Lumina-mGPT: Illuminate Flexible Photorealistic Text-to-Image Generation with Multimodal Generative Pretraining
作者: Dongyang Liu, Shitian Zhao, Le Zhuo, Weifeng Lin, Yi Xin, Xinyue Li, Qi Qin, Yu Qiao, Hongsheng Li, Peng Gao
分类: cs.CV
发布日期: 2024-08-05 (更新: 2025-04-24)
备注: Code available at: https://github.com/Alpha-VLLM/Lumina-mGPT
🔗 代码/项目: GITHUB
💡 一句话要点
Lumina-mGPT:基于多模态预训练的灵活逼真文本到图像生成模型
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 多模态预训练 自回归模型 图像表示学习 监督微调
📋 核心要点
- 现有文本到图像生成模型效率较低,且难以灵活控制生成图像的宽高比。
- Lumina-mGPT通过多模态预训练和灵活的渐进式监督微调,实现了高效且可控的图像生成。
- 实验表明,Lumina-mGPT在图像生成、视觉识别和视觉-语言任务上均表现出强大的性能。
📝 摘要(中文)
我们提出了Lumina-mGPT,一个多模态自回归模型家族,能够处理各种视觉和语言任务,尤其擅长从文本描述生成灵活的逼真图像。通过从多模态生成预训练(mGPT)初始化,我们证明了仅解码器的自回归(AR)模型可以通过灵活的渐进式监督微调(FP-SFT)实现与现代扩散模型相当的图像生成性能,同时具有更高的效率。借助我们提出的明确图像表示(UniRep),Lumina-mGPT可以灵活地生成各种宽高比的高质量图像。在强大的图像生成能力的基础上,我们进一步探索了全能监督微调(Omni-SFT),初步尝试将Lumina-mGPT提升为一个统一的多模态通用模型。由此产生的模型展示了通用的多模态能力,包括文本到图像/多视角生成和可控生成等视觉生成任务,分割和深度估计等视觉识别任务,以及多轮视觉问答等视觉-语言任务,展示了该技术方向的光明前景。代码和检查点可在https://github.com/Alpha-VLLM/Lumina-mGPT获得。
🔬 方法详解
问题定义:论文旨在解决文本到图像生成任务中,现有扩散模型生成效率低、难以灵活控制图像宽高比的问题。现有方法通常计算成本高昂,并且在处理不同宽高比的图像时缺乏灵活性。
核心思路:论文的核心思路是利用多模态生成预训练(mGPT)初始化一个decoder-only的自回归模型,并通过灵活的渐进式监督微调(FP-SFT)使其具备强大的图像生成能力。同时,引入明确图像表示(UniRep)来支持不同宽高比的图像生成。
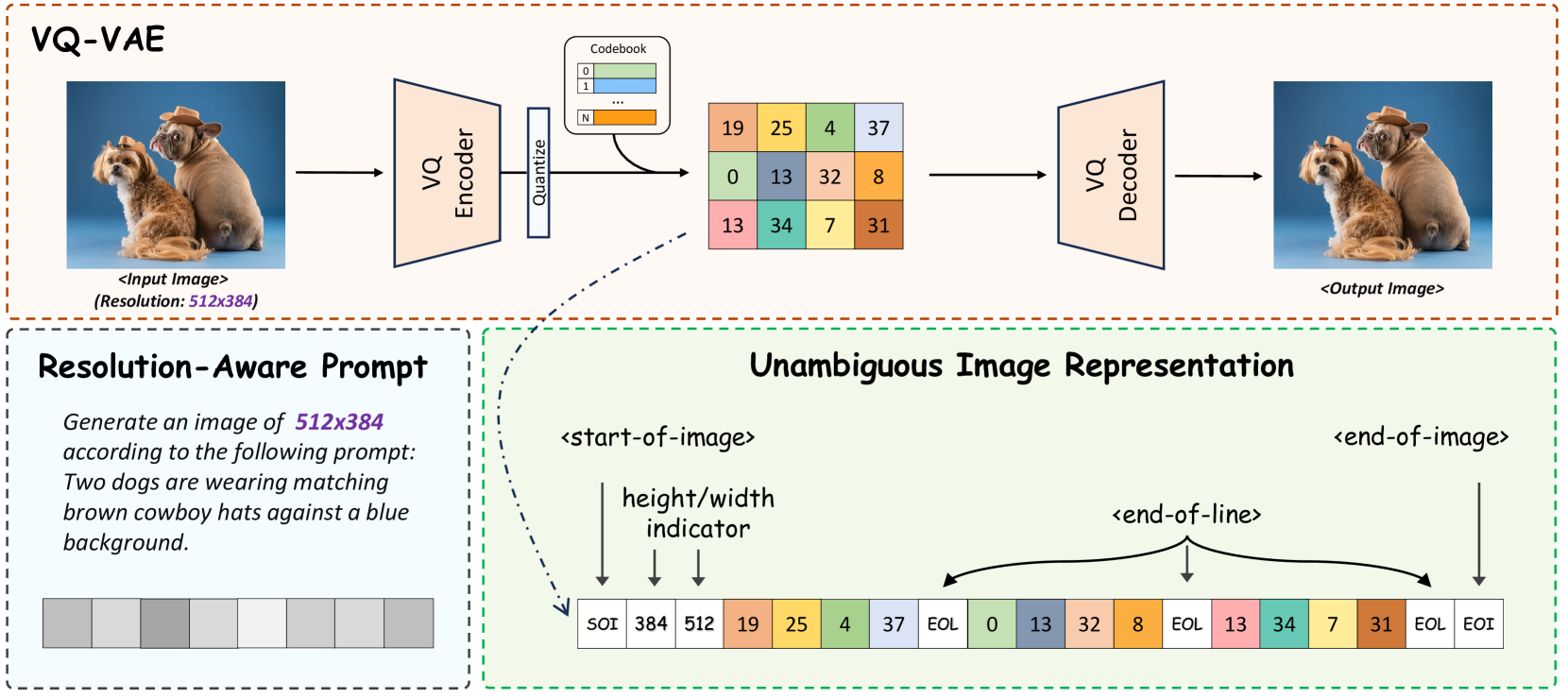
技术框架:Lumina-mGPT的整体框架包括三个主要阶段:1) 多模态生成预训练(mGPT):使用大规模多模态数据预训练一个decoder-only的自回归模型。2) 灵活的渐进式监督微调(FP-SFT):通过逐步增加训练难度和数据量,对预训练模型进行微调,使其具备高质量图像生成能力。3) 全能监督微调(Omni-SFT):进一步微调模型,使其具备处理各种视觉和语言任务的能力。
关键创新:论文的关键创新在于:1) 提出了一种基于decoder-only自回归模型的图像生成方法,该方法具有更高的生成效率。2) 引入了明确图像表示(UniRep),使得模型能够灵活地生成不同宽高比的图像。3) 提出了灵活的渐进式监督微调(FP-SFT)策略,有效地提升了模型的生成质量。
关键设计:UniRep是一种将图像编码为离散token序列的表示方法,它将图像划分为多个patch,并使用一个预训练的视觉tokenizer将每个patch编码为一个token。FP-SFT策略包括多个阶段,每个阶段使用不同难度和数据量的训练数据。Omni-SFT使用混合了各种视觉和语言任务的数据集进行微调,以提升模型的通用能力。
🖼️ 关键图片


📊 实验亮点
Lumina-mGPT在图像生成质量和效率上均取得了显著的提升。通过FP-SFT,模型能够生成与现代扩散模型相当的高质量图像,同时具有更高的生成效率。此外,UniRep使得模型能够灵活地生成各种宽高比的图像,增强了模型的实用性。Omni-SFT的引入使得模型具备了处理各种视觉和语言任务的能力,展示了其作为通用多模态模型的潜力。
🎯 应用场景
Lumina-mGPT具有广泛的应用前景,包括图像编辑、虚拟现实、游戏开发、广告设计等领域。它可以用于生成逼真的图像内容,提升用户体验,并降低内容创作的成本。未来,该技术有望应用于更复杂的场景,例如自动驾驶、机器人导航等。
📄 摘要(原文)
We present Lumina-mGPT, a family of multimodal autoregressive models capable of various vision and language tasks, particularly excelling in generating flexible photorealistic images from text descriptions. By initializing from multimodal Generative PreTraining (mGPT), we demonstrate that decoder-only Autoregressive (AR) model can achieve image generation performance comparable to modern diffusion models with high efficiency through Flexible Progressive Supervised Fine-tuning (FP-SFT). Equipped with our proposed Unambiguous image Representation (UniRep), Lumina-mGPT can flexibly generate high-quality images of varying aspect ratios. Building on the strong image generation capabilities, we further explore Ominiponent Supervised Fine-tuning (Omni-SFT), an initial attempt to elevate Lumina-mGPT into a unified multi-modal generalist. The resulting model demonstrates versatile multimodal capabilities, including visual generation tasks like text-to-image/multiview generation and controllable generation, visual recognition tasks like segmentation and depth estimation, and vision-language tasks like multi-turn visual question answering, showing the rosy potential of the technical direction. Codes and checkpoints are available at https://github.com/Alpha-VLLM/Lumina-mGPT.