Embodiment: Self-Supervised Depth Estimation Based on Camera Models
作者: Jinchang Zhang, Praveen Kumar Reddy, Xue-Iuan Wong, Yiannis Aloimonos, Guoyu Lu
分类: cs.CV
发布日期: 2024-08-02 (更新: 2024-08-29)
💡 一句话要点
提出基于相机模型的自监督深度估计方法,提升单目深度估计性能。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目深度估计 自监督学习 相机模型 深度先验 具身智能 机器人视觉 无监督学习
📋 核心要点
- 单目深度估计的自监督学习方法在性能和尺度恢复上仍有挑战,与监督学习存在差距。
- 该论文提出将相机内参和外参等物理属性嵌入深度学习模型,提供深度先验和自由监督信号。
- 通过嵌入相机物理属性,增强了无监督方法的性能,实现了对现实世界的具身理解。
📝 摘要(中文)
深度估计是机器人和视觉相关任务的关键课题。在单目深度估计中,与需要昂贵的真值标注的监督学习相比,自监督方法因其无需标注成本而具有巨大潜力。然而,自监督学习在3D重建和深度估计性能方面与监督学习仍存在较大差距。同时,尺度也是单目无监督深度估计的一个主要问题,通常仍然需要来自GPS、LiDAR或现有地图的真值尺度来进行校正。在深度学习时代,现有方法主要依赖于探索图像关系来训练无监督神经网络,而相机本身的物理属性(如内参和外参)常常被忽视。这些物理属性不仅仅是数学参数,它们是相机与物理世界交互的体现。通过将这些物理属性嵌入到深度学习模型中,我们可以基于物理原理计算地面区域和与地面相连区域的深度先验,从而提供无需额外传感器的自由监督信号。这种方法不仅易于实现,而且通过将相机的物理属性嵌入到模型中,增强了所有无监督方法的效果,从而实现了对现实世界的具身理解。
🔬 方法详解
问题定义:现有的单目深度估计自监督学习方法,依赖于图像关系进行训练,忽略了相机自身的物理属性,导致深度估计精度不高,且尺度恢复需要额外的传感器信息(如GPS、LiDAR)或地图信息进行校正。
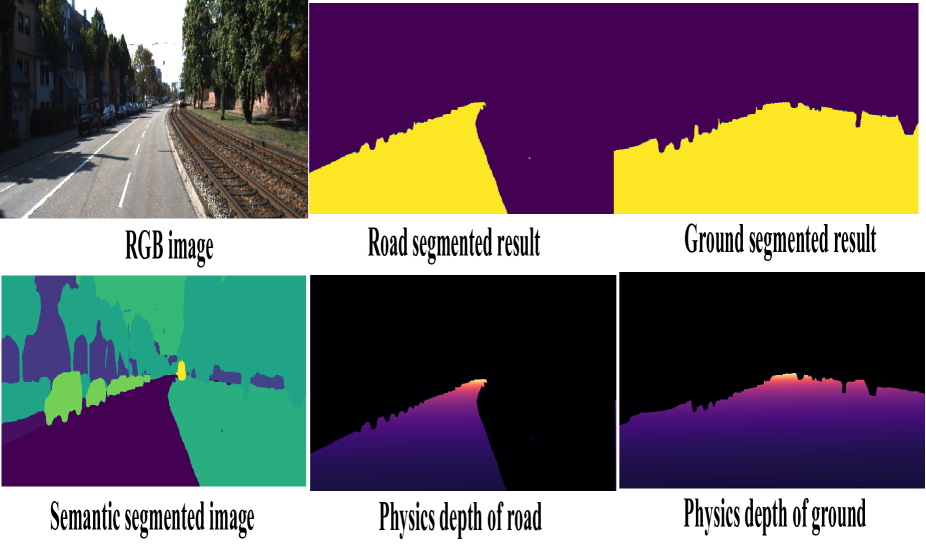
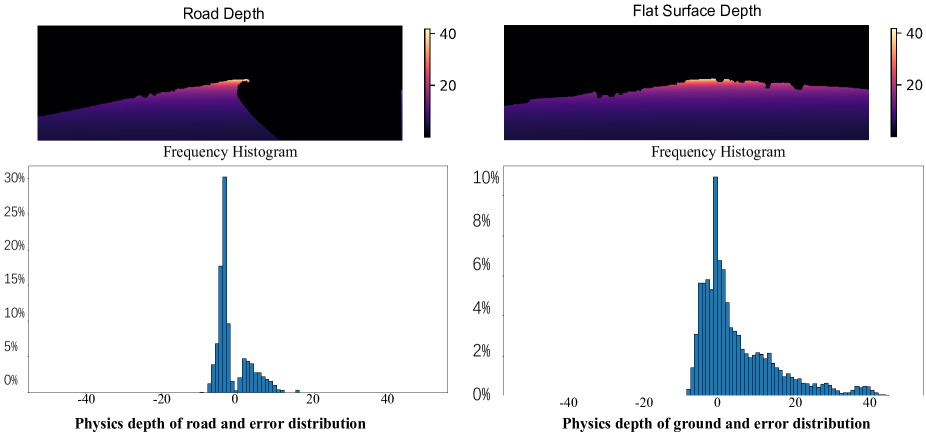
核心思路:论文的核心思路是将相机的物理属性(内参和外参)融入到深度学习模型中,利用这些属性计算地面区域和与地面相连区域的深度先验。这些深度先验可以作为额外的监督信号,从而提升深度估计的准确性和尺度一致性,而无需额外的传感器。
技术框架:整体框架包括一个深度估计网络和一个位姿估计网络(如果需要)。关键在于将相机参数(内参、外参)显式地引入到损失函数的设计中。具体来说,根据相机参数和图像坐标,可以计算出场景中某些区域(如地面)的深度范围,并将其作为深度估计网络的监督信号。同时,可以利用相机参数约束位姿估计网络的输出,提高位姿估计的准确性。
关键创新:最重要的创新点在于将相机的物理属性作为先验知识融入到深度学习模型中,从而为自监督深度估计提供了额外的监督信号。这种方法摆脱了对额外传感器的依赖,并且能够提升深度估计的准确性和尺度一致性。与现有方法相比,该方法更加注重相机与环境的物理交互,实现了对现实世界的具身理解。
关键设计:关键设计包括:1) 如何根据相机参数计算地面区域的深度范围;2) 如何将这些深度范围作为损失函数的一部分,引导深度估计网络的训练;3) 如何利用相机参数约束位姿估计网络的输出。具体的损失函数可能包括深度一致性损失、位姿一致性损失以及基于相机参数的深度先验损失。网络结构可以采用现有的深度估计和位姿估计网络,关键在于损失函数的设计。
🖼️ 关键图片

📊 实验亮点
论文通过将相机物理属性嵌入模型,实现了无需额外传感器的自监督深度估计。实验结果表明,该方法能够有效提升深度估计的准确性和尺度一致性,缩小了与监督学习方法之间的差距。具体的性能数据(如RMSE、MAE等)和对比基线需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于机器人导航、自动驾驶、增强现实等领域。通过提升单目深度估计的准确性和鲁棒性,可以提高机器人对环境的感知能力,使其能够更好地进行路径规划、避障等任务。在自动驾驶领域,该方法可以减少对昂贵传感器的依赖,降低成本。在增强现实领域,可以提供更准确的深度信息,提升AR体验。
📄 摘要(原文)
Depth estimation is a critical topic for robotics and vision-related tasks. In monocular depth estimation, in comparison with supervised learning that requires expensive ground truth labeling, self-supervised methods possess great potential due to no labeling cost. However, self-supervised learning still has a large gap with supervised learning in 3D reconstruction and depth estimation performance. Meanwhile, scaling is also a major issue for monocular unsupervised depth estimation, which commonly still needs ground truth scale from GPS, LiDAR, or existing maps to correct. In the era of deep learning, existing methods primarily rely on exploring image relationships to train unsupervised neural networks, while the physical properties of the camera itself such as intrinsics and extrinsics are often overlooked. These physical properties are not just mathematical parameters; they are embodiments of the camera's interaction with the physical world. By embedding these physical properties into the deep learning model, we can calculate depth priors for ground regions and regions connected to the ground based on physical principles, providing free supervision signals without the need for additional sensors. This approach is not only easy to implement but also enhances the effects of all unsupervised methods by embedding the camera's physical properties into the model, thereby achieving an embodied understanding of the real world.