MarvelOVD: Marrying Object Recognition and Vision-Language Models for Robust Open-Vocabulary Object Detection
作者: Kuo Wang, Lechao Cheng, Weikai Chen, Pingping Zhang, Liang Lin, Fan Zhou, Guanbin Li
分类: cs.CV
发布日期: 2024-07-31
备注: Codes are available at https://github.com/wkfdb/MarvelOVD
🔗 代码/项目: GITHUB
💡 一句话要点
MarvelOVD:融合目标识别与视觉-语言模型,实现鲁棒的开放词汇目标检测
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇目标检测 视觉-语言模型 伪标签 噪声过滤 自适应重加权
📋 核心要点
- 现有开放词汇目标检测方法依赖视觉-语言模型生成的伪标签,但VLM与检测任务存在领域差异,导致伪标签噪声大,影响检测性能。
- MarvelOVD的核心思想是利用检测器自身作为辅助指导,弥补VLM在理解背景和proposal上下文方面的不足,从而提纯伪标签。
- 实验结果表明,MarvelOVD在COCO和LVIS数据集上显著优于现有方法,证明了其有效性,代码已开源。
📝 摘要(中文)
本文提出了一种名为MarvelOVD的新范式,旨在解决开放词汇目标检测(OVD)中,利用视觉-语言模型(VLM)生成的伪标签存在噪声的问题。研究发现,VLM在OVD场景下存在偏差预测,其根本原因是VLM不擅长理解“背景”以及图像中proposal的上下文信息。MarvelOVD通过结合检测器自身的能力与视觉-语言模型,在线生成更优的训练目标并优化学习过程。该方法通过在线挖掘显著净化噪声伪标签,并提出自适应重加权来有效抑制与目标对象未对齐的有偏训练框。此外,还解决了被忽略的“基类-新类冲突”问题,并引入分层标签分配。在COCO和LVIS数据集上的大量实验表明,该方法显著优于其他最先进的方法。
🔬 方法详解
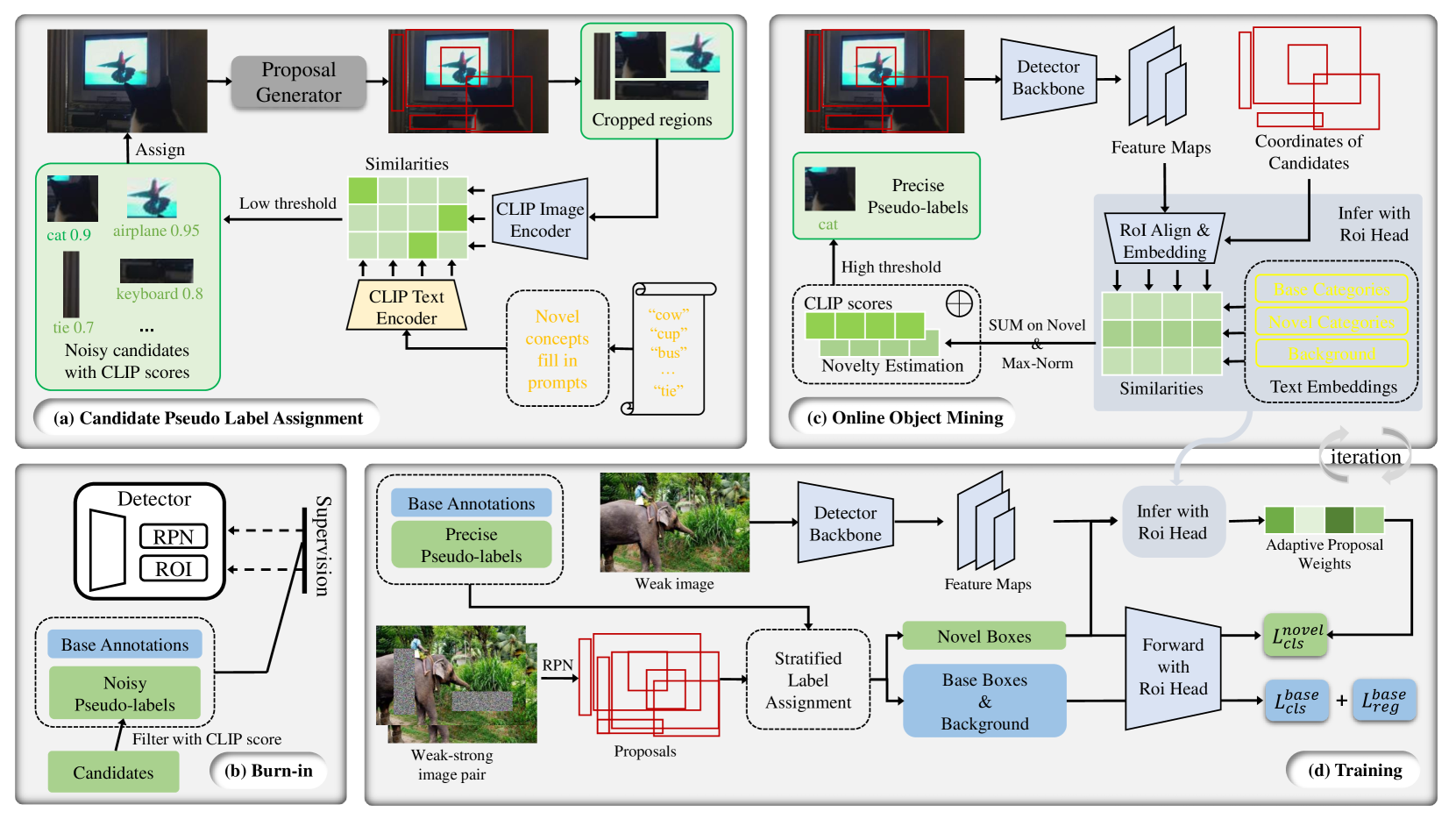
问题定义:开放词汇目标检测(OVD)旨在检测图像中预定义类别之外的新类别物体。现有方法通常利用视觉-语言模型(VLM)生成伪标签来训练检测器,但VLM生成的伪标签存在噪声,这是由于VLM不擅长理解图像背景和proposal的上下文信息,导致检测器训练存在偏差。
核心思路:MarvelOVD的核心思路是将目标检测器本身作为VLM的辅助指导,利用检测器对图像上下文的理解能力来过滤VLM生成的噪声伪标签,并优化训练过程。通过结合检测器和VLM的优势,提高伪标签的质量,从而提升OVD的性能。
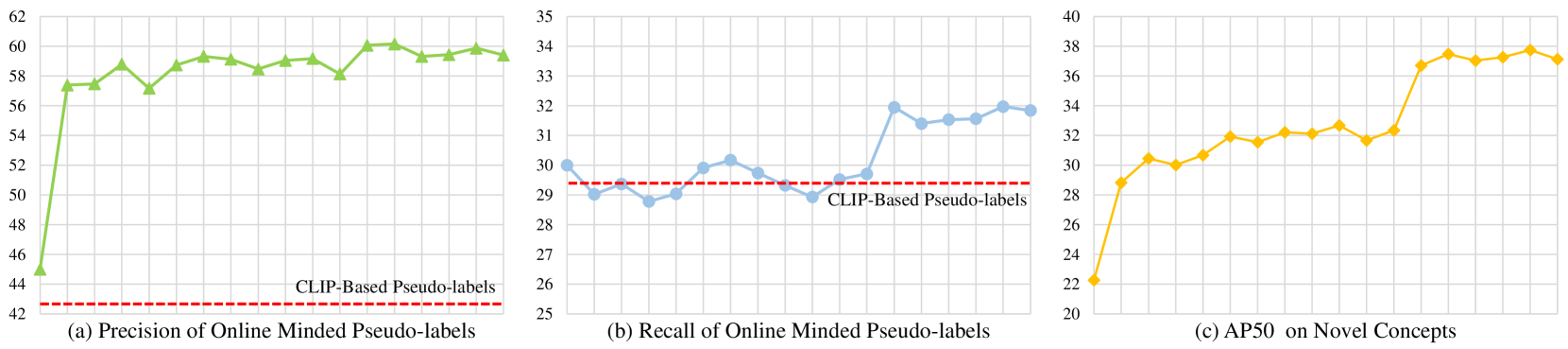
技术框架:MarvelOVD包含三个主要模块:1) Online Mining:在线挖掘高质量的伪标签,过滤掉噪声标签。2) Adaptive Reweighting:自适应地调整训练样本的权重,抑制与目标对象未对齐的有偏训练框。3) Stratified Label Assignments:分层标签分配,解决“基类-新类冲突”问题。整体流程是,首先利用VLM生成伪标签,然后通过Online Mining模块过滤噪声标签,接着使用Adaptive Reweighting模块调整训练样本权重,最后使用Stratified Label Assignments模块进行标签分配,训练检测器。
关键创新:MarvelOVD的关键创新在于将目标检测器本身作为VLM的辅助指导,利用检测器对图像上下文的理解能力来过滤VLM生成的噪声伪标签。与现有方法相比,MarvelOVD不是简单地依赖VLM生成的伪标签,而是通过结合检测器和VLM的优势,提高伪标签的质量。
关键设计:Online Mining模块通过设置阈值来过滤掉置信度低的伪标签。Adaptive Reweighting模块使用IoU(Intersection over Union)来衡量训练框与目标对象的对齐程度,并根据IoU值自适应地调整训练样本的权重。Stratified Label Assignments模块将标签分为基类和新类,并分别进行分配,以避免“基类-新类冲突”。
🖼️ 关键图片

📊 实验亮点
MarvelOVD在COCO和LVIS数据集上取得了显著的性能提升。在COCO数据集上,MarvelOVD的性能优于现有方法,取得了state-of-the-art的结果。在LVIS数据集上,MarvelOVD的性能提升更加明显,证明了其在长尾分布数据集上的有效性。具体性能数据请参考论文原文。
🎯 应用场景
MarvelOVD具有广泛的应用前景,例如智能安防、自动驾驶、机器人等领域。它可以用于检测图像中未知的物体,提高系统的鲁棒性和适应性。该研究的实际价值在于降低了对大量标注数据的依赖,使得开放词汇目标检测更加实用。未来,该方法可以进一步扩展到视频目标检测、图像分割等任务中。
📄 摘要(原文)
Learning from pseudo-labels that generated with VLMs~(Vision Language Models) has been shown as a promising solution to assist open vocabulary detection (OVD) in recent studies. However, due to the domain gap between VLM and vision-detection tasks, pseudo-labels produced by the VLMs are prone to be noisy, while the training design of the detector further amplifies the bias. In this work, we investigate the root cause of VLMs' biased prediction under the OVD context. Our observations lead to a simple yet effective paradigm, coded MarvelOVD, that generates significantly better training targets and optimizes the learning procedure in an online manner by marrying the capability of the detector with the vision-language model. Our key insight is that the detector itself can act as a strong auxiliary guidance to accommodate VLM's inability of understanding both the
background'' and the context of a proposal within the image. Based on it, we greatly purify the noisy pseudo-labels via Online Mining and propose Adaptive Reweighting to effectively suppress the biased training boxes that are not well aligned with the target object. In addition, we also identify a neglectedbase-novel-conflict'' problem and introduce stratified label assignments to prevent it. Extensive experiments on COCO and LVIS datasets demonstrate that our method outperforms the other state-of-the-arts by significant margins. Codes are available at https://github.com/wkfdb/MarvelOVD