MMIU: Multimodal Multi-image Understanding for Evaluating Large Vision-Language Models
作者: Fanqing Meng, Jin Wang, Chuanhao Li, Quanfeng Lu, Hao Tian, Jiaqi Liao, Xizhou Zhu, Jifeng Dai, Yu Qiao, Ping Luo, Kaipeng Zhang, Wenqi Shao
分类: cs.CV
发布日期: 2024-08-05
备注: Project Page: https://mmiu-bench.github.io/
💡 一句话要点
提出MMIU基准,用于评估大型视觉语言模型在多图理解方面的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多图理解 视觉语言模型 评估基准 多模态学习 空间推理
📋 核心要点
- 现有大型视觉语言模型在处理多图场景时能力不足,缺乏有效的评估基准。
- MMIU基准通过构建包含多种多图关系和任务的综合数据集,实现对LVLM多图理解能力的全面评估。
- 实验表明,现有LVLM在MMIU基准上表现不佳,尤其是在空间理解方面,揭示了模型能力的局限性。
📝 摘要(中文)
本文提出了多模态多图理解(MMIU)基准,旨在全面评估大型视觉语言模型(LVLMs)在多图任务中的能力。MMIU包含7种多图关系、52个任务、7.7万张图像和1.1万个精心设计的多项选择题,是目前同类基准中规模最大的。通过对24个流行的LVLM(包括开源和专有模型)的评估,揭示了它们在多图理解方面的显著挑战,尤其是在涉及空间理解的任务中。即使是GPT-4o等最先进的模型,在MMIU上的准确率也仅为55.7%。通过多方面的分析实验,识别了关键的性能差距和局限性,为未来的模型和数据改进提供了有价值的见解。MMIU旨在推动LVLM研究和发展的前沿,朝着实现复杂的多模态多图用户交互迈进。
🔬 方法详解
问题定义:现有的大型视觉语言模型(LVLMs)在处理需要综合多张图片信息的任务时表现不足。缺乏一个全面、细粒度的评估基准来衡量模型在多图理解方面的能力,尤其是在理解多图之间的关系,例如空间关系、因果关系等方面。现有方法难以准确评估模型在这些复杂场景下的表现,阻碍了多图理解LVLM的进一步发展。
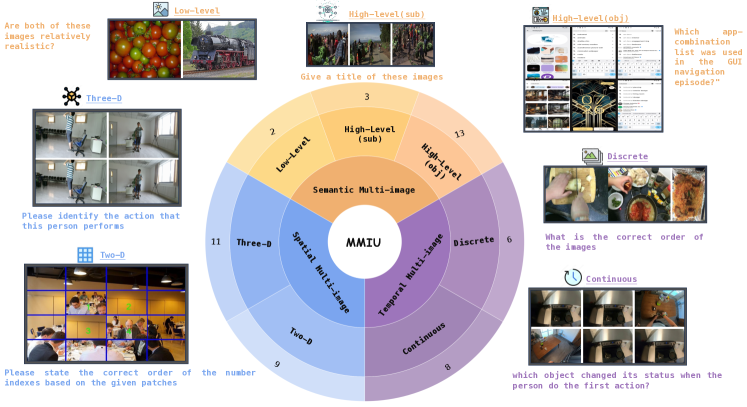
核心思路:MMIU的核心思路是构建一个包含多种多图关系和任务的综合性基准,通过精心设计的多项选择题来评估LVLM对多图场景的理解能力。该基准覆盖了多种多图关系,例如空间关系、时间关系、因果关系、对象关系等,以及多种任务类型,例如视觉问答、场景理解、关系推理等。通过在MMIU上评估LVLM的性能,可以全面了解模型在多图理解方面的优势和不足。
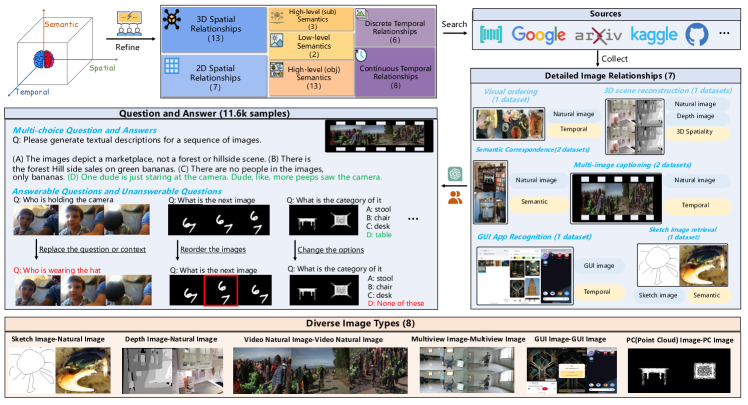
技术框架:MMIU基准主要包含以下几个部分:1) 多图数据集:包含7.7万张图像,涵盖各种场景和对象。2) 多图关系标注:对图像之间的关系进行标注,包括空间关系、时间关系、因果关系等。3) 多项选择题生成:根据图像和关系标注,生成1.1万个多项选择题,用于评估LVLM的理解能力。4) 评估指标:采用准确率作为主要评估指标,衡量LVLM在多项选择题上的表现。
关键创新:MMIU的关键创新在于其全面性和细粒度。它不仅包含了大量图像和问题,而且覆盖了多种多图关系和任务类型。此外,MMIU还采用了精心设计的多项选择题,可以更准确地评估LVLM对多图场景的理解能力。与现有基准相比,MMIU可以更全面地评估LVLM在多图理解方面的能力,并为未来的模型改进提供更有效的指导。
关键设计:MMIU在多项选择题的设计上,采用了多种策略来增加难度和区分度。例如,引入了干扰选项,这些选项在视觉上与正确答案相似,但逻辑上不正确。此外,MMIU还采用了对比学习的方法,通过比较不同模型在同一问题上的表现,来评估模型的相对性能。
🖼️ 关键图片
📊 实验亮点
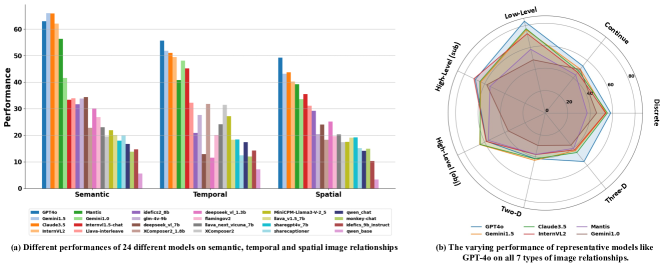
在MMIU基准上,对24个流行的LVLM进行了评估,结果显示,即使是GPT-4o等最先进的模型,在MMIU上的准确率也仅为55.7%。这表明现有LVLM在多图理解方面仍存在显著挑战,尤其是在涉及空间理解的任务中。实验结果还表明,不同模型在不同类型的多图关系上表现差异较大,这为未来的模型改进提供了有价值的线索。
🎯 应用场景
MMIU基准的潜在应用领域包括智能监控、自动驾驶、机器人导航、医学影像分析等。通过提高LVLM在多图理解方面的能力,可以实现更智能、更可靠的视觉系统,例如,在自动驾驶中,可以利用多摄像头信息进行更准确的场景理解和决策。
📄 摘要(原文)
The capability to process multiple images is crucial for Large Vision-Language Models (LVLMs) to develop a more thorough and nuanced understanding of a scene. Recent multi-image LVLMs have begun to address this need. However, their evaluation has not kept pace with their development. To fill this gap, we introduce the Multimodal Multi-image Understanding (MMIU) benchmark, a comprehensive evaluation suite designed to assess LVLMs across a wide range of multi-image tasks. MMIU encompasses 7 types of multi-image relationships, 52 tasks, 77K images, and 11K meticulously curated multiple-choice questions, making it the most extensive benchmark of its kind. Our evaluation of 24 popular LVLMs, including both open-source and proprietary models, reveals significant challenges in multi-image comprehension, particularly in tasks involving spatial understanding. Even the most advanced models, such as GPT-4o, achieve only 55.7% accuracy on MMIU. Through multi-faceted analytical experiments, we identify key performance gaps and limitations, providing valuable insights for future model and data improvements. We aim for MMIU to advance the frontier of LVLM research and development, moving us toward achieving sophisticated multimodal multi-image user interactions.