Mixture-of-Noises Enhanced Forgery-Aware Predictor for Multi-Face Manipulation Detection and Localization
作者: Changtao Miao, Qi Chu, Tao Gong, Zhentao Tan, Zhenchao Jin, Wanyi Zhuang, Man Luo, Honggang Hu, Nenghai Yu
分类: cs.CV
发布日期: 2024-08-05
💡 一句话要点
提出MoNFAP框架,增强多人脸伪造图像的检测与定位能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 人脸伪造检测 多人脸场景 伪造定位 Transformer 噪声提取
📋 核心要点
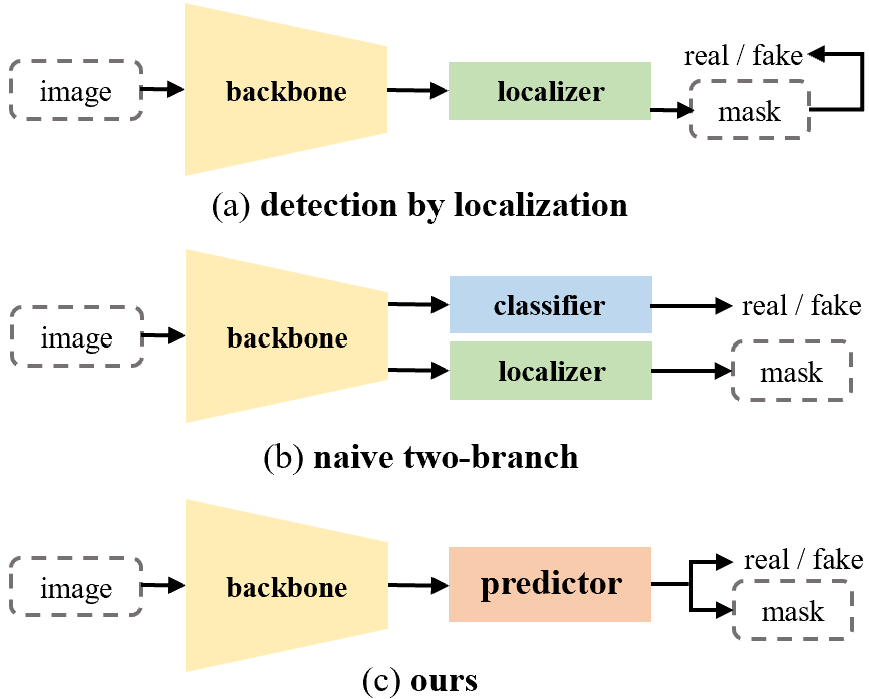
- 现有多人脸伪造检测与定位方法性能不足,或检测性能受定位限制,或定位能力因任务交互不足而受限。
- MoNFAP框架通过伪造感知统一预测器(FUP)和混合噪声模块(MNM)增强检测和定位能力。
- 实验结果表明,MoNFAP在多人脸伪造检测和定位任务上取得了显著的性能提升,并建立了新的基准。
📝 摘要(中文)
随着人脸伪造技术的进步,多人脸场景下的伪造图像日益复杂和逼真。然而,针对此类多人脸伪造的检测和定位方法仍然欠发达。传统方法要么间接从定位掩码导出检测结果,导致检测性能受限;要么采用简单的双分支结构同时获得检测和定位结果,由于两任务间交互有限,无法有效提升定位能力。本文提出了一种名为MoNFAP的新框架,专门为多人脸伪造检测和定位设计。MoNFAP主要引入了两个新模块:伪造感知统一预测器(FUP)模块和混合噪声模块(MNM)。FUP利用token学习策略和多个伪造感知Transformer集成检测和定位任务,从而利用分类信息来增强定位能力。此外,受噪声信息在伪造检测中关键作用的启发,MNM利用基于专家混合概念的多个噪声提取器来增强通用RGB特征,进一步提升框架性能。最后,我们建立了一个全面的多人脸检测和定位基准,所提出的MoNFAP取得了显著的性能。
🔬 方法详解
问题定义:论文旨在解决多人脸伪造图像的检测和定位问题。现有方法的痛点在于:1) 传统方法依赖于从定位结果间接推断检测结果,导致检测性能受限;2) 一些方法采用简单的双分支结构同时进行检测和定位,但由于两个任务之间的交互不足,定位能力无法得到有效提升。
核心思路:论文的核心思路是设计一个能够有效融合检测和定位信息的框架,并利用噪声信息来增强伪造检测能力。通过伪造感知统一预测器(FUP)模块,将检测和定位任务集成到一个统一的框架中,并利用分类信息来指导定位。同时,利用混合噪声模块(MNM)提取图像中的噪声特征,进一步提升模型的性能。
技术框架:MoNFAP框架主要包含两个核心模块:伪造感知统一预测器(FUP)模块和混合噪声模块(MNM)。FUP模块使用token学习策略和多个伪造感知Transformer,将检测和定位任务集成到一个统一的框架中。MNM模块则利用多个噪声提取器,基于专家混合的概念,增强通用的RGB特征。整体流程是:输入图像首先经过MNM模块提取噪声特征,然后将提取的特征输入到FUP模块中进行检测和定位。
关键创新:论文的关键创新在于:1) 提出了伪造感知统一预测器(FUP)模块,将检测和定位任务集成到一个统一的框架中,实现了分类信息对定位能力的增强。2) 提出了混合噪声模块(MNM),利用多个噪声提取器来增强图像的特征表示,提升了模型对伪造图像的检测能力。3) 构建了一个新的多人脸伪造检测和定位基准数据集。
关键设计:FUP模块使用了token学习策略,将图像分割成多个token,并使用Transformer来学习这些token之间的关系。MNM模块使用了多个噪声提取器,每个提取器负责提取不同类型的噪声特征。损失函数方面,可能采用了交叉熵损失函数用于分类任务,以及Dice损失或IoU损失函数用于分割任务(具体细节未知,需参考论文代码)。网络结构方面,FUP模块使用了多个Transformer层,MNM模块使用了多个卷积层或Transformer层(具体结构未知,需参考论文代码)。
🖼️ 关键图片


📊 实验亮点
MoNFAP在多人脸伪造检测和定位任务上取得了显著的性能提升。具体性能数据和对比基线需要在论文中查找,但摘要中明确指出其性能优于现有方法,并建立了新的基准。该框架通过FUP和MNM模块的有效结合,实现了检测和定位能力的显著增强(具体数值提升未知)。
🎯 应用场景
该研究成果可应用于社交媒体平台、安全监控系统等领域,用于检测和定位伪造人脸图像,从而防止虚假信息的传播和身份欺诈等行为。未来,该技术有望进一步发展,应用于更复杂的场景,例如视频伪造检测和深度伪造内容溯源。
📄 摘要(原文)
With the advancement of face manipulation technology, forgery images in multi-face scenarios are gradually becoming a more complex and realistic challenge. Despite this, detection and localization methods for such multi-face manipulations remain underdeveloped. Traditional manipulation localization methods either indirectly derive detection results from localization masks, resulting in limited detection performance, or employ a naive two-branch structure to simultaneously obtain detection and localization results, which cannot effectively benefit the localization capability due to limited interaction between two tasks. This paper proposes a new framework, namely MoNFAP, specifically tailored for multi-face manipulation detection and localization. The MoNFAP primarily introduces two novel modules: the Forgery-aware Unified Predictor (FUP) Module and the Mixture-of-Noises Module (MNM). The FUP integrates detection and localization tasks using a token learning strategy and multiple forgery-aware transformers, which facilitates the use of classification information to enhance localization capability. Besides, motivated by the crucial role of noise information in forgery detection, the MNM leverages multiple noise extractors based on the concept of the mixture of experts to enhance the general RGB features, further boosting the performance of our framework. Finally, we establish a comprehensive benchmark for multi-face detection and localization and the proposed \textit{MoNFAP} achieves significant performance. The codes will be made available.