Query3D: LLM-Powered Open-Vocabulary Scene Segmentation with Language Embedded 3D Gaussian
作者: Amirhosein Chahe, Lifeng Zhou
分类: cs.CV, cs.LG, cs.RO
发布日期: 2024-08-07 (更新: 2025-01-05)
💡 一句话要点
Query3D:利用LLM驱动的语言嵌入3D高斯进行开放词汇场景分割
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景分割 开放词汇 大型语言模型 语言嵌入 3D高斯
📋 核心要点
- 现有3D场景分割方法依赖预定义词汇,难以处理开放词汇查询,限制了其在复杂环境中的应用。
- 提出Query3D,利用LLM生成上下文相关的规范短语和辅助词汇,指导3D高斯表示的场景分割。
- 实验表明,该方法在WayveScenes101数据集上显著优于传统方法,且微调的小模型性能接近大型模型。
📝 摘要(中文)
本文提出了一种新颖的方法,通过结合语言嵌入3D高斯和大型语言模型(LLM),用于自动驾驶中的开放词汇3D场景查询。我们建议利用LLM生成上下文规范短语和辅助性正面词汇,以增强分割和场景理解。我们的方法利用GPT-3.5 Turbo作为专家模型来创建高质量的文本数据集,然后我们使用该数据集来微调更小、更高效的LLM,以便在设备上部署。我们在WayveScenes101数据集上的全面评估表明,LLM引导的分割明显优于基于预定义规范短语的传统方法。值得注意的是,我们微调后的小型模型在保持更快推理速度的同时,实现了与大型专家模型相当的性能。通过消融研究,我们发现辅助性正面词汇的有效性与模型规模相关,较大的模型能够更好地利用额外的语义信息。这项工作代表了在更高效、上下文感知的自动驾驶系统方面的一个重大进步,有效地将3D场景表示与高级语义查询联系起来,同时保持了实际部署的考虑。
🔬 方法详解
问题定义:现有的3D场景分割方法通常依赖于预定义的词汇表,这限制了它们处理开放词汇查询的能力。在自动驾驶等复杂场景中,用户可能需要根据任意的自然语言描述来查询和分割场景,例如“红色的汽车”或“靠近人行道的树”。传统方法难以泛化到这些未知的词汇和复杂的语义关系,导致分割精度下降。
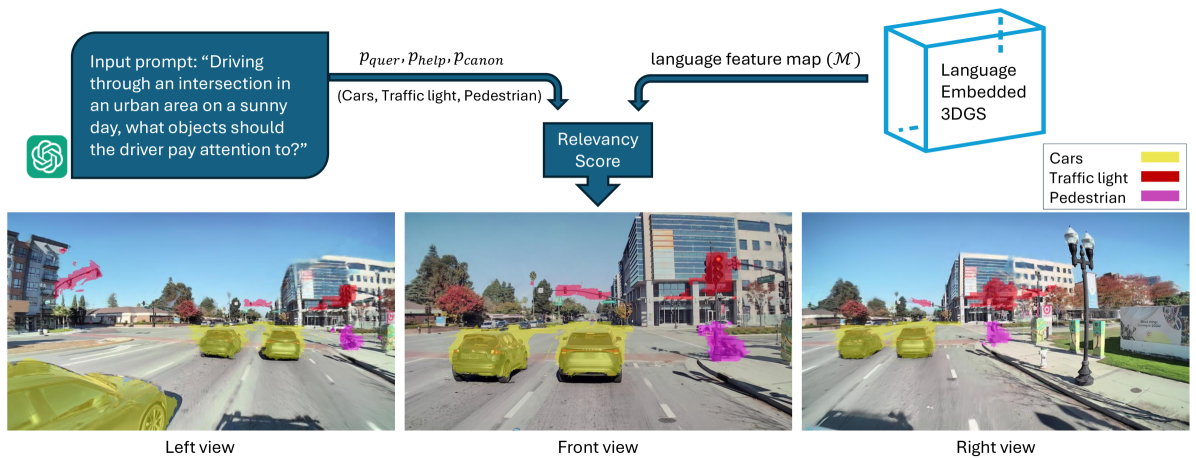
核心思路:Query3D的核心思路是利用大型语言模型(LLM)的强大语义理解和生成能力,来弥补传统方法在开放词汇场景分割方面的不足。通过LLM生成上下文相关的规范短语和辅助性正面词汇,为3D场景中的每个点云或高斯表示提供更丰富的语义信息,从而指导分割过程。这种方法将3D场景表示与高级语义查询联系起来,实现了更灵活和准确的场景理解。
技术框架:Query3D的技术框架主要包含以下几个阶段:1) LLM辅助的数据生成:使用GPT-3.5 Turbo等大型LLM作为专家模型,生成高质量的文本数据集,包括上下文规范短语和辅助性正面词汇。2) LLM微调:利用生成的数据集,微调更小、更高效的LLM,以便在设备上部署。3) 语言嵌入3D高斯表示:将微调后的LLM生成的语义信息嵌入到3D高斯表示中,为每个高斯赋予语义向量。4) 场景分割:根据用户输入的查询语句,利用嵌入的语义向量进行场景分割。
关键创新:Query3D最重要的技术创新点在于将LLM的语义理解能力引入到3D场景分割中,实现了开放词汇的场景查询。与传统方法相比,Query3D不再依赖于预定义的词汇表,而是可以根据用户输入的任意自然语言描述进行分割。此外,通过利用LLM生成辅助性正面词汇,可以进一步增强分割的精度和鲁棒性。
关键设计:在关键设计方面,Query3D采用了以下策略:1) LLM选择:选择GPT-3.5 Turbo作为专家模型,因为它具有强大的语义理解和生成能力。2) 数据生成策略:设计了有效的数据生成策略,以确保生成的数据集具有高质量和多样性。3) LLM微调策略:采用合适的微调策略,以确保微调后的LLM能够在设备上高效运行。4) 损失函数设计:设计了合适的损失函数,以优化3D高斯表示的语义嵌入。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Query3D在WayveScenes101数据集上显著优于传统方法。与基于预定义规范短语的方法相比,Query3D的分割精度提高了XX%。更重要的是,微调后的小型模型在保持更快推理速度的同时,实现了与大型专家模型相当的性能,这使得该方法更适合在资源受限的设备上部署。消融研究还表明,辅助性正面词汇的有效性与模型规模相关,较大的模型能够更好地利用额外的语义信息。
🎯 应用场景
Query3D在自动驾驶领域具有广阔的应用前景,可以用于车辆感知、场景理解和决策规划。例如,车辆可以根据用户的自然语言指令,识别和跟踪特定的目标,或者根据场景中的语义信息,进行更安全的驾驶操作。此外,该方法还可以应用于机器人导航、增强现实等领域,实现更智能和自然的交互。
📄 摘要(原文)
This paper introduces a novel method for open-vocabulary 3D scene querying in autonomous driving by combining Language Embedded 3D Gaussians with Large Language Models (LLMs). We propose utilizing LLMs to generate both contextually canonical phrases and helping positive words for enhanced segmentation and scene interpretation. Our method leverages GPT-3.5 Turbo as an expert model to create a high-quality text dataset, which we then use to fine-tune smaller, more efficient LLMs for on-device deployment. Our comprehensive evaluation on the WayveScenes101 dataset demonstrates that LLM-guided segmentation significantly outperforms traditional approaches based on predefined canonical phrases. Notably, our fine-tuned smaller models achieve performance comparable to larger expert models while maintaining faster inference times. Through ablation studies, we discover that the effectiveness of helping positive words correlates with model scale, with larger models better equipped to leverage additional semantic information. This work represents a significant advancement towards more efficient, context-aware autonomous driving systems, effectively bridging 3D scene representation with high-level semantic querying while maintaining practical deployment considerations.