WWW: Where, Which and Whatever Enhancing Interpretability in Multimodal Deepfake Detection
作者: Juho Jung, Sangyoun Lee, Jooeon Kang, Yunjin Na
分类: cs.CV
发布日期: 2024-08-06
备注: 4 pages, 2 figures, 2 tables, Accepted as Oral Presentation at The Trustworthy AI Workshop @ IJCAI 2024
💡 一句话要点
提出FakeMix基准与新指标,提升多模态Deepfake检测在动态场景下的可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态Deepfake检测 片段级检测 动态Deepfake 可解释性 评估基准 时间准确率 帧级判别指标
📋 核心要点
- 现有Deepfake检测基准侧重于全局篡改,难以应对真实场景中动态、细粒度的篡改。
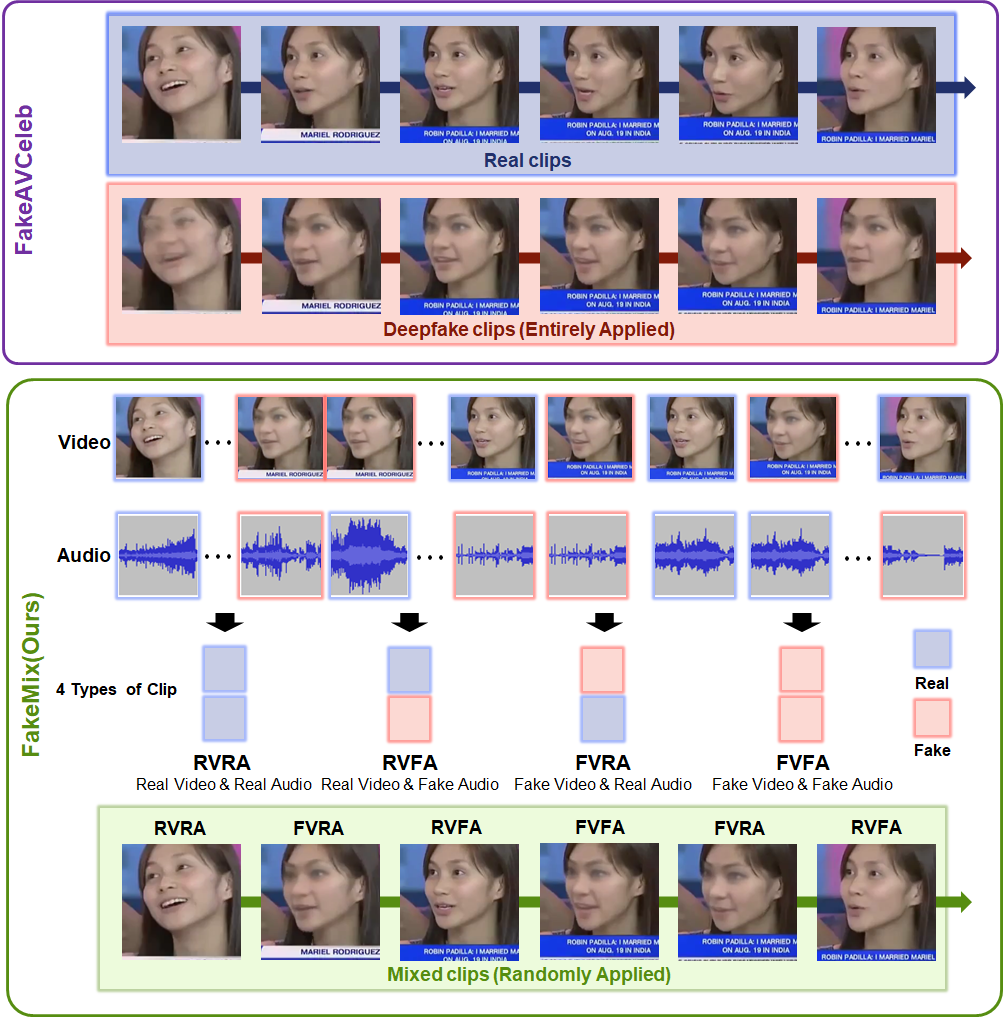
- 提出FakeMix片段级基准,关注视频和音频中被篡改的片段,以提升检测的可解释性。
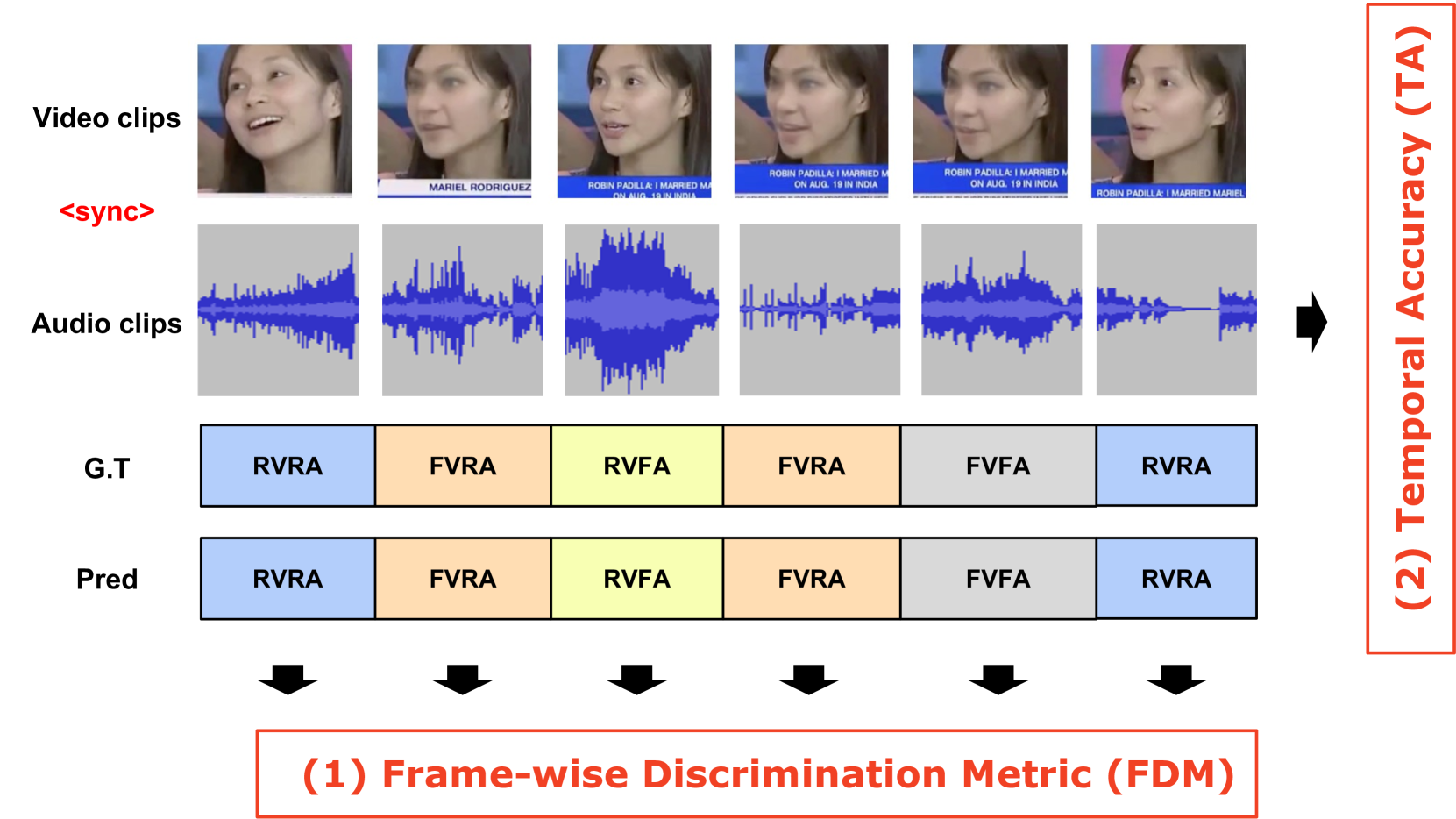
- 引入时间准确率(TA)和帧级判别指标(FDM),更全面地评估Deepfake检测模型的鲁棒性。
📝 摘要(中文)
当前多模态Deepfake检测基准主要通过各种生成技术操纵整个视频帧,导致视频级分类准确率过高,超过94%。然而,这些基准难以检测真实场景中逐帧修改的动态Deepfake攻击。为了解决这一局限性,我们提出了FakeMix,一种新的片段级评估基准,旨在识别视频和音频中被篡改的部分,从而深入了解Deepfake的来源。此外,我们提出了新的评估指标,即时间准确率(TA)和帧级判别指标(FDM),以评估Deepfake检测模型的鲁棒性。通过在各种Deepfake基准(特别是FakeMix)上评估最先进的模型,全面展示了我们方法的有效性。具体而言,虽然在视频级实现了94.2%的平均精度(AP),但使用所提出的指标TA和FDM在片段级评估现有模型时,准确率分别急剧下降至53.1%和52.1%。
🔬 方法详解
问题定义:现有Deepfake检测方法和基准主要关注对整个视频帧的篡改,在视频级别的分类任务上取得了很高的准确率。然而,在实际应用中,Deepfake攻击往往是动态的、细粒度的,例如逐帧修改视频内容。现有的方法和基准难以有效地检测和定位这些动态的Deepfake攻击,并且缺乏对模型可解释性的考量。
核心思路:为了解决上述问题,论文提出了FakeMix基准,该基准关注视频和音频片段级别的篡改检测,旨在识别视频和音频中被篡改的部分。同时,论文还提出了时间准确率(TA)和帧级判别指标(FDM)来更全面地评估Deepfake检测模型的性能,特别是其在时间维度上的鲁棒性和判别能力。
技术框架:FakeMix基准的构建过程未知,但其核心思想是提供片段级别的Deepfake检测任务。评估过程使用时间准确率(TA)和帧级判别指标(FDM)。时间准确率(TA)衡量模型在时间维度上正确识别篡改片段的能力。帧级判别指标(FDM)衡量模型区分真实帧和伪造帧的能力。
关键创新:论文的关键创新在于提出了FakeMix片段级基准和新的评估指标(TA和FDM)。FakeMix基准更贴近实际的Deepfake攻击场景,能够更好地评估模型在动态、细粒度篡改下的性能。TA和FDM指标能够更全面地评估模型的鲁棒性和判别能力,弥补了传统视频级分类准确率的不足。
关键设计:FakeMix基准的具体构建方法未知,但可以推测其可能涉及到对真实视频和音频片段进行各种Deepfake篡改操作,并标注篡改片段的起始时间和结束时间。TA和FDM指标的具体计算公式未知,但TA应该与模型正确识别篡改片段的时间比例有关,FDM应该与模型区分真实帧和伪造帧的置信度差异有关。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有最先进的模型在视频级分类任务上取得了94.2%的平均精度(AP),但在FakeMix片段级基准上,使用时间准确率(TA)和帧级判别指标(FDM)评估时,准确率分别下降至53.1%和52.1%。这表明现有模型在应对动态、细粒度Deepfake攻击时存在明显的不足,突显了FakeMix基准和新指标的价值。
🎯 应用场景
该研究成果可应用于社交媒体平台、新闻媒体机构等,用于检测和识别Deepfake内容,防止虚假信息的传播和恶意攻击。通过片段级别的检测,可以更精确地定位篡改内容,提高Deepfake检测的可信度和可解释性。未来,该研究可以进一步扩展到更复杂的Deepfake攻击场景,并与其他安全技术相结合,构建更强大的Deepfake防御体系。
📄 摘要(原文)
All current benchmarks for multimodal deepfake detection manipulate entire frames using various generation techniques, resulting in oversaturated detection accuracies exceeding 94% at the video-level classification. However, these benchmarks struggle to detect dynamic deepfake attacks with challenging frame-by-frame alterations presented in real-world scenarios. To address this limitation, we introduce FakeMix, a novel clip-level evaluation benchmark aimed at identifying manipulated segments within both video and audio, providing insight into the origins of deepfakes. Furthermore, we propose novel evaluation metrics, Temporal Accuracy (TA) and Frame-wise Discrimination Metric (FDM), to assess the robustness of deepfake detection models. Evaluating state-of-the-art models against diverse deepfake benchmarks, particularly FakeMix, demonstrates the effectiveness of our approach comprehensively. Specifically, while achieving an Average Precision (AP) of 94.2% at the video-level, the evaluation of the existing models at the clip-level using the proposed metrics, TA and FDM, yielded sharp declines in accuracy to 53.1%, and 52.1%, respectively.