JambaTalk: Speech-Driven 3D Talking Head Generation Based on Hybrid Transformer-Mamba Model
作者: Farzaneh Jafari, Stefano Berretti, Anup Basu
分类: cs.CV
发布日期: 2024-08-03 (更新: 2025-12-06)
备注: 23 pages with 8 figures
💡 一句话要点
提出JambaTalk,一种基于混合Transformer-Mamba模型的语音驱动3D说话头生成方法。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 说话头生成 3D人脸动画 Transformer Mamba 语音驱动 多模态融合 长序列建模
📋 核心要点
- 现有说话头生成模型在唇动同步、表情和头部姿态等方面存在不足,难以同时优化所有指标。
- JambaTalk利用混合Transformer-Mamba架构,结合两者的优势,旨在提升长序列处理能力和运动多样性。
- 实验结果表明,JambaTalk在说话头生成任务上达到了与现有最佳模型相当甚至更优越的性能。
📝 摘要(中文)
近年来,说话头生成已成为研究人员关注的焦点。人们付出了大量的努力来改进唇动同步、捕捉富有表现力的面部表情、生成自然的头部姿势并实现高质量的视频。然而,还没有一个单一的模型能够在所有定量和定性指标上都达到同等水平。我们引入了Jamba,一种混合Transformer-Mamba模型,用于动画3D人脸。Mamba是一种开创性的结构化状态空间模型(SSM)架构,旨在克服传统Transformer架构的局限性,尤其是在处理长序列方面。这一挑战限制了传统模型。Jamba结合了Transformer和Mamba方法的优点,提供了一个全面的解决方案。基于基础的Jamba块,我们提出了JambaTalk,通过多模态集成来增强运动多样性和唇动同步。大量的实验表明,我们的方法实现了与最先进模型相当或更优越的性能。
🔬 方法详解
问题定义:论文旨在解决语音驱动的3D说话头生成问题,现有方法在处理长语音序列时,由于Transformer的计算复杂度高,难以捕捉长时依赖关系,导致生成的头部运动不够自然,唇动同步效果不佳。
核心思路:论文的核心思路是结合Transformer和Mamba的优势。Transformer擅长捕捉全局信息,而Mamba在处理长序列方面具有更高的效率和更强的建模能力。通过混合使用这两种架构,可以有效地处理长语音序列,生成更自然、更逼真的说话头动画。
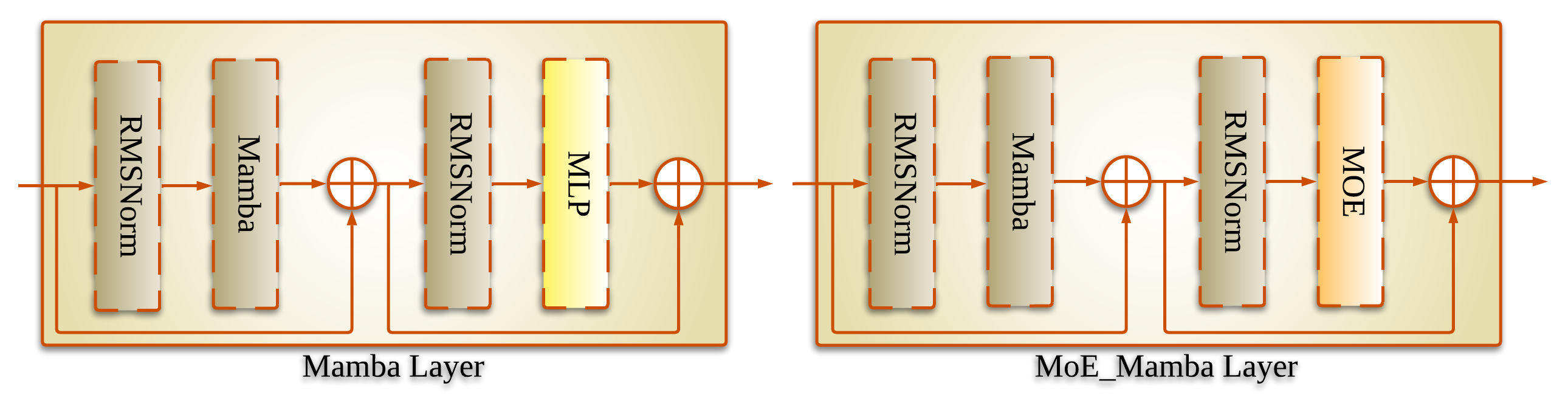
技术框架:JambaTalk的整体框架基于Jamba块,该块是Transformer和Mamba的混合结构。输入包括语音特征和3D人脸模型。首先,语音特征通过嵌入层进行编码。然后,编码后的语音特征和3D人脸模型被输入到Jamba块中进行处理,生成相应的面部表情和头部姿态。最后,通过渲染引擎将生成的3D人脸动画呈现出来。
关键创新:最关键的创新点在于Jamba块的设计,它将Transformer的全局建模能力和Mamba的长序列处理能力结合起来。这种混合架构能够更好地捕捉语音和面部运动之间的复杂关系,从而生成更逼真的说话头动画。与纯Transformer或纯Mamba模型相比,JambaTalk在性能和效率之间取得了更好的平衡。
关键设计:论文中使用了多层Jamba块来逐步 refinement 生成的动画。损失函数包括唇动同步损失、面部表情损失和头部姿态损失,用于约束生成的动画与输入语音的一致性。具体的参数设置和网络结构细节在论文中有详细描述,但摘要中未提及具体数值。
🖼️ 关键图片


📊 实验亮点
论文通过大量实验验证了JambaTalk的有效性。实验结果表明,JambaTalk在唇动同步、面部表情和头部姿态等方面均取得了与现有最佳模型相当或更优越的性能。具体的性能数据和对比基线在摘要中未给出,需要在论文正文中查找。
🎯 应用场景
JambaTalk具有广泛的应用前景,包括虚拟助手、在线教育、游戏开发、电影制作等领域。它可以用于创建逼真的虚拟角色,提升用户体验,降低制作成本。未来,该技术有望应用于实时语音驱动的3D人脸动画,实现更自然的人机交互。
📄 摘要(原文)
In recent years, the talking head generation has become a focal point for researchers. Considerable effort is being made to refine lip-sync motion, capture expressive facial expressions, generate natural head poses, and achieve high-quality video. However, no single model has yet achieved equivalence across all quantitative and qualitative metrics. We introduce Jamba, a hybrid Transformer-Mamba model, to animate a 3D face. Mamba, a pioneering Structured State Space Model (SSM) architecture, was developed to overcome the limitations of conventional Transformer architectures, particularly in handling long sequences. This challenge has constrained traditional models. Jamba combines the advantages of both the Transformer and Mamba approaches, offering a comprehensive solution. Based on the foundational Jamba block, we present JambaTalk to enhance motion variety and lip sync through multimodal integration. Extensive experiments reveal that our method achieves performance comparable or superior to state-of-the-art models.