OmniParser for Pure Vision Based GUI Agent
作者: Yadong Lu, Jianwei Yang, Yelong Shen, Ahmed Awadallah
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2024-08-01
💡 一句话要点
OmniParser:用于纯视觉GUI代理的屏幕解析方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GUI代理 屏幕解析 视觉语言模型 可交互元素检测 语义理解
📋 核心要点
- 现有方法缺乏鲁棒的屏幕解析技术,难以准确识别可交互元素并理解其语义,限制了视觉语言模型在GUI代理中的应用。
- OmniParser通过训练专门的检测和语义理解模型,将用户界面截图解析为结构化元素,从而提升代理的动作生成能力。
- 实验表明,OmniParser显著提升了GPT-4V在ScreenSpot上的性能,并在Mind2Web和AITW上超越了需要额外信息的基线模型。
📝 摘要(中文)
大型视觉语言模型在驱动用户界面上的代理系统方面显示出巨大潜力。然而,由于缺乏一种强大的屏幕解析技术,能够可靠地识别用户界面中可交互的图标,并理解截图中各种元素的语义,以及准确地将预期动作与屏幕上的相应区域相关联,因此像GPT-4V这样的多模态模型作为跨不同应用程序在多个操作系统上的通用代理的能力被大大低估了。为了填补这些空白,我们介绍了一种全面的方法 extsc{OmniParser},用于将用户界面截图解析为结构化元素,从而显著增强了GPT-4V生成能够准确地基于界面中相应区域的动作的能力。我们首先使用流行的网页和图标描述数据集,整理了一个可交互的图标检测数据集。这些数据集被用于微调专门的模型:一个检测模型来解析屏幕上可交互的区域,以及一个标题模型来提取检测到的元素的功能语义。 extsc{OmniParser}显著提高了GPT-4V在ScreenSpot基准测试上的性能。在Mind2Web和AITW基准测试中,仅使用截图作为输入的 extsc{OmniParser}优于需要截图之外的额外信息的GPT-4V基线。
🔬 方法详解
问题定义:现有基于视觉语言模型的GUI代理,如GPT-4V,在跨平台和应用上的泛化能力受限于屏幕解析的准确性和鲁棒性。现有方法难以精确识别可交互元素,并理解其功能语义,导致动作生成无法准确对应屏幕区域。
核心思路:OmniParser的核心思路是将屏幕解析任务分解为可交互元素检测和语义理解两个子任务,并分别训练专门的模型。通过结构化解析屏幕信息,提升视觉语言模型对用户界面的理解和操作能力。
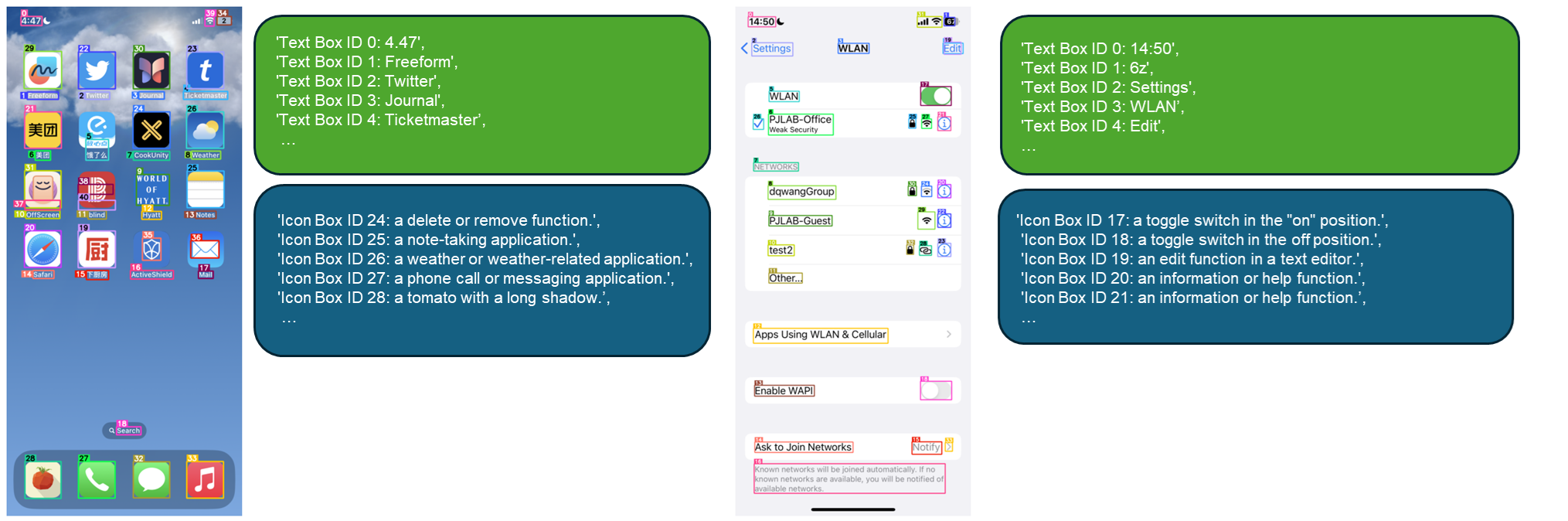
技术框架:OmniParser包含两个主要模块:1) 可交互元素检测模型,用于识别屏幕上的可交互区域;2) 语义理解模型,用于提取检测到的元素的功能语义。整体流程为:输入用户界面截图,首先由检测模型识别可交互区域,然后由语义理解模型提取这些区域的语义信息,最后将结构化信息输入视觉语言模型,生成可执行的动作。
关键创新:OmniParser的关键创新在于针对GUI界面的特点,专门训练了可交互元素检测和语义理解模型,并构建了相应的数据集。这种针对性训练显著提升了屏幕解析的准确性和鲁棒性,从而改善了GUI代理的性能。与通用目标检测模型相比,OmniParser更关注用户界面的特定元素。
关键设计:论文构建了两个数据集:一个是可交互图标检测数据集,另一个是图标描述数据集。具体模型结构和损失函数等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
OmniParser在ScreenSpot基准测试上显著提高了GPT-4V的性能。在Mind2Web和AITW基准测试中,仅使用截图作为输入的OmniParser优于需要截图之外的额外信息的GPT-4V基线,表明了其在屏幕解析方面的优越性。具体的性能提升数据在论文中未详细给出,属于未知信息。
🎯 应用场景
OmniParser可应用于自动化测试、RPA(机器人流程自动化)、辅助技术等领域。通过提升GUI代理的智能化水平,可以实现更高效、更便捷的人机交互,并为残障人士提供更好的辅助工具。未来,该技术有望应用于智能家居、智能车载等更多场景。
📄 摘要(原文)
The recent success of large vision language models shows great potential in driving the agent system operating on user interfaces. However, we argue that the power multimodal models like GPT-4V as a general agent on multiple operating systems across different applications is largely underestimated due to the lack of a robust screen parsing technique capable of: 1) reliably identifying interactable icons within the user interface, and 2) understanding the semantics of various elements in a screenshot and accurately associate the intended action with the corresponding region on the screen. To fill these gaps, we introduce \textsc{OmniParser}, a comprehensive method for parsing user interface screenshots into structured elements, which significantly enhances the ability of GPT-4V to generate actions that can be accurately grounded in the corresponding regions of the interface. We first curated an interactable icon detection dataset using popular webpages and an icon description dataset. These datasets were utilized to fine-tune specialized models: a detection model to parse interactable regions on the screen and a caption model to extract the functional semantics of the detected elements. \textsc{OmniParser} significantly improves GPT-4V's performance on ScreenSpot benchmark. And on Mind2Web and AITW benchmark, \textsc{OmniParser} with screenshot only input outperforms the GPT-4V baselines requiring additional information outside of screenshot.