An Efficient and Effective Transformer Decoder-Based Framework for Multi-Task Visual Grounding
作者: Wei Chen, Long Chen, Yu Wu
分类: cs.CV
发布日期: 2024-08-02
备注: 21pages, 10 figures, 9 tables. Accepted to ECCV 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于Transformer Decoder的高效多任务视觉定位框架,解决计算成本过高问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 Transformer Decoder 多任务学习 视觉语言融合 计算效率 自注意力机制 图像分割
📋 核心要点
- 现有基于Transformer的视觉定位方法计算成本高,尤其是在处理高分辨率图像或长文本时,限制了其在复杂场景中的应用。
- 论文提出EEVG框架,利用Transformer Decoder进行视觉和语言特征融合,并采用无参数方法消除背景视觉tokens,降低计算复杂度。
- 实验结果表明,该方法在多个基准测试中表现出高效性和有效性,验证了其在视觉定位任务中的优越性。
📝 摘要(中文)
本文提出了一种高效且有效的基于Transformer Decoder的多任务视觉定位(EEVG)框架,旨在解决现有基于Transformer的方法中,由于Transformer Encoder的自注意力机制导致的计算成本随图像分辨率或上下文句子长度呈平方级增长的问题。该框架从语言和视觉两方面降低成本。在语言方面,采用Transformer Decoder融合视觉和语言特征,其中语言特征作为memory,视觉特征作为query,使得融合计算量随语言表达长度线性增长。在视觉方面,引入一种无参数方法,通过消除基于注意力分数的背景视觉tokens来减少计算量。然后设计一个轻量级的mask head,直接从剩余的稀疏特征图预测分割mask。在多个基准测试上的大量结果和消融研究证明了该方法的效率和有效性。
🔬 方法详解
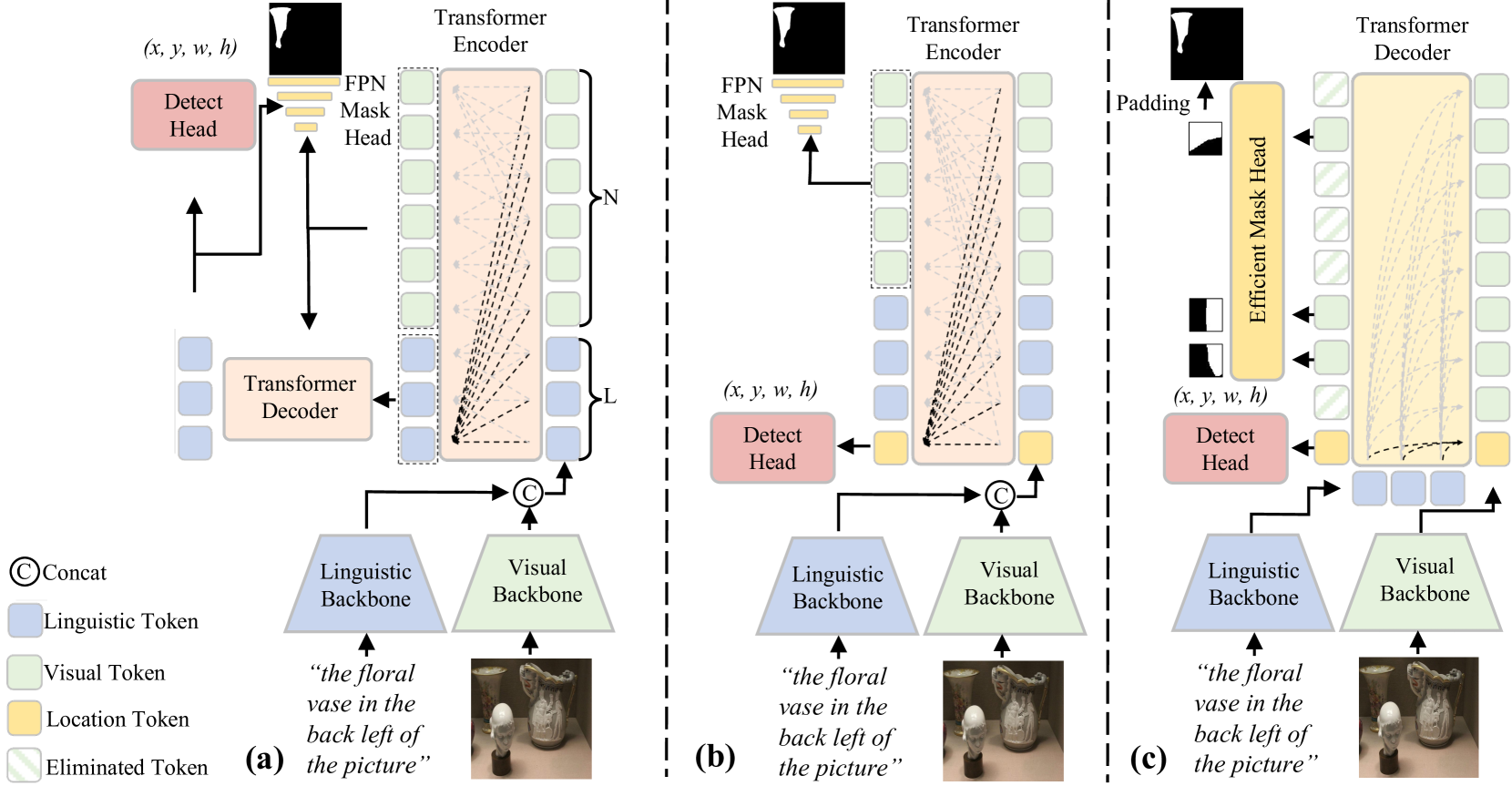
问题定义:现有基于Transformer的视觉定位方法,特别是那些依赖Transformer Encoder进行视觉-语言特征融合的方法,面临着计算成本过高的问题。Transformer Encoder中的自注意力机制导致计算复杂度随输入序列长度(图像分辨率或文本长度)呈平方级增长。这使得这些方法难以应用于需要处理高分辨率图像或长文本的复杂场景,例如基于对话的推理分割。
核心思路:论文的核心思路是通过使用Transformer Decoder来替代Transformer Encoder,从而降低计算复杂度。Transformer Decoder的计算复杂度与query的长度线性相关,因此可以将视觉特征作为query,语言特征作为memory,从而使得计算复杂度随语言表达长度线性增长。此外,通过去除不重要的背景视觉tokens,进一步降低视觉方面的计算量。
技术框架:EEVG框架主要包含以下几个模块:1) 视觉特征提取模块:提取输入图像的视觉特征。2) 语言特征提取模块:提取输入文本的语言特征。3) Transformer Decoder融合模块:将语言特征作为memory,视觉特征作为query,通过Transformer Decoder进行视觉-语言特征融合。4) 背景视觉tokens消除模块:基于注意力分数,消除不重要的背景视觉tokens。5) Mask预测模块:从剩余的稀疏特征图预测分割mask。
关键创新:该论文的关键创新点在于:1) 使用Transformer Decoder进行视觉-语言特征融合,降低了计算复杂度。2) 提出了一种无参数的背景视觉tokens消除方法,进一步降低了视觉方面的计算量。3) 设计了一个轻量级的mask head,直接从稀疏特征图预测分割mask,提高了效率。
关键设计:在Transformer Decoder融合模块中,语言特征被用作memory,视觉特征被用作query。背景视觉tokens消除模块基于注意力分数,设定一个阈值,低于该阈值的tokens被认为是背景tokens并被移除。Mask预测模块采用一个轻量级的卷积神经网络,直接从稀疏特征图预测分割mask。具体的参数设置和网络结构细节在论文中有详细描述(未知)。损失函数的设计也未在摘要中提及(未知)。
🖼️ 关键图片


📊 实验亮点
论文在多个视觉定位基准测试上进行了实验,结果表明,所提出的EEVG框架在保持甚至提高性能的同时,显著降低了计算成本。具体的性能数据、对比基线和提升幅度在摘要中未提及,需查阅论文全文(未知)。
🎯 应用场景
该研究成果可应用于需要处理高分辨率图像或长文本的视觉定位任务,例如智能监控、自动驾驶、机器人导航、图像编辑和基于对话的图像理解等领域。通过降低计算成本,该方法使得视觉定位技术能够应用于更复杂的场景,并具有更广泛的实际应用价值。未来,该方法可以进一步扩展到其他多模态任务中。
📄 摘要(原文)
Most advanced visual grounding methods rely on Transformers for visual-linguistic feature fusion. However, these Transformer-based approaches encounter a significant drawback: the computational costs escalate quadratically due to the self-attention mechanism in the Transformer Encoder, particularly when dealing with high-resolution images or long context sentences. This quadratic increase in computational burden restricts the applicability of visual grounding to more intricate scenes, such as conversation-based reasoning segmentation, which involves lengthy language expressions. In this paper, we propose an efficient and effective multi-task visual grounding (EEVG) framework based on Transformer Decoder to address this issue, which reduces the cost in both language and visual aspects. In the language aspect, we employ the Transformer Decoder to fuse visual and linguistic features, where linguistic features are input as memory and visual features as queries. This allows fusion to scale linearly with language expression length. In the visual aspect, we introduce a parameter-free approach to reduce computation by eliminating background visual tokens based on attention scores. We then design a light mask head to directly predict segmentation masks from the remaining sparse feature maps. Extensive results and ablation studies on benchmarks demonstrate the efficiency and effectiveness of our approach. Code is available in https://github.com/chenwei746/EEVG.