Learning Video Context as Interleaved Multimodal Sequences
作者: Kevin Qinghong Lin, Pengchuan Zhang, Difei Gao, Xide Xia, Joya Chen, Ziteng Gao, Jinheng Xie, Xuhong Xiao, Mike Zheng Shou
分类: cs.CV, cs.MM
发布日期: 2024-07-31 (更新: 2024-09-12)
备注: Accepted by ECCV 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出MovieSeq,通过交错多模态序列学习视频上下文,提升叙事视频理解能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视频理解 叙事视频 语言模型 指令微调
📋 核心要点
- 叙事视频理解面临人物关系复杂、信息量大等挑战,现有方法难以有效捕捉视频上下文。
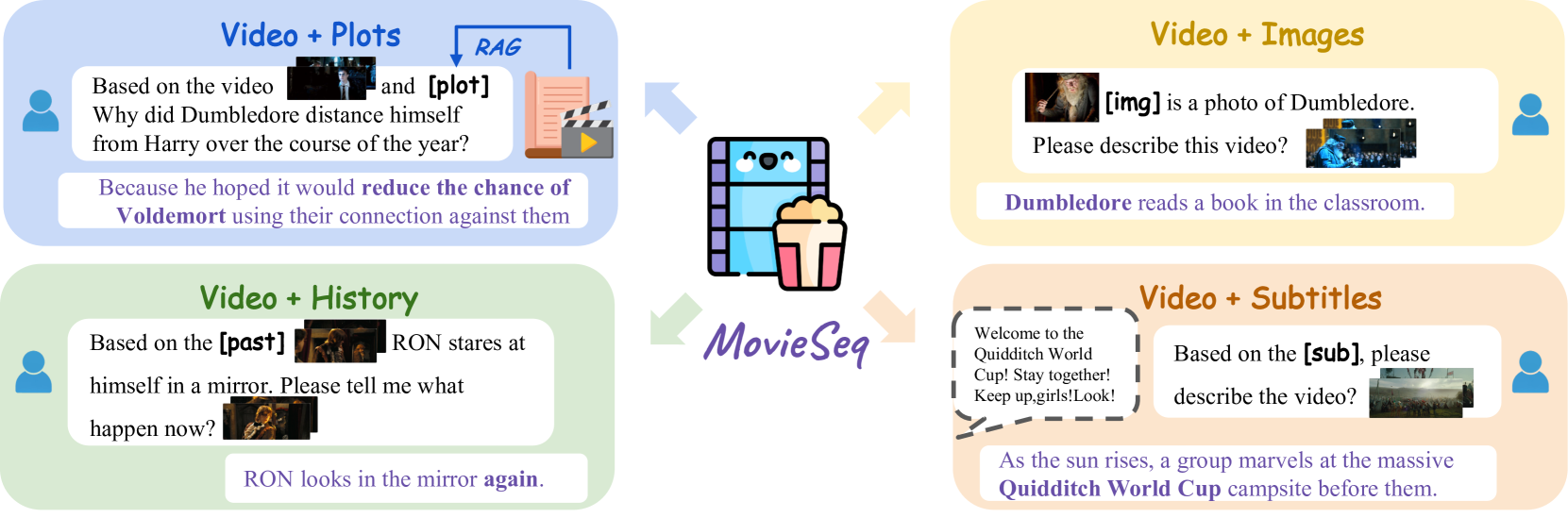
- MovieSeq将视频表示为交错的多模态序列,融合图像、情节、视频和字幕等信息,增强模型对视频上下文的理解。
- 实验结果表明,MovieSeq在多个视频理解任务上表现出色,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为MovieSeq的多模态语言模型,旨在解决叙事视频理解中的挑战,这些挑战源于视频丰富的上下文(人物、对话、故事情节)和多样化的需求(识别人物、关系和原因)。MovieSeq的核心思想是将视频表示为交错的多模态序列,包括图像、情节、视频和字幕,可以通过链接外部知识库或使用离线模型(如Whisper提取字幕)来实现。通过指令微调,该方法使语言模型能够使用交错的多模态指令与视频交互。例如,除了视频作为输入外,还提供人物照片及其姓名和对话,使模型能够关联这些元素并生成更全面的响应。为了验证其有效性,我们在六个数据集(LVU、MAD、Movienet、CMD、TVC、MovieQA)上,在五个设置(视频分类、音频描述、视频-文本检索、视频字幕和视频问答)中验证了MovieSeq的性能。
🔬 方法详解
问题定义:叙事视频理解需要深入理解视频的上下文信息,包括人物、对话、故事情节等。现有方法通常只依赖单一模态的输入(如视频帧),难以充分利用视频中蕴含的丰富信息,导致理解能力不足。此外,如何有效地将外部知识融入视频理解模型也是一个挑战。
核心思路:MovieSeq的核心思路是将视频表示为交错的多模态序列,即将视频帧、字幕、情节描述等不同模态的信息以交错的方式输入到模型中。这种表示方式能够让模型更好地理解视频的上下文信息,并建立不同模态之间的联系。同时,MovieSeq还利用外部知识库来增强模型的理解能力。
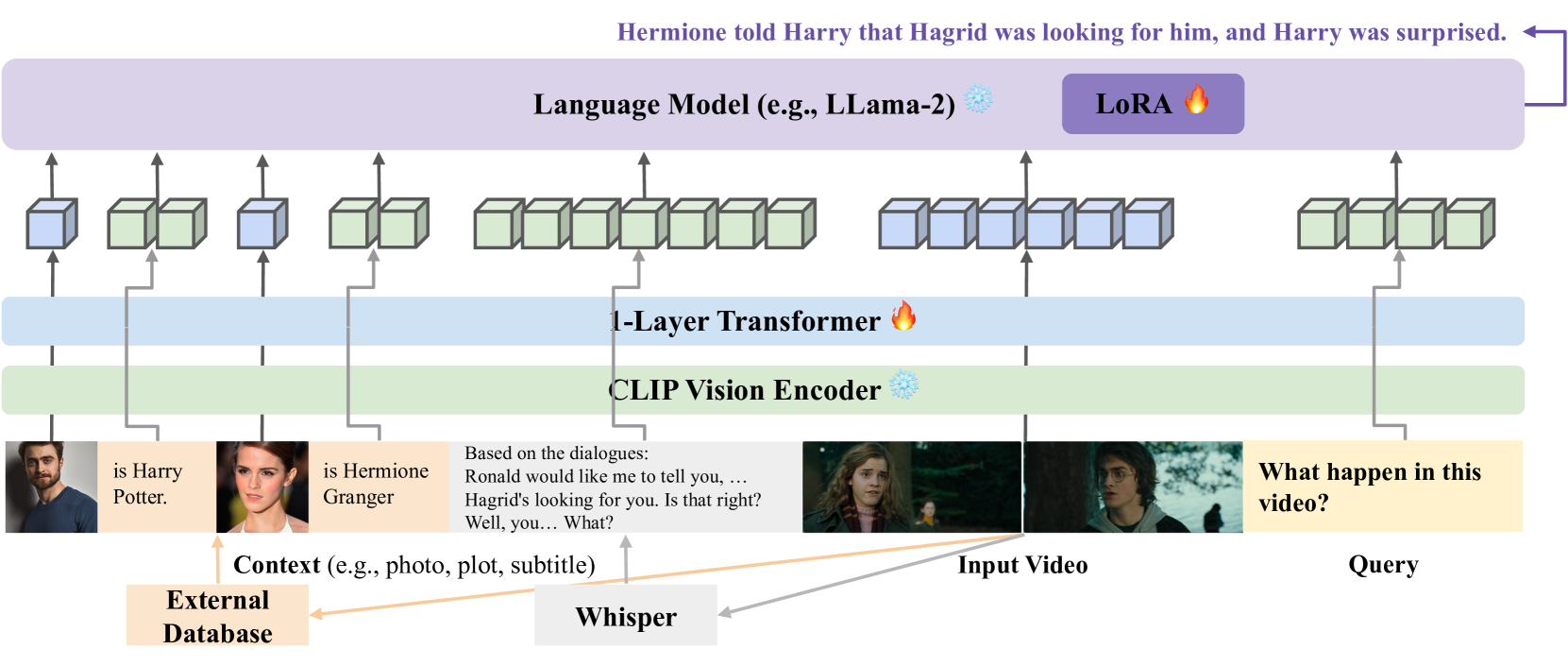
技术框架:MovieSeq的整体框架包括以下几个主要模块:1) 多模态数据提取模块:负责从视频中提取图像、字幕、情节描述等不同模态的信息。字幕可以使用Whisper等离线模型提取。2) 多模态序列构建模块:将提取的不同模态的信息以交错的方式构建成多模态序列。3) 指令微调模块:使用指令微调技术训练语言模型,使其能够理解和生成与视频相关的文本。4) 知识融合模块:利用外部知识库来增强模型的理解能力。
关键创新:MovieSeq的关键创新在于其交错多模态序列表示方法。与传统的单一模态输入或简单拼接多模态信息的方法不同,MovieSeq能够更好地捕捉视频的上下文信息,并建立不同模态之间的联系。此外,MovieSeq还利用指令微调技术来训练语言模型,使其能够更好地理解和生成与视频相关的文本。
关键设计:MovieSeq的关键设计包括:1) 多模态序列的构建方式:如何选择合适的模态信息,以及如何将它们以最佳的方式交错在一起。2) 指令微调的策略:如何设计合适的指令,以及如何选择合适的训练数据。3) 知识融合的方法:如何有效地将外部知识融入到模型中。
🖼️ 关键图片

📊 实验亮点
MovieSeq在LVU、MAD、Movienet、CMD、TVC、MovieQA六个数据集上进行了验证,涵盖视频分类、音频描述、视频-文本检索、视频字幕和视频问答五个任务。实验结果表明,MovieSeq在多个任务上取得了显著的性能提升,证明了其有效性。具体性能数据和对比基线信息未知。
🎯 应用场景
MovieSeq可应用于电影理解、视频内容分析、智能客服等领域。例如,它可以用于自动生成电影剧情梗概、回答用户关于电影内容的问题、为视障人士提供音频描述等。该研究有助于提升机器对视频内容的理解能力,为视频相关应用带来更智能、更便捷的体验。
📄 摘要(原文)
Narrative videos, such as movies, pose significant challenges in video understanding due to their rich contexts (characters, dialogues, storylines) and diverse demands (identify who, relationship, and reason). In this paper, we introduce MovieSeq, a multimodal language model developed to address the wide range of challenges in understanding video contexts. Our core idea is to represent videos as interleaved multimodal sequences (including images, plots, videos, and subtitles), either by linking external knowledge databases or using offline models (such as whisper for subtitles). Through instruction-tuning, this approach empowers the language model to interact with videos using interleaved multimodal instructions. For example, instead of solely relying on video as input, we jointly provide character photos alongside their names and dialogues, allowing the model to associate these elements and generate more comprehensive responses. To demonstrate its effectiveness, we validate MovieSeq's performance on six datasets (LVU, MAD, Movienet, CMD, TVC, MovieQA) across five settings (video classification, audio description, video-text retrieval, video captioning, and video question-answering). The code will be public at https://github.com/showlab/MovieSeq.