CMR-Agent: Learning a Cross-Modal Agent for Iterative Image-to-Point Cloud Registration
作者: Gongxin Yao, Yixin Xuan, Xinyang Li, Yu Pan
分类: cs.CV, cs.RO
发布日期: 2024-08-05
备注: Accepted to IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2024
💡 一句话要点
提出CMR-Agent,用于迭代图像到点云的跨模态配准,提升精度和效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图像到点云配准 跨模态学习 强化学习 迭代优化 相机位姿估计
📋 核心要点
- 现有基于学习的图像到点云配准方法缺乏迭代优化反馈机制,导致精度和可解释性较差。
- CMR-Agent将配准建模为迭代马尔科夫决策过程,通过强化学习进行位姿的增量调整。
- 实验表明,CMR-Agent在KITTI和NuScenes数据集上实现了具有竞争力的精度和效率,单次迭代仅需几毫秒。
📝 摘要(中文)
本文提出了一种用于图像到点云配准的跨模态配准Agent(CMR-Agent),旨在确定RGB图像相对于点云的相机位姿。该方法将配准过程重新建模为一个迭代的马尔可夫决策过程,允许基于每个中间状态对相机位姿进行增量调整。利用强化学习开发CMR-Agent,并使用模仿学习初始化其配准策略,以保证训练的稳定性和快速启动。根据跨模态观测,提出了一种2D-3D混合状态表示,充分利用RGB图像的细粒度特征,同时减少相机视锥空间截断导致的无用中性状态。整体框架设计高效地复用一次性跨模态嵌入,避免重复且耗时的特征提取。在KITTI-Odometry和NuScenes数据集上的大量实验表明,CMR-Agent在配准精度和效率方面都具有竞争力。完成一次性嵌入后,每次迭代仅需几毫秒。
🔬 方法详解
问题定义:图像到点云配准旨在确定RGB图像相对于预构建的LiDAR点云的相机位姿,这是相机定位的关键步骤。现有基于学习的方法主要通过建立2D-3D点对应关系,但缺乏迭代优化机制,导致精度不高,且缺乏可解释性。此外,重复的特征提取也影响了效率。
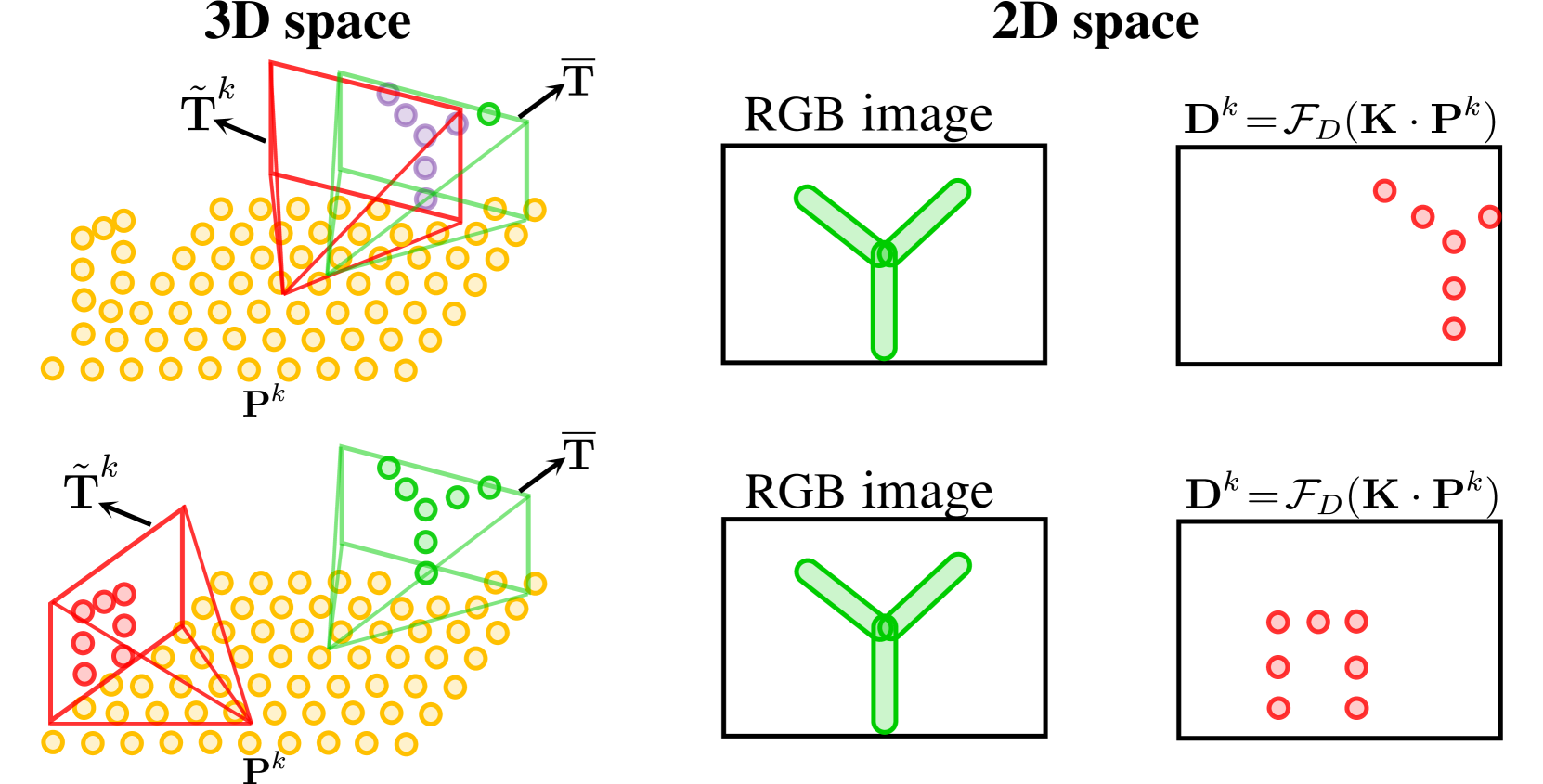
核心思路:将图像到点云的配准过程建模为一个迭代的马尔可夫决策过程(MDP)。通过强化学习训练一个Agent,使其能够根据当前状态(图像和点云的特征)采取行动(调整相机位姿),并获得奖励。这种迭代调整的方式允许逐步优化位姿,提高配准精度。
技术框架:CMR-Agent框架主要包含以下几个模块:1) 跨模态特征提取模块,用于提取RGB图像和点云的特征,并进行融合;2) 状态表示模块,采用2D-3D混合状态表示,融合图像的细粒度特征和点云的几何信息;3) 强化学习Agent,负责根据当前状态选择行动,调整相机位姿;4) 奖励函数,用于评估Agent的行动效果,指导Agent的学习。整体流程是,首先进行一次性的跨模态特征提取,然后Agent根据当前状态迭代地调整相机位姿,直到达到目标精度或达到最大迭代次数。
关键创新:1) 将图像到点云配准建模为迭代的MDP,引入了迭代优化机制;2) 提出了2D-3D混合状态表示,充分利用了图像和点云的特征;3) 设计了高效的特征复用机制,避免了重复的特征提取。
关键设计:1) 状态表示:结合图像的深度信息和点云的几何信息,形成混合状态表示;2) 奖励函数:设计了基于位姿误差和迭代次数的奖励函数,引导Agent快速收敛;3) 模仿学习初始化:使用模仿学习预训练Agent的策略,加速强化学习的训练过程;4) 网络结构:采用轻量级的网络结构,保证了配准的效率。
🖼️ 关键图片


📊 实验亮点
CMR-Agent在KITTI-Odometry和NuScenes数据集上进行了评估,实验结果表明,该方法在配准精度和效率方面都具有竞争力。尤其是在完成一次性嵌入后,每次迭代仅需几毫秒,这使得该方法具有很高的实用价值。与现有方法相比,CMR-Agent在精度上取得了显著提升,并且具有更好的可解释性。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、增强现实等领域。在自动驾驶中,可以利用该方法实现车辆的精确定位,提高导航的准确性和安全性。在机器人导航中,可以帮助机器人在未知环境中进行自主定位和地图构建。在增强现实中,可以将虚拟物体精确地叠加到真实场景中,提升用户体验。
📄 摘要(原文)
Image-to-point cloud registration aims to determine the relative camera pose of an RGB image with respect to a point cloud. It plays an important role in camera localization within pre-built LiDAR maps. Despite the modality gaps, most learning-based methods establish 2D-3D point correspondences in feature space without any feedback mechanism for iterative optimization, resulting in poor accuracy and interpretability. In this paper, we propose to reformulate the registration procedure as an iterative Markov decision process, allowing for incremental adjustments to the camera pose based on each intermediate state. To achieve this, we employ reinforcement learning to develop a cross-modal registration agent (CMR-Agent), and use imitation learning to initialize its registration policy for stability and quick-start of the training. According to the cross-modal observations, we propose a 2D-3D hybrid state representation that fully exploits the fine-grained features of RGB images while reducing the useless neutral states caused by the spatial truncation of camera frustum. Additionally, the overall framework is well-designed to efficiently reuse one-shot cross-modal embeddings, avoiding repetitive and time-consuming feature extraction. Extensive experiments on the KITTI-Odometry and NuScenes datasets demonstrate that CMR-Agent achieves competitive accuracy and efficiency in registration. Once the one-shot embeddings are completed, each iteration only takes a few milliseconds.