MoReFun: Past-Movement Guided Motion Representation Learning for Future Motion Prediction and Understanding
作者: Junyu Shi, Haoting Wu, Zhiyuan Zhang, Lijiang Liu, Yong Sun, Qiang Nie
分类: cs.CV
发布日期: 2024-08-04 (更新: 2025-11-18)
🔗 代码/项目: GITHUB
💡 一句话要点
提出MoReFun,通过过去运动引导的运动表征学习,提升未来人体运动预测与理解能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人体运动预测 运动表征学习 自监督学习 过去运动引导 运动理解
📋 核心要点
- 现有端到端人体运动预测方法难以捕捉复杂动态,易产生时间不一致或静态的预测结果,主要原因是模型过度依赖表面线索。
- MoReFun采用两阶段自监督框架,解耦表征学习和预测任务,通过过去运动引导的自重构学习更具意义的运动结构。
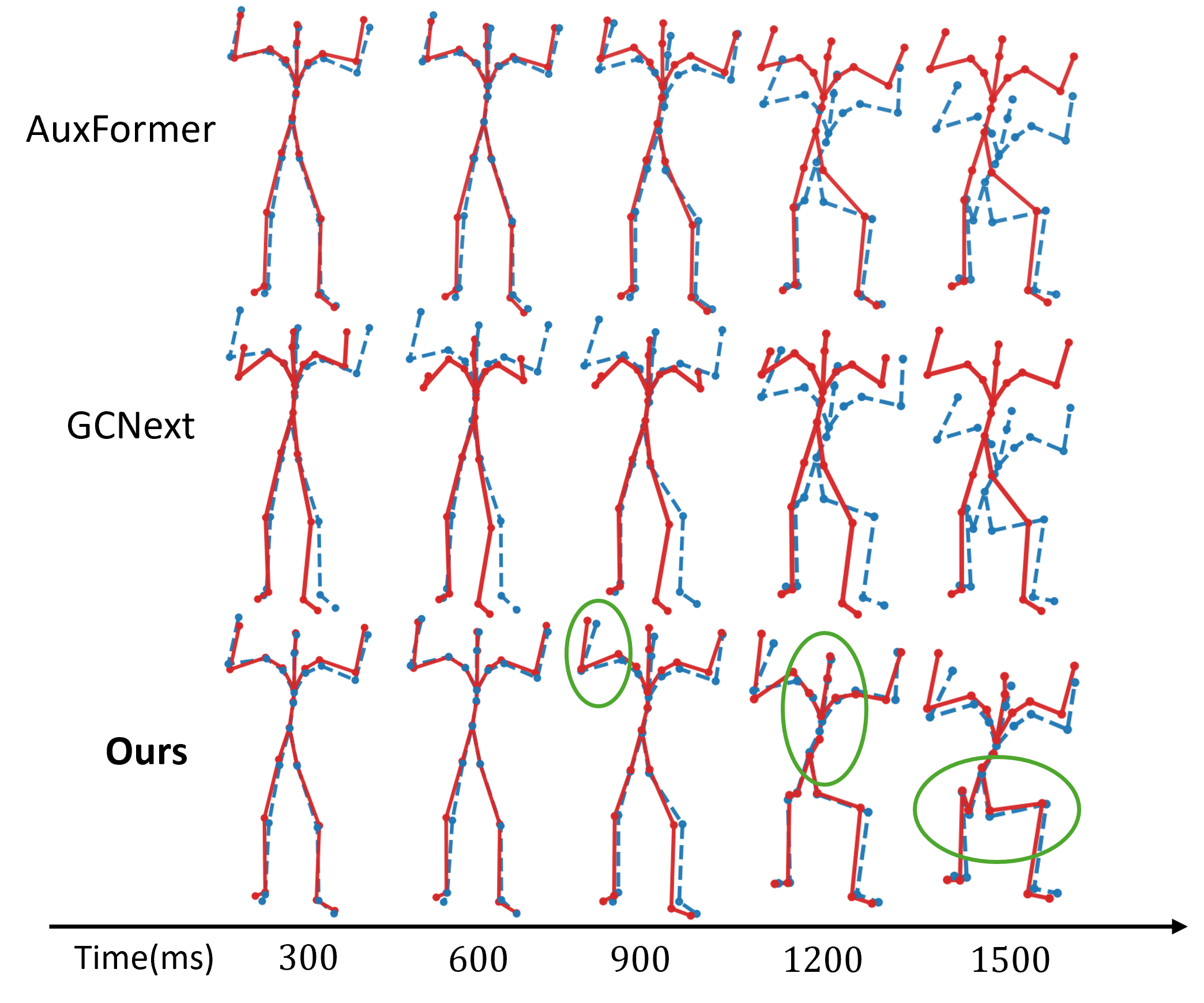
- 实验结果表明,MoReFun在多个数据集上显著降低了预测误差,并在运动理解方面达到了与大型语言模型相当的水平。
📝 摘要(中文)
本文提出了一种两阶段自监督框架MoReFun,旨在解决3D人体运动预测中现有端到端回归框架难以捕捉复杂动态、产生时间不一致或静态预测的问题。在预训练阶段,模型执行统一的过去-未来自重构,即在完整历史信息的引导下,重构过去序列并恢复未来序列中被掩盖的关节。一种基于速度的掩码策略选择高动态关节,迫使模型关注信息丰富的运动分量,并在没有回归干扰的情况下内化过去和未来状态之间的统计依赖关系。在微调阶段,预训练模型预测整个未来序列(视为完全掩盖),并配备一个轻量级的未来文本预测头,用于低级运动预测和高级运动理解的联合优化。在Human3.6M、3DPW和AMASS上的实验表明,该方法比最先进的方法平均降低了8.8%的预测误差,同时实现了与基于LLM的模型相比具有竞争力的未来运动理解性能。
🔬 方法详解
问题定义:现有3D人体运动预测方法,特别是端到端回归框架,在捕捉复杂运动动态方面存在不足,容易产生时间上不一致或静态的预测结果。这是因为模型倾向于利用数据中的表面相关性(representation shortcutting),而未能真正学习到运动的内在结构和规律。
核心思路:MoReFun的核心思路是将运动表征学习与运动预测任务解耦,通过自监督学习的方式,让模型首先学习到高质量的运动表征,然后再利用这些表征进行运动预测。这种解耦的方式可以避免模型在预测过程中过度依赖表面相关性,从而更好地捕捉运动的内在结构。
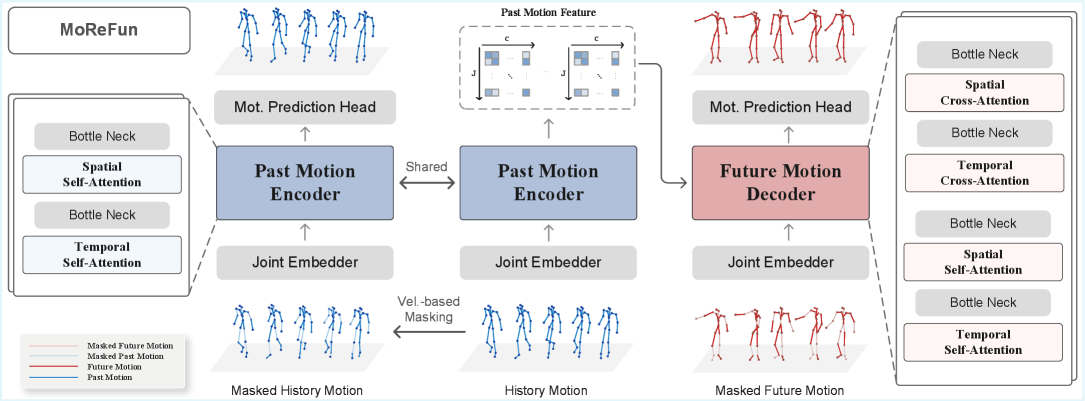
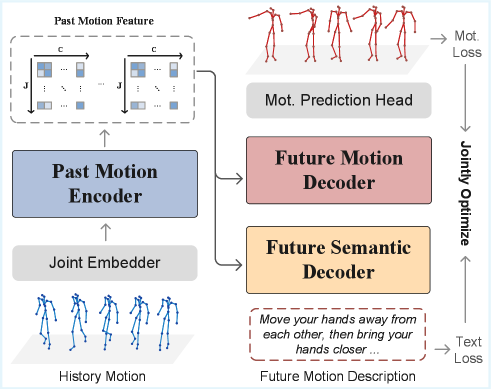
技术框架:MoReFun包含两个主要阶段:预训练阶段和微调阶段。在预训练阶段,模型执行统一的过去-未来自重构任务,即在已知过去运动序列的情况下,同时重构过去序列和预测未来序列中被掩盖的关节。在微调阶段,模型利用预训练得到的运动表征,预测完整的未来运动序列,并增加一个未来文本预测头,用于联合优化运动预测和运动理解任务。
关键创新:MoReFun的关键创新在于其统一的过去-未来自重构预训练任务和基于速度的掩码策略。统一的自重构任务使得模型能够同时学习过去和未来运动之间的依赖关系,而基于速度的掩码策略则迫使模型关注运动中信息量最大的部分,从而学习到更鲁棒的运动表征。
关键设计:在预训练阶段,MoReFun使用基于速度的掩码策略,选择运动速度较高的关节进行掩盖,迫使模型关注这些关键关节的运动信息。此外,模型使用Transformer架构进行序列建模。在微调阶段,MoReFun增加了一个轻量级的未来文本预测头,用于预测与未来运动相关的文本描述,从而实现运动预测和运动理解的联合优化。损失函数包括运动重构损失和文本预测损失。
🖼️ 关键图片
📊 实验亮点
MoReFun在Human3.6M、3DPW和AMASS等多个标准数据集上进行了评估,实验结果表明,MoReFun在运动预测精度方面显著优于现有方法,平均降低了8.8%的预测误差。同时,MoReFun在运动理解方面也取得了与基于大型语言模型的方法相当的性能,证明了其在运动表征学习方面的有效性。
🎯 应用场景
MoReFun在人机交互、虚拟现实、游戏开发、智能监控、康复训练等领域具有广泛的应用前景。高质量的运动预测可以提升人机交互的自然性和流畅性,为虚拟现实和游戏提供更逼真的角色动画,辅助智能监控系统进行异常行为检测,并为康复训练提供个性化的运动指导。
📄 摘要(原文)
3D human motion prediction aims to generate coherent future motions from observed sequences, yet existing end-to-end regression frameworks often fail to capture complex dynamics and tend to produce temporally inconsistent or static predictions-a limitation rooted in representation shortcutting, where models rely on superficial cues rather than learning meaningful motion structure. We propose a two-stage self-supervised framework that decouples representation learning from prediction. In the pretraining stage, the model performs unified past-future self-reconstruction, reconstructing the past sequence while recovering masked joints in the future sequence under full historical guidance. A velocity-based masking strategy selects highly dynamic joints, forcing the model to focus on informative motion components and internalize the statistical dependencies between past and future states without regression interference. In the fine-tuning stage, the pretrained model predicts the entire future sequence, now treated as fully masked, and is further equipped with a lightweight future-text prediction head for joint optimization of low-level motion prediction and high-level motion understanding. Experiments on Human3.6M, 3DPW, and AMASS show that our method reduces average prediction errors by 8.8% over state-of-the-art methods while achieving competitive future-motion understanding performance compared to LLM-based models. Code is available at: https://github.com/JunyuShi02/MoReFun