LaMamba-Diff: Linear-Time High-Fidelity Diffusion Models Based on Local Attention and Mamba
作者: Yunxiang Fu, Chaoqi Chen, Yizhou Yu
分类: cs.CV
发布日期: 2024-08-05 (更新: 2024-09-19)
🔗 代码/项目: GITHUB
💡 一句话要点
提出LaMamba-Diff,结合局部注意力与Mamba,实现线性复杂度的高保真扩散模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 扩散模型 Mamba 局部注意力 图像生成 线性复杂度 U-Net 视觉生成建模
📋 核心要点
- Transformer扩散模型计算复杂度高,难以处理长序列,而Mamba虽然高效,但会损失局部细节。
- 提出LaMamba块,结合自注意力和Mamba的优势,在线性复杂度下同时捕捉全局上下文和局部细节。
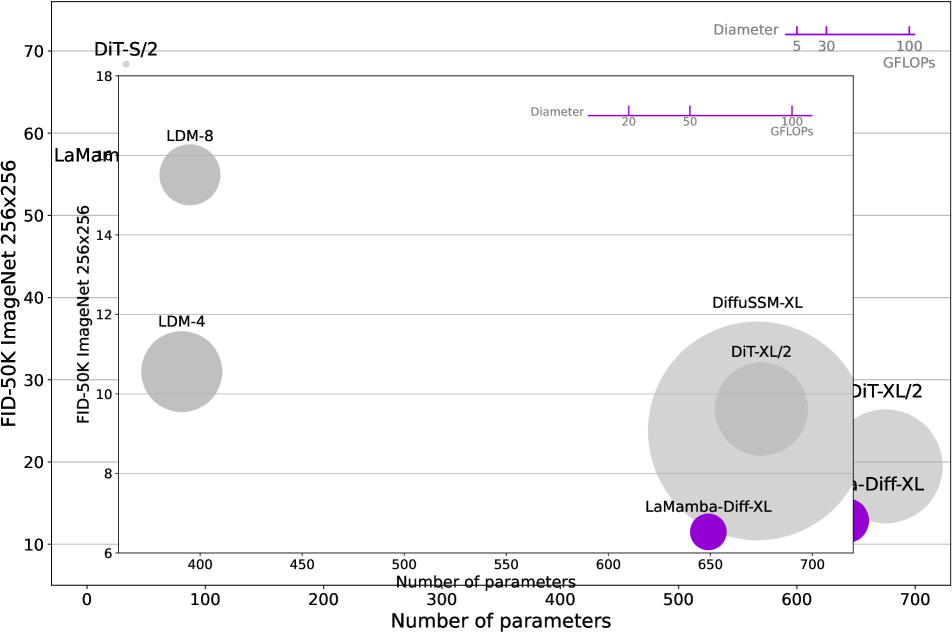
- 实验表明,LaMamba-Diff在ImageNet上超越DiT,且GFLOPs更少,参数量相当,展现出卓越的性能。
📝 摘要(中文)
Transformer-based扩散模型因其自注意力机制能准确捕捉全局和局部上下文而表现出色,但其平方复杂度对长序列输入构成计算挑战。Mamba通过将过滤后的全局上下文压缩到隐藏状态中,提供了线性复杂度,但压缩不可避免地导致细粒度局部依赖关系的信息丢失,这对于有效的视觉生成建模至关重要。为此,我们引入了局部注意力Mamba(LaMamba)块,它结合了自注意力和Mamba的优点,以线性复杂度捕获全局上下文和局部细节。利用高效的U-Net架构,我们的模型表现出卓越的可扩展性,并在256x256分辨率的ImageNet上超越了各种模型规模的DiT的性能,同时使用更少的GFLOPs和相当数量的参数。与ImageNet 256x256和512x512上的最先进扩散模型相比,我们最大的模型具有显著优势,例如与DiT-XL/2相比,GFLOPs减少高达62%,同时以相当或更少的参数实现了卓越的性能。
🔬 方法详解
问题定义:Transformer-based扩散模型在图像生成任务中表现出色,但自注意力机制的计算复杂度是输入序列长度的平方级别,这限制了它们在处理高分辨率图像或长序列数据时的应用。Mamba模型虽然具有线性复杂度,但其全局上下文压缩机制会导致局部细节信息的丢失,影响生成图像的质量。
核心思路:LaMamba-Diff的核心思路是将自注意力机制和Mamba模型的优势结合起来,设计一种新的网络块——LaMamba块。该模块旨在以线性复杂度同时捕获全局上下文和局部细节信息,从而在保证计算效率的同时,提升生成图像的质量。这样设计的目的是为了克服现有方法在计算效率和生成质量之间的trade-off。
技术框架:LaMamba-Diff基于U-Net架构,并用LaMamba块替换了U-Net中的部分或全部自注意力层。整个流程与标准的扩散模型类似,包括前向扩散过程和反向去噪过程。在前向扩散过程中,图像逐渐被加入噪声,直到完全变成噪声图像。在反向去噪过程中,模型逐步去除噪声,最终生成清晰的图像。LaMamba块在U-Net中负责提取图像特征,并指导去噪过程。
关键创新:LaMamba块是该论文最关键的创新点。它通过结合局部注意力和Mamba模型,实现了在线性复杂度下同时捕获全局上下文和局部细节信息。与传统的自注意力机制相比,LaMamba块的计算复杂度更低,更适合处理长序列数据。与纯Mamba模型相比,LaMamba块能够更好地保留局部细节信息,从而提升生成图像的质量。
关键设计:LaMamba块的具体实现细节包括:首先,使用一个小的局部窗口进行自注意力计算,以捕获局部细节信息。然后,使用Mamba模型对全局上下文进行建模。最后,将局部注意力和Mamba模型的输出进行融合,得到最终的特征表示。论文中可能还涉及一些超参数的设置,例如局部窗口的大小、Mamba模型的层数等。损失函数通常采用标准的扩散模型损失函数,例如L2损失或变分下界(VLB)。
🖼️ 关键图片


📊 实验亮点
LaMamba-Diff在ImageNet 256x256分辨率上的实验结果表明,其性能超越了DiT等基线模型,同时GFLOPs显著降低。例如,与DiT-XL/2相比,GFLOPs减少高达62%,且参数量相当或更少。在ImageNet 512x512分辨率上的实验也显示出类似的优势,证明了LaMamba-Diff的有效性和可扩展性。
🎯 应用场景
LaMamba-Diff具有广泛的应用前景,包括图像生成、图像编辑、视频生成等领域。其高效的计算性能使其能够处理高分辨率图像和长视频序列,为相关应用带来新的可能性。该研究的成果也有助于推动扩散模型在实际应用中的普及,例如在艺术创作、游戏开发、医疗影像等领域。
📄 摘要(原文)
Recent Transformer-based diffusion models have shown remarkable performance, largely attributed to the ability of the self-attention mechanism to accurately capture both global and local contexts by computing all-pair interactions among input tokens. However, their quadratic complexity poses significant computational challenges for long-sequence inputs. Conversely, a recent state space model called Mamba offers linear complexity by compressing a filtered global context into a hidden state. Despite its efficiency, compression inevitably leads to information loss of fine-grained local dependencies among tokens, which are crucial for effective visual generative modeling. Motivated by these observations, we introduce Local Attentional Mamba (LaMamba) blocks that combine the strengths of self-attention and Mamba, capturing both global contexts and local details with linear complexity. Leveraging the efficient U-Net architecture, our model exhibits exceptional scalability and surpasses the performance of DiT across various model scales on ImageNet at 256x256 resolution, all while utilizing substantially fewer GFLOPs and a comparable number of parameters. Compared to state-of-the-art diffusion models on ImageNet 256x256 and 512x512, our largest model presents notable advantages, such as a reduction of up to 62% GFLOPs compared to DiT-XL/2, while achieving superior performance with comparable or fewer parameters. Our code is available at https://github.com/yunxiangfu2001/LaMamba-Diff.