RainMamba: Enhanced Locality Learning with State Space Models for Video Deraining
作者: Hongtao Wu, Yijun Yang, Huihui Xu, Weiming Wang, Jinni Zhou, Lei Zhu
分类: cs.CV
发布日期: 2024-07-31 (更新: 2024-09-11)
备注: ACM Multimedia 2024 Oral
🔗 代码/项目: GITHUB
💡 一句话要点
提出RainMamba,利用改进的状态空间模型增强视频去雨的局部信息学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频去雨 状态空间模型 Hilbert扫描 局部信息学习 对比学习
📋 核心要点
- 传统视频去雨方法依赖光流估计和核方法,感受野有限,Transformer计算复杂度高,难以有效去除视频中的雨痕和雨滴。
- RainMamba采用改进的状态空间模型,结合Hilbert扫描机制捕获序列局部信息,并引入差异引导的对比局部性学习策略。
- 实验表明,RainMamba在合成和真实雨天视频数据集上,均能有效去除雨痕和雨滴,展现了其有效性和效率。
📝 摘要(中文)
户外视觉系统经常受到雨痕和雨滴的污染,这显著降低了视觉任务和多媒体应用程序的性能。视频的本质在于其用于去雨的冗余时间线索具有更高的稳定性。传统的视频去雨方法严重依赖于光流估计和基于核的方法,这些方法具有有限的感受野。然而,Transformer架构虽然能够实现长期依赖,但却带来了计算复杂度的显著增加。最近,状态空间模型(SSM)的线性复杂度算子反而促进了高效的长期时间建模,这对于视频中雨痕和雨滴的去除至关重要。然而,它在视频上的单维顺序处理通过拉远相邻像素破坏了时空维度上的局部相关性。为了解决这个问题,我们提出了一种改进的基于SSM的视频去雨网络(RainMamba),它采用了一种新颖的Hilbert扫描机制,以更好地捕获序列级的局部信息。我们还引入了一种差异引导的动态对比局部性学习策略,以增强所提出的网络在patch级别上的自相似性学习能力。在四个合成视频去雨数据集和真实雨天视频上的大量实验证明了我们的网络在去除雨痕和雨滴方面的有效性和效率。我们的代码和结果可在https://github.com/TonyHongtaoWu/RainMamba上找到。
🔬 方法详解
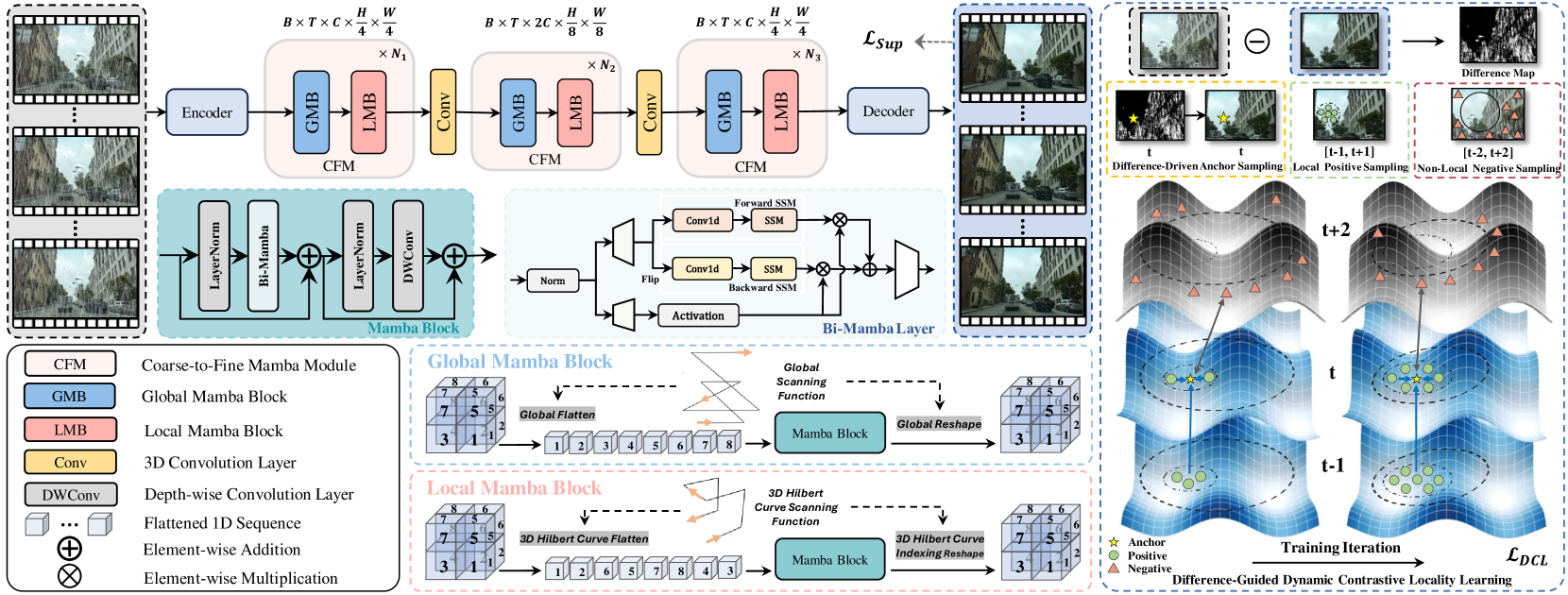
问题定义:论文旨在解决视频去雨问题,即从包含雨痕和雨滴的视频中恢复清晰的视频内容。现有方法,如基于光流估计和核方法的传统方法,感受野有限,难以捕捉长时依赖关系。而Transformer虽然能捕捉长时依赖,但计算复杂度过高,不适用于视频处理。状态空间模型(SSM)虽然计算效率高,但其一维序列处理会破坏视频时空维度上的局部相关性。
核心思路:论文的核心思路是改进状态空间模型,使其既能保持高效的长期时间建模能力,又能有效捕捉视频中的局部相关性。通过引入Hilbert扫描机制,改变SSM的扫描方式,使其更好地保留局部像素间的关系。同时,利用差异引导的对比局部性学习策略,增强网络对图像块级别自相似性的学习能力,从而更准确地去除雨痕。
技术框架:RainMamba网络主要包含以下几个部分:首先,输入含雨视频帧序列。然后,通过改进的SSM模块,利用Hilbert扫描机制提取时空特征。接着,使用差异引导的动态对比局部性学习模块,增强patch级别的自相似性学习。最后,通过重建模块,生成去雨后的视频帧序列。整体框架采用端到端的可训练模式。
关键创新:论文的关键创新在于以下两点:一是提出了基于Hilbert扫描的状态空间模型,有效解决了传统SSM在视频处理中破坏局部相关性的问题。Hilbert扫描能够更好地保留相邻像素的空间关系,从而提升去雨效果。二是引入了差异引导的动态对比局部性学习策略,通过关注图像块之间的差异,增强了网络对雨痕和清晰区域的区分能力,提高了去雨的准确性。
关键设计:Hilbert扫描机制的具体实现方式是按照Hilbert曲线的顺序对视频帧进行扫描,并将扫描后的序列输入到SSM中进行处理。差异引导的动态对比局部性学习策略通过计算图像块之间的差异,动态调整对比学习的权重,使得网络更加关注难以区分的图像块。损失函数方面,可能采用了L1损失或L2损失,以及感知损失等,以保证重建视频的质量。
🖼️ 关键图片


📊 实验亮点
论文在四个合成视频去雨数据集和真实雨天视频上进行了大量实验,结果表明RainMamba在去除雨痕和雨滴方面表现出色。具体性能数据未知,但摘要强调了其有效性和效率,暗示了RainMamba在性能上优于现有方法,并且计算复杂度较低,更适合实际应用。
🎯 应用场景
RainMamba在智能交通、安防监控、自动驾驶等领域具有广泛的应用前景。在这些场景中,雨天环境会严重影响视觉系统的性能,导致目标检测、跟踪等任务的准确率下降。RainMamba可以有效地去除视频中的雨痕和雨滴,提高视觉系统的鲁棒性和可靠性,从而提升相关应用的性能和安全性。
📄 摘要(原文)
The outdoor vision systems are frequently contaminated by rain streaks and raindrops, which significantly degenerate the performance of visual tasks and multimedia applications. The nature of videos exhibits redundant temporal cues for rain removal with higher stability. Traditional video deraining methods heavily rely on optical flow estimation and kernel-based manners, which have a limited receptive field. Yet, transformer architectures, while enabling long-term dependencies, bring about a significant increase in computational complexity. Recently, the linear-complexity operator of the state space models (SSMs) has contrarily facilitated efficient long-term temporal modeling, which is crucial for rain streaks and raindrops removal in videos. Unexpectedly, its uni-dimensional sequential process on videos destroys the local correlations across the spatio-temporal dimension by distancing adjacent pixels. To address this, we present an improved SSMs-based video deraining network (RainMamba) with a novel Hilbert scanning mechanism to better capture sequence-level local information. We also introduce a difference-guided dynamic contrastive locality learning strategy to enhance the patch-level self-similarity learning ability of the proposed network. Extensive experiments on four synthesized video deraining datasets and real-world rainy videos demonstrate the effectiveness and efficiency of our network in the removal of rain streaks and raindrops. Our code and results are available at https://github.com/TonyHongtaoWu/RainMamba.