Unsupervised Representation Learning by Balanced Self Attention Matching
作者: Daniel Shalam, Simon Korman
分类: cs.CV, cs.LG
发布日期: 2024-08-04
💡 一句话要点
提出基于平衡自注意力匹配的无监督表征学习方法BAM,避免特征坍塌。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无监督学习 表征学习 自注意力机制 特征坍塌 对比学习
📋 核心要点
- 现有的自监督学习方法,特别是基于实例判别的方法,容易出现特征坍塌问题,导致学习到的表征质量下降。
- BAM方法通过匹配图像增强视角的自注意力向量,并利用全局平衡和熵正则化来避免特征坍塌,从而学习到更鲁棒的表征。
- 实验结果表明,BAM方法在半监督和迁移学习任务上取得了与当前领先方法相当的性能。
📝 摘要(中文)
本文提出了一种名为BAM的无监督表征学习方法,特别针对图像特征嵌入。该方法基于实例判别任务的变体,旨在解决优化过程中易出现的特征坍塌问题。不同于直接匹配输入图像不同视角(增强)的特征,BAM通过匹配它们的自注意力向量来实现,这些向量表示与一批增强图像的相似度分布。通过最小化一个损失函数,使这些分布与其全局平衡和熵正则化版本相匹配,从而获得丰富的表征并避免特征坍塌。大量的实验验证了该方法,并在半监督和迁移学习基准测试中表现出与领先方法相媲美的性能。代码和预训练模型已开源。
🔬 方法详解
问题定义:现有的基于实例判别的自监督学习方法在训练过程中容易出现特征坍塌的问题。这意味着模型学习到的表征会将所有输入映射到相同的输出,导致表征失去区分性,从而影响下游任务的性能。现有的解决方法包括使用负样本、外部记忆库或使用具有不同结构的独立编码网络,但这些方法通常需要复杂的设置或额外的计算资源。
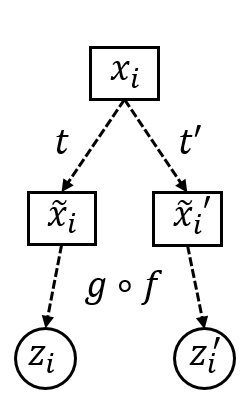
核心思路:BAM的核心思路是,与其直接匹配不同视角下图像的特征向量,不如匹配它们的自注意力向量。自注意力向量可以看作是图像与其他所有图像之间相似度的分布。通过约束这些分布,使其接近一个全局平衡且具有高熵的分布,可以有效地避免特征坍塌,并鼓励模型学习到更具区分性的表征。
技术框架:BAM的整体框架包括以下几个步骤:1)对输入图像进行数据增强,生成多个不同的视角;2)使用编码器网络提取每个视角的特征向量;3)计算每个特征向量的自注意力向量,即该特征向量与其他所有特征向量之间的相似度分布;4)计算全局平衡和熵正则化的目标分布;5)使用损失函数,最小化自注意力向量与目标分布之间的差异,从而更新编码器网络的参数。
关键创新:BAM的关键创新在于使用自注意力向量作为学习的目标,而不是直接使用特征向量。自注意力向量能够捕捉图像之间的关系,从而更好地避免特征坍塌。此外,BAM还引入了全局平衡和熵正则化,进一步提高了表征的质量。
关键设计:BAM的关键设计包括:1)使用余弦相似度来计算自注意力向量;2)使用Sinkhorn算法来计算全局平衡的目标分布;3)使用交叉熵损失函数来最小化自注意力向量与目标分布之间的差异;4)通过调整熵正则化的系数来控制目标分布的平滑程度。
🖼️ 关键图片

📊 实验亮点
BAM方法在多个基准数据集上进行了评估,包括CIFAR-10、CIFAR-100和ImageNet。实验结果表明,BAM方法在半监督学习和迁移学习任务上都取得了与当前领先方法相当的性能。例如,在CIFAR-10数据集上,使用BAM方法预训练的模型在仅使用少量标签的情况下,就能够达到很高的分类精度。此外,BAM方法还能够有效地避免特征坍塌,从而保证了学习到的表征的质量。
🎯 应用场景
BAM方法可以应用于各种无监督表征学习场景,例如图像分类、目标检测、图像分割等。由于其能够有效避免特征坍塌,因此特别适用于数据量较小或标签信息不足的情况。该方法还可以作为预训练模型,用于迁移学习,从而提高下游任务的性能。未来,BAM方法可以扩展到其他模态的数据,例如文本、音频等。
📄 摘要(原文)
Many leading self-supervised methods for unsupervised representation learning, in particular those for embedding image features, are built on variants of the instance discrimination task, whose optimization is known to be prone to instabilities that can lead to feature collapse. Different techniques have been devised to circumvent this issue, including the use of negative pairs with different contrastive losses, the use of external memory banks, and breaking of symmetry by using separate encoding networks with possibly different structures. Our method, termed BAM, rather than directly matching features of different views (augmentations) of input images, is based on matching their self-attention vectors, which are the distributions of similarities to the entire set of augmented images of a batch. We obtain rich representations and avoid feature collapse by minimizing a loss that matches these distributions to their globally balanced and entropy regularized version, which is obtained through a simple self-optimal-transport computation. We ablate and verify our method through a wide set of experiments that show competitive performance with leading methods on both semi-supervised and transfer-learning benchmarks. Our implementation and pre-trained models are available at github.com/DanielShalam/BAM .