MedTrinity-25M: A Large-scale Multimodal Dataset with Multigranular Annotations for Medicine
作者: Yunfei Xie, Ce Zhou, Lang Gao, Juncheng Wu, Xianhang Li, Hong-Yu Zhou, Sheng Liu, Lei Xing, James Zou, Cihang Xie, Yuyin Zhou
分类: cs.CV
发布日期: 2024-08-06 (更新: 2025-07-10)
备注: The dataset is publicly available at https://yunfeixie233.github.io/MedTrinity-25M/. Accepted to ICLR 2025
💡 一句话要点
MedTrinity-25M:大规模多模态医学数据集,支持多粒度标注与医学AI模型预训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学影像 多模态学习 大型数据集 视觉问答 自然语言处理 医学AI ROI分析 自动化标注
📋 核心要点
- 现有医学多模态数据集规模有限,且缺乏细粒度的标注信息,限制了医学AI模型的发展。
- 论文提出MedTrinity-25M,通过自动化流程生成多粒度视觉和文本标注,构建大规模医学多模态数据集。
- 实验表明,基于MedTrinity-25M预训练的LLaVA-Tri模型在多个医学VQA任务上取得了SOTA性能。
📝 摘要(中文)
本文介绍了MedTrinity-25M,一个全面的、大规模的多模态医学数据集,涵盖10种模态的超过2500万张图像,并为超过65种疾病提供多粒度标注。这些多粒度标注包括全局信息(如模态和器官检测)和局部信息(如ROI分析、病灶纹理和区域相关性)。与现有的多模态数据集受限于图像-文本对的可用性不同,我们开发了第一个自动化的流程,通过生成图像-ROI-描述三元组形式的多粒度视觉和文本标注来扩展多模态数据,而无需任何配对的文本描述。具体来说,我们收集、预处理并使用领域专家模型对来自30多个不同来源的数据进行grounding,以识别与异常区域相关的ROI。然后,我们构建了一个全面的知识库,并提示多模态大型语言模型执行检索增强生成,并将识别出的ROI作为指导,从而生成多粒度文本描述。与现有数据集相比,MedTrinity-25M提供了最丰富的标注,支持全面的多模态任务,如图像描述和报告生成,以及以视觉为中心的任务,如分类和分割。我们通过在MedTrinity-25M上预训练LLaVA,提出了LLaVA-Tri,在VQA-RAD、SLAKE和PathVQA上实现了最先进的性能,超过了具有代表性的SOTA多模态大型语言模型。此外,MedTrinity-25M还可以用于支持多模态医学AI模型的大规模预训练,从而有助于未来医学领域基础模型的发展。我们将公开我们的数据集。
🔬 方法详解
问题定义:现有医学多模态数据集规模较小,标注信息不足,特别是缺乏图像区域级别的细粒度文本描述,这限制了多模态医学AI模型,尤其是大型语言模型在医学领域的应用。现有方法依赖人工标注,成本高昂且难以扩展。
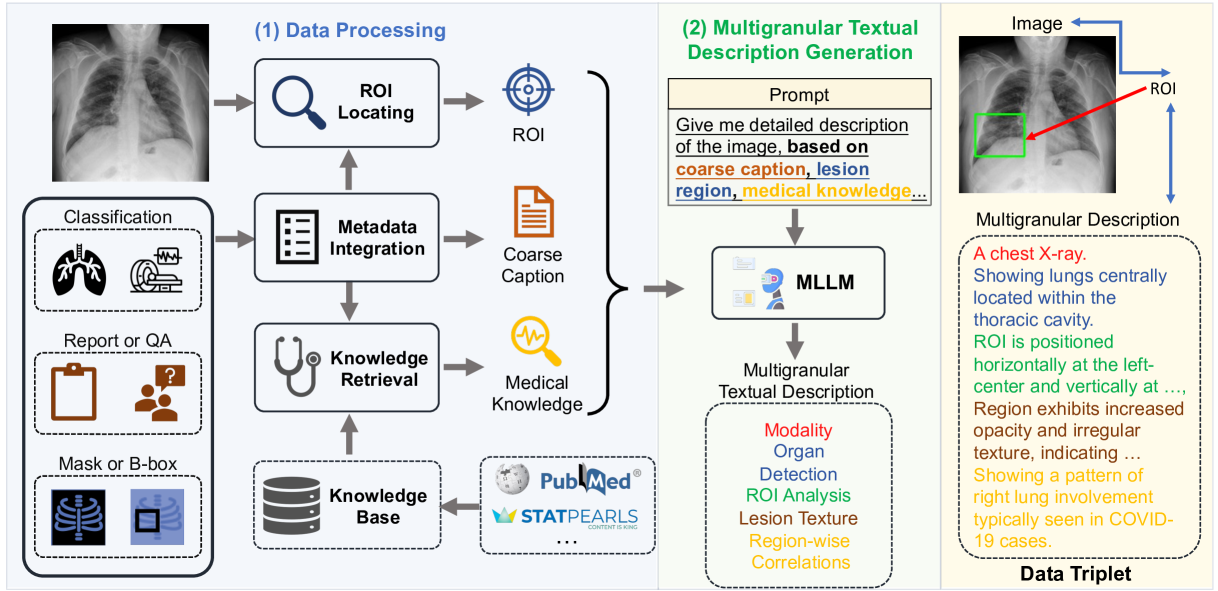
核心思路:论文的核心思路是利用自动化流程,从大规模医学图像数据中提取ROI,并结合医学知识库和多模态大型语言模型,自动生成与ROI相关的多粒度文本描述。通过这种方式,可以低成本、高效地构建大规模、高质量的多模态医学数据集。
技术框架:整体框架包括以下几个主要阶段:1) 数据收集与预处理:从30多个不同来源收集医学图像数据,并进行预处理;2) ROI检测:使用领域专家模型识别与异常区域相关的ROI;3) 知识库构建:构建包含医学术语、疾病信息等的综合知识库;4) 文本描述生成:提示多模态大型语言模型,以ROI为指导,结合知识库进行检索增强生成,生成多粒度文本描述;5) 数据集构建与发布:将图像、ROI和文本描述组合成图像-ROI-描述三元组,构建MedTrinity-25M数据集。
关键创新:最重要的技术创新点在于自动化多粒度标注生成流程。与现有方法依赖人工标注不同,该方法利用领域专家模型和多模态大型语言模型,实现了大规模、低成本的标注生成。此外,该方法生成的标注信息包含全局信息(模态、器官)和局部信息(ROI、病灶纹理),更加全面和细致。
关键设计:在ROI检测阶段,使用了预训练的领域专家模型,例如用于病灶检测的模型。在文本描述生成阶段,使用了多模态大型语言模型(如LLaVA),并结合了检索增强生成技术,以提高生成文本的准确性和相关性。具体prompt的设计对生成文本的质量至关重要,需要根据医学领域的特点进行优化。此外,知识库的构建也需要仔细选择和组织医学知识,以提供有效的检索信息。
🖼️ 关键图片


📊 实验亮点
论文提出的LLaVA-Tri模型在MedTrinity-25M数据集上预训练后,在VQA-RAD、SLAKE和PathVQA等医学视觉问答任务上取得了state-of-the-art的性能,显著超越了现有的多模态大型语言模型。这表明MedTrinity-25M数据集能够有效提升医学AI模型的性能。
🎯 应用场景
MedTrinity-25M数据集可用于训练各种医学AI模型,例如图像分类、分割、报告生成和视觉问答模型。该数据集能够促进医学影像分析、辅助诊断和个性化治疗等领域的发展。未来,基于该数据集训练的医学AI模型有望在临床实践中发挥重要作用,提高医疗效率和质量。
📄 摘要(原文)
This paper introduces MedTrinity-25M, a comprehensive, large-scale multimodal dataset for medicine, covering over 25 million images across 10 modalities with multigranular annotations for more than 65 diseases. These multigranular annotations encompass both global information, such as modality and organ detection, and local information like ROI analysis, lesion texture, and region-wise correlations. Unlike the existing multimodal datasets, which are limited by the availability of image-text pairs, we have developed the first automated pipeline that scales up multimodal data by generating multigranular visual and textual annotations in the form of image-ROI-description triplets without the need for any paired text descriptions. Specifically, data from over 30 different sources have been collected, preprocessed, and grounded using domain-specific expert models to identify ROIs related to abnormal regions. We then build a comprehensive knowledge base and prompt multimodal large language models to perform retrieval-augmented generation with the identified ROIs as guidance, resulting in multigranular textual descriptions. Compared to existing datasets, MedTrinity-25M provides the most enriched annotations, supporting a comprehensive range of multimodal tasks such as captioning and report generation, as well as vision-centric tasks like classification and segmentation. We propose LLaVA-Tri by pretraining LLaVA on MedTrinity-25M, achieving state-of-the-art performance on VQA-RAD, SLAKE, and PathVQA, surpassing representative SOTA multimodal large language models. Furthermore, MedTrinity-25M can also be utilized to support large-scale pre-training of multimodal medical AI models, contributing to the development of future foundation models in the medical domain. We will make our dataset available.