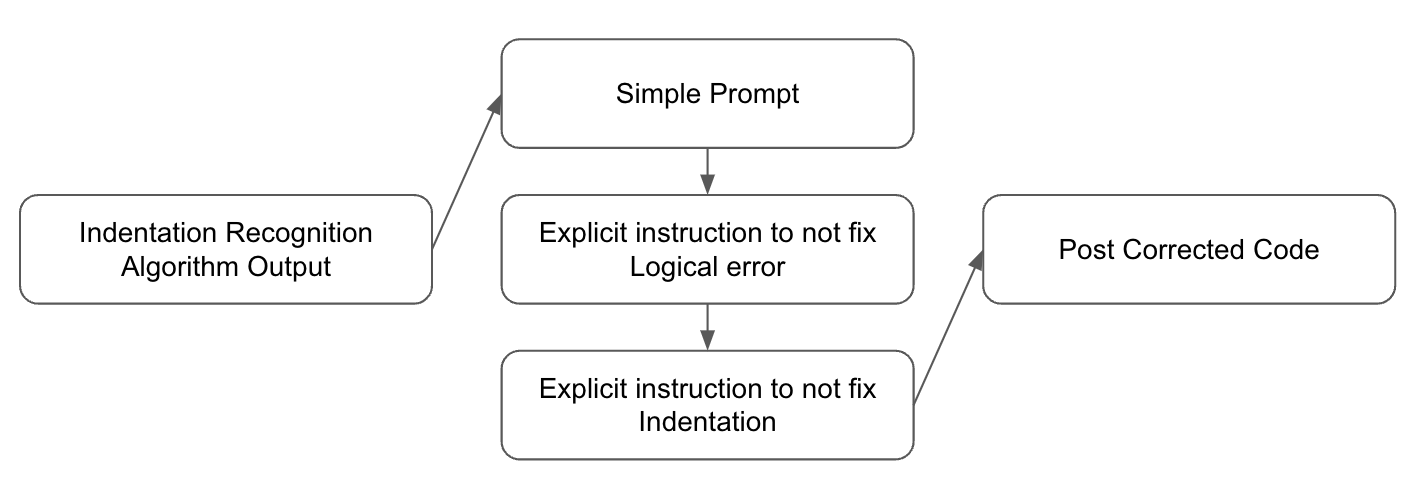
技术框架:论文提出了两种方法。第一种方法包含三个主要模块:OCR模块、缩进识别模块和语言模型。OCR模块负责将手写代码图像转换为文本;缩进识别模块分析代码的缩进结构;语言模型则用于校正OCR错误,并保证代码的语法正确性。第二种方法是使用端到端的多模态语言模型,直接从图像中识别代码。
关键创新:论文的关键创新在于将缩进识别模块与语言模型相结合,用于手写代码的OCR后处理。这种方法能够有效地纠正OCR错误,并保证代码的缩进结构正确。此外,论文还提出了避免引入“幻觉”的错误校正策略,即尽量减少对学生代码逻辑的修改。
关键设计:在第一种方法中,缩进识别模块的设计至关重要,需要考虑手写代码中不一致的水平间距。语言模型的选择和训练也需要针对手写代码的特点进行优化,以提高错误校正的准确性。在第二种方法中,多模态语言模型的结构和训练方式是关键,需要有效地融合图像信息和文本信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,论文提出的方法在手写代码识别方面取得了显著的提升。与现有技术相比,错误率从30%降低到5%,大幅提高了识别准确率。同时,该方法能够有效地避免引入“幻觉”,保证了学生代码的逻辑完整性。这些结果表明,该方法具有很强的实用价值。
🎯 应用场景
该研究成果可应用于计算机科学教育领域,特别是针对缺乏计算机资源或计算机基础薄弱的学生。通过自动识别和评估手写代码,教师可以更高效地批改作业,学生可以及时获得反馈。此外,该技术还可以应用于其他手写文档的识别和处理,例如手写笔记、草稿等。
📄 摘要(原文)
Teaching Computer Science (CS) by having students write programs by hand on paper has key pedagogical advantages: It allows focused learning and requires careful thinking compared to the use of Integrated Development Environments (IDEs) with intelligent support tools or "just trying things out". The familiar environment of pens and paper also lessens the cognitive load of students with no prior experience with computers, for whom the mere basic usage of computers can be intimidating. Finally, this teaching approach opens learning opportunities to students with limited access to computers. However, a key obstacle is the current lack of teaching methods and support software for working with and running handwritten programs. Optical character recognition (OCR) of handwritten code is challenging: Minor OCR errors, perhaps due to varied handwriting styles, easily make code not run, and recognizing indentation is crucial for languages like Python but is difficult to do due to inconsistent horizontal spacing in handwriting. Our approach integrates two innovative methods. The first combines OCR with an indentation recognition module and a language model designed for post-OCR error correction without introducing hallucinations. This method, to our knowledge, surpasses all existing systems in handwritten code recognition. It reduces error from 30\% in the state of the art to 5\% with minimal hallucination of logical fixes to student programs. The second method leverages a multimodal language model to recognize handwritten programs in an end-to-end fashion. We hope this contribution can stimulate further pedagogical research and contribute to the goal of making CS education universally accessible. We release a dataset of handwritten programs and code to support future research at https://github.com/mdoumbouya/codeocr