EMatch: A Unified Framework for Event-based Optical Flow and Stereo Matching
作者: Pengjie Zhang, Lin Zhu, Xiao Wang, Lizhi Wang, Wanxuan Lu, Hua Huang
分类: cs.CV
发布日期: 2024-07-31 (更新: 2024-11-22)
💡 一句话要点
EMatch:统一事件相机光流和立体匹配的框架,实现跨任务知识迁移
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 事件相机 光流估计 立体匹配 统一框架 跨任务学习
📋 核心要点
- 现有基于事件相机的光流和立体匹配方法侧重于特定任务,忽略了时空域任务间的关联和互补。
- EMatch将光流估计和立体匹配统一为密集对应匹配问题,通过共享特征空间实现跨任务知识迁移。
- 实验表明,EMatch无需重新训练即可同时处理光流和立体匹配,并在两项任务上达到SOTA性能。
📝 摘要(中文)
本文提出了一种统一的框架EMatch,用于解决基于事件相机的光流估计和立体匹配问题。现有方法通常专注于特定任务领域内的事件数据处理,忽略了时域和空域任务之间的相互促进作用。本文将事件光流估计和立体匹配重新定义为一个统一的密集对应匹配问题,从而可以在单个模型中解决这两个任务,通过在共享表示空间中直接匹配特征。具体而言,该方法利用时间循环网络来聚合时域或空域上的事件特征,并利用空间上下文注意力机制来增强事件流之间的知识传递。通过共享的特征相似性模块,该网络可以同时执行来自时间事件段输入的光流估计和来自空间事件段输入的立体匹配。实验表明,该统一模型固有地支持多任务融合和跨任务迁移,无需针对特定任务进行重新训练,即可有效地处理光流和立体估计,并在两个任务上都实现了最先进的性能。
🔬 方法详解
问题定义:现有基于事件相机的光流估计和立体匹配方法通常是独立设计的,针对特定任务进行优化,缺乏通用性和跨任务知识共享。这种孤立的方法忽略了光流估计(时域)和立体匹配(空域)之间潜在的互补信息,限制了模型的性能和泛化能力。
核心思路:本文的核心思路是将光流估计和立体匹配视为一个统一的密集对应匹配问题。通过学习一个共享的特征表示空间,模型可以同时处理来自时域(光流)和空域(立体匹配)的事件数据,并利用跨任务的知识迁移来提高性能。这种统一的视角使得模型能够更好地理解事件数据的内在结构,并提取更鲁棒的特征。
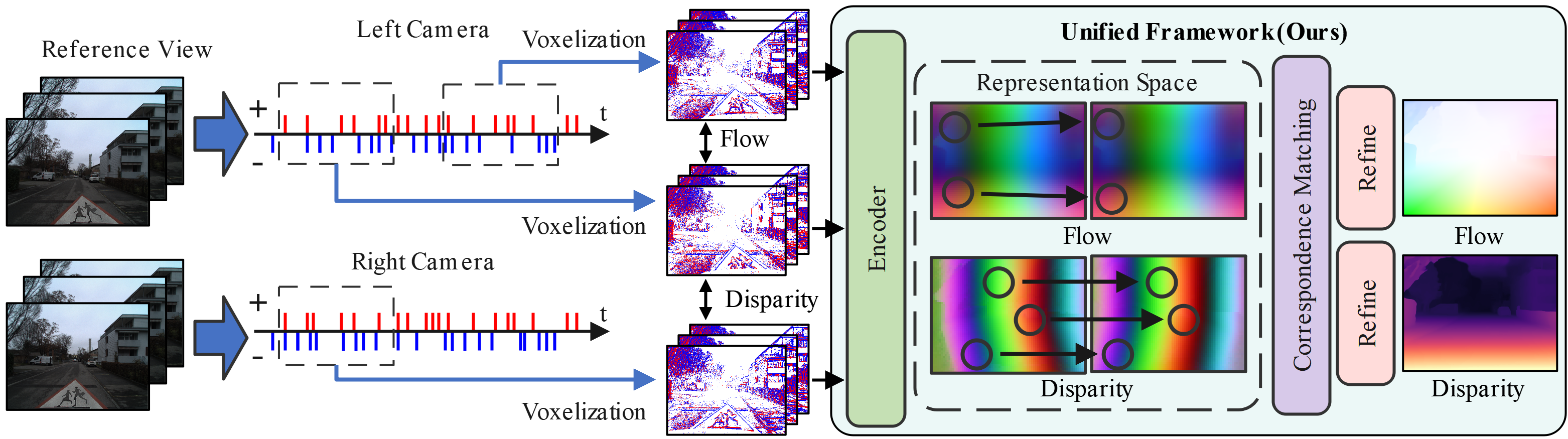
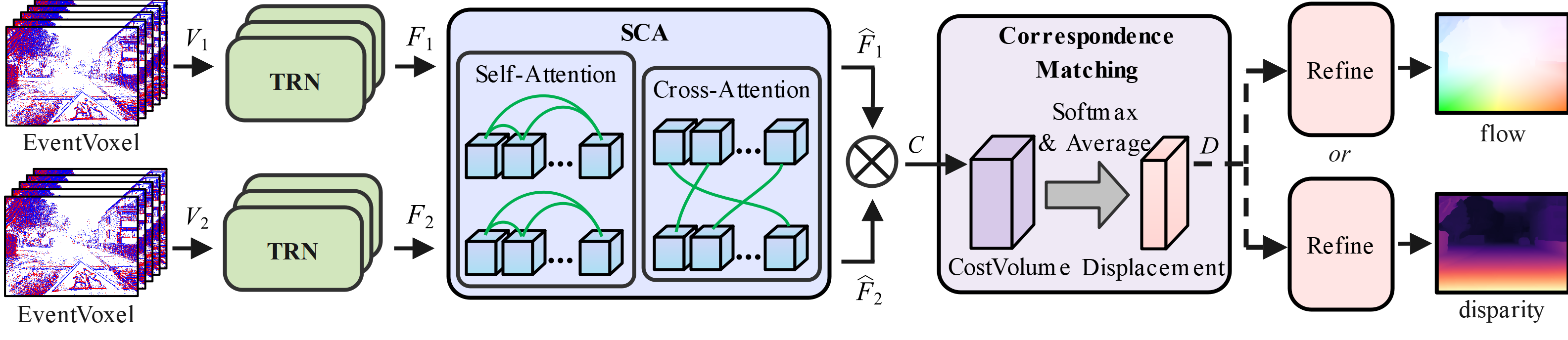
技术框架:EMatch框架主要包含三个核心模块:1) 时间循环网络(Temporal Recurrent Network):用于聚合时域或空域上的事件特征,提取事件流的时空信息。2) 空间上下文注意力(Spatial Contextual Attention):用于增强事件流之间的知识传递,通过时域或空域的交互来提高特征的表达能力。3) 共享特征相似性模块:用于计算事件特征之间的相似度,从而实现光流估计和立体匹配。整个流程是,首先将事件数据输入到时间循环网络中提取特征,然后利用空间上下文注意力机制增强特征表示,最后通过共享特征相似性模块计算对应关系,得到光流或视差图。
关键创新:EMatch的关键创新在于将光流估计和立体匹配统一到一个框架中,实现了跨任务的知识迁移。通过共享特征表示空间和利用空间上下文注意力机制,模型可以有效地利用来自不同任务的信息来提高性能。这种统一的视角打破了传统方法的局限性,为基于事件相机的视觉任务提供了一种新的解决方案。
关键设计:时间循环网络采用GRU结构,用于捕捉事件流的时序信息。空间上下文注意力机制通过计算事件特征之间的相似度来增强特征表示。共享特征相似性模块采用互相关操作来计算特征之间的对应关系。损失函数包括光流损失和视差损失,用于监督模型的训练。具体的参数设置和网络结构细节在论文中有详细描述,例如GRU的隐藏层维度,注意力机制的参数等。
🖼️ 关键图片

📊 实验亮点
EMatch在光流估计和立体匹配任务上均取得了SOTA性能。具体而言,在光流估计任务上,EMatch在MVSEC数据集上相比现有方法取得了显著的性能提升。在立体匹配任务上,EMatch在DDD17数据集上也取得了优异的结果。更重要的是,EMatch无需针对特定任务进行重新训练,即可同时处理光流和立体匹配,展示了其强大的泛化能力和跨任务知识迁移能力。
🎯 应用场景
EMatch框架在机器人导航、自动驾驶、增强现实等领域具有广泛的应用前景。例如,在机器人导航中,可以利用光流估计来感知环境运动,利用立体匹配来获取深度信息,从而实现自主导航。在自动驾驶中,可以利用EMatch框架来提高车辆对周围环境的感知能力,从而提高驾驶安全性。在增强现实中,可以利用EMatch框架来精确地估计场景的深度信息,从而实现更逼真的增强现实效果。
📄 摘要(原文)
Event cameras have shown promise in vision applications like optical flow estimation and stereo matching, with many specialized architectures leveraging the asynchronous and sparse nature of event data. However, existing works only focus event data within the confines of task-specific domains, overlooking how tasks across the temporal and spatial domains can reinforce each other. In this paper, we reformulate event-based flow estimation and stereo matching as a unified dense correspondence matching problem, enabling us to solve both tasks within a single model by directly matching features in a shared representation space. Specifically, our method utilizes a Temporal Recurrent Network to aggregate event features across temporal or spatial domains, and a Spatial Contextual Attention to enhance knowledge transfer across event flows via temporal or spatial interactions. By utilizing a shared feature similarities module that integrates knowledge from event streams via temporal or spatial interactions, our network performs optical flow estimation from temporal event segment inputs and stereo matching from spatial event segment inputs simultaneously. We demonstrate that our unified model inherently supports multi-task fusion and cross-task transfer. Without the need for retraining for specific task, our model can effectively handle both optical flow and stereo estimation, achieving state-of-the-art performance on both tasks.