One Framework to Rule Them All: Unifying Multimodal Tasks with LLM Neural-Tuning
作者: Hao Sun, Yu Song, Jiaqing Liu, Jihong Hu, Yen-Wei Chen, Lanfen Lin
分类: cs.CV, cs.MM
发布日期: 2024-08-06 (更新: 2025-08-25)
💡 一句话要点
提出基于LLM神经元调优的统一多模态框架,解决多任务通用性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 多任务学习 大型语言模型 神经元调优 统一框架 MMUD基准 稀疏表示
📋 核心要点
- 现有大模型在多模态任务中缺乏通用性,需要针对特定任务或场景进行定制化调优。
- 提出统一框架,将所有模态和任务表示为统一的tokens,并采用神经元调优策略。
- 构建MMUD基准测试,实验证明该方法能够高效处理多任务,并公开模型、代码和数据集。
📝 摘要(中文)
大规模模型在自动化医疗服务和智能客户支持等领域展现了卓越能力。然而,由于大多数大型模型都在单模态语料库上训练,因此使其能够有效地处理和理解多模态信号仍然是一个重大挑战。目前的研究通常侧重于设计特定于任务或特定于场景的调优策略,这限制了可扩展性和通用性。为了解决这个限制,我们提出了一个统一的框架,可以同时处理多个任务和模态。在这个框架中,所有模态和任务都表示为统一的tokens,并使用单一、一致的方法进行训练。为了实现高效的多任务处理,我们引入了一种新的调优策略,称为神经元调优,其灵感来自人脑中稀疏分布式表示的概念,其中只有特定的神经元子集被激活用于每个任务。此外,为了推进多模态和多任务学习的研究,我们提出了一个新的基准MMUD,其中包括带有多个任务标签的样本,涵盖推理分割、指代分割、图像描述和文本到图像生成。通过在MMUD基准上将神经元调优应用于预训练的大型模型,我们证明了以简化和高效的方式同时处理多个任务的能力。所有模型、代码和数据集将在发布后公开,从而促进该领域的进一步研究和创新。
🔬 方法详解
问题定义:现有的大型模型主要在单模态数据上进行训练,难以有效处理和理解多模态信息。针对特定任务或场景的微调策略限制了模型的可扩展性和通用性,需要一种能够同时处理多个任务和模态的统一框架。
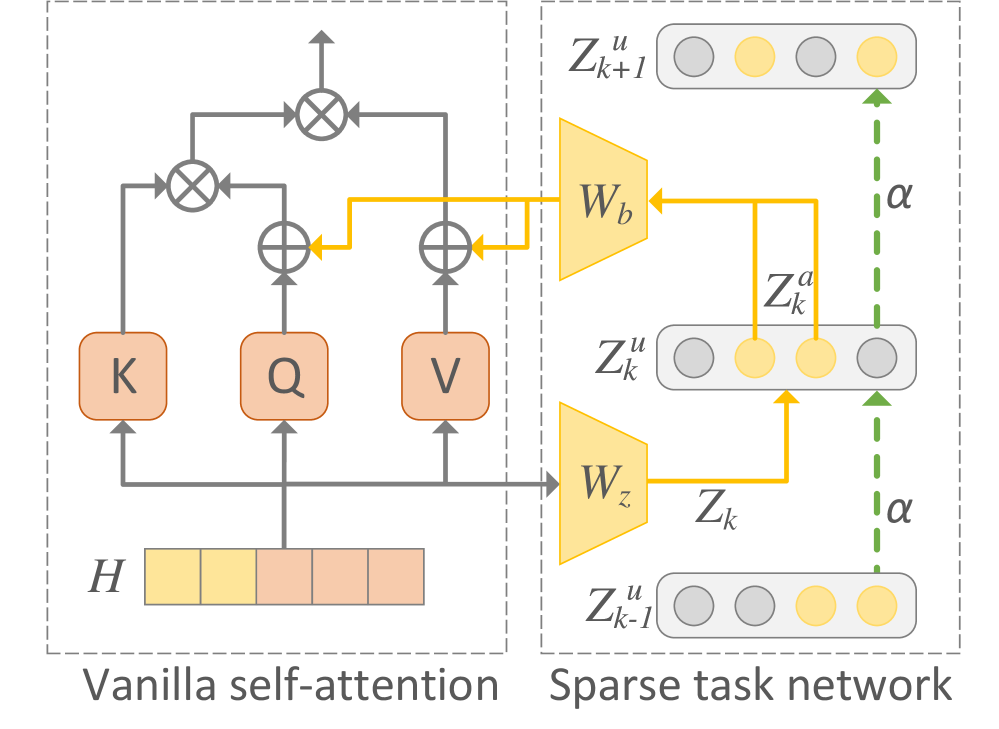
核心思路:论文的核心思路是将所有模态和任务都表示为统一的tokens,并使用单一、一致的方法进行训练。借鉴人脑中稀疏分布式表示的思想,提出了神经元调优策略,即只激活特定神经元子集来处理特定任务,从而实现高效的多任务处理。
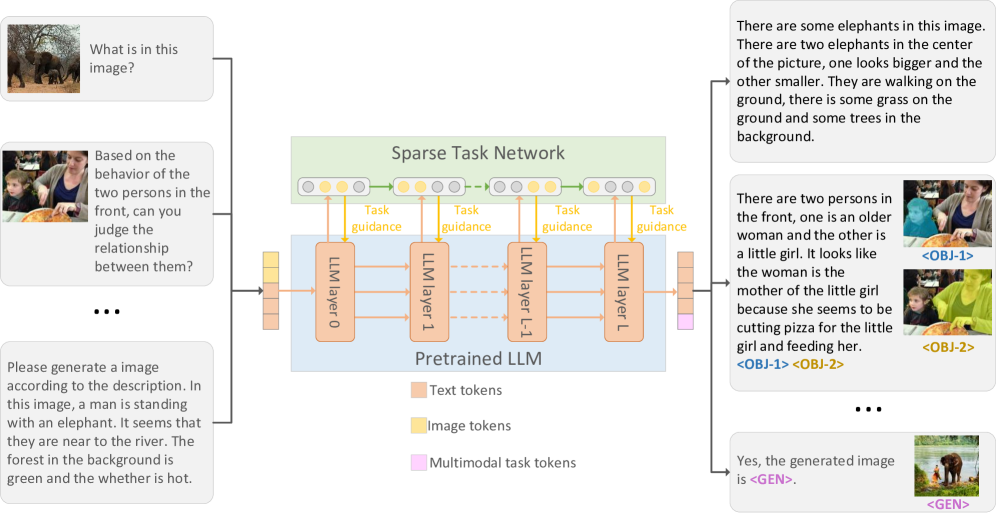
技术框架:该框架包含以下主要模块:1) 多模态输入编码:将不同模态的数据(如图像、文本)编码为统一的tokens表示。2) 预训练大型模型:使用预训练的语言模型作为 backbone。3) 神经元调优:针对不同任务,选择性地激活预训练模型中的特定神经元子集。4) 多任务解码:将激活的神经元输出解码为对应任务的结果(如图像描述、图像生成)。
关键创新:最重要的技术创新点是神经元调优策略。与传统的微调方法不同,神经元调优只更新模型中的一部分参数,从而降低了计算成本,并提高了模型的泛化能力。此外,统一的token表示方法使得模型能够灵活地处理不同模态和任务的组合。
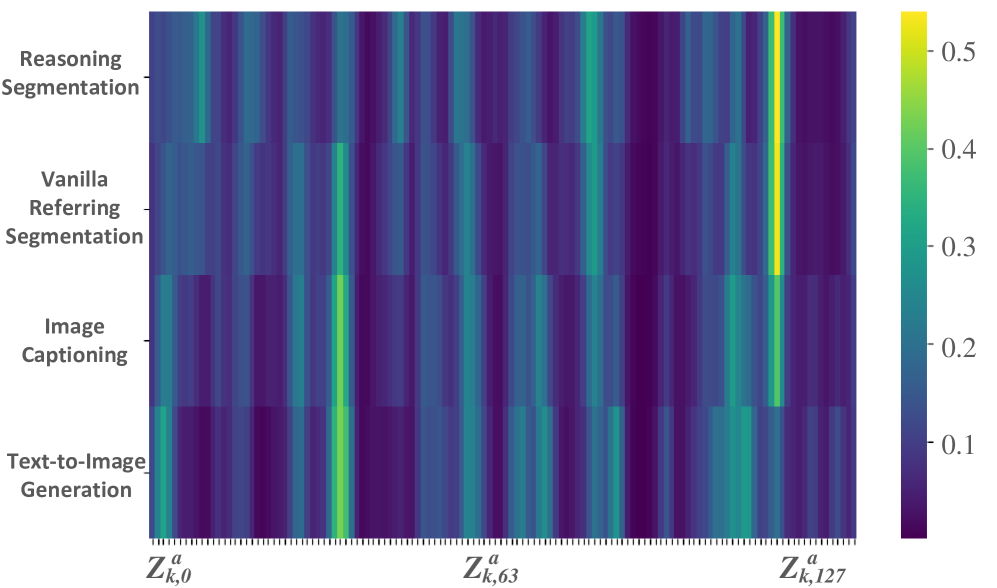
关键设计:神经元调优的关键设计在于如何选择激活的神经元子集。论文中可能采用了某种稀疏激活函数或选择机制,例如基于任务类型和输入模态的注意力机制来确定激活的神经元。损失函数的设计需要考虑不同任务之间的平衡,例如采用加权损失或多任务学习的损失函数。
🖼️ 关键图片
📊 实验亮点
论文提出了MMUD多模态多任务基准,并在该基准上验证了神经元调优方法的有效性。实验结果表明,该方法能够在多个任务上取得良好的性能,并且具有较高的计算效率。具体的性能数据和对比基线将在论文发表后公开。
🎯 应用场景
该研究成果可应用于智能客服、自动驾驶、医疗诊断等领域。例如,在智能客服中,模型可以同时理解用户的语音和图像输入,并根据用户的需求提供个性化的服务。在自动驾驶中,模型可以融合摄像头、激光雷达等多种传感器的数据,从而提高环境感知能力。在医疗诊断中,模型可以结合病人的影像资料和病历信息,辅助医生进行诊断。
📄 摘要(原文)
Large-scale models have exhibited remarkable capabilities across diverse domains, including automated medical services and intelligent customer support. However, as most large models are trained on single-modality corpora, enabling them to effectively process and understand multimodal signals remains a significant challenge. Current research often focuses on designing task-specific or scenario-specific tuning strategies, which limits the scalability and versatility. To address this limitation, we propose a unified framework that concurrently handles multiple tasks and modalities. In this framework, all modalities and tasks are represented as unified tokens and trained using a single, consistent approach. To enable efficient multitask processing, we introduce a novel tuning strategy termed neural tuning, inspired by the concept of sparse distributed representation in the human brain, where only specific subsets of neurons are activated for each task. Furthermore, to advance research in multimodal and multitask learning, we present a new benchmark, MMUD, which includes samples annotated with multiple task labels spanning reasoning segmentation, referring segmentation, image captioning, and text-to-image generation. By applying neural tuning to pretrained large models on the MMUD benchmark, we demonstrate the ability to handle multiple tasks simultaneously in a streamlined and efficient manner. All models, code, and datasets will be released publicly upon publication, fostering further research and innovation in this field.