MMTrail: A Multimodal Trailer Video Dataset with Language and Music Descriptions
作者: Xiaowei Chi, Yatian Wang, Aosong Cheng, Pengjun Fang, Zeyue Tian, Yingqing He, Zhaoyang Liu, Xingqun Qi, Jiahao Pan, Rongyu Zhang, Mengfei Li, Ruibin Yuan, Yanbing Jiang, Wei Xue, Wenhan Luo, Qifeng Chen, Shanghang Zhang, Qifeng Liu, Yike Guo
分类: cs.CV, cs.MM, cs.SD, eess.AS
发布日期: 2024-07-30 (更新: 2024-12-17)
备注: 15 Pages. Dataset report
💡 一句话要点
提出MMTrail:一个包含语言和音乐描述的大规模多模态预告片视频数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视频理解 预告片数据集 音乐描述 大型语言模型
📋 核心要点
- 现有视频-语言数据集对音频信息的利用不足,缺乏对视听相关性的深入探索,导致标注信息不够全面和精确。
- MMTrail数据集通过系统性的字幕框架,整合视觉、语言和音乐信息,利用LLM自适应地合并标注,提供更丰富的多模态信息。
- 实验结果表明,MMTrail数据集的标注质量高,能够有效提升多模态语言模型的训练效果,并提供基准评估指标。
📝 摘要(中文)
大规模多模态数据集在促进大型视频-语言模型的成功方面发挥着重要作用。然而,当前的视频-语言数据集主要为视觉帧提供文本描述,认为音频是弱相关信息,通常忽略了探索内在视听相关性的潜力,导致每个模态内的标注单调,而非全面和精确的描述。这种忽略导致了多模态交叉研究的困难。为了填补这一空白,我们提出了MMTrail,一个大规模多模态视频-语言数据集,包含超过2000万个带有视觉字幕的预告片片段,以及200万个带有高质量多模态字幕的片段。预告片预览完整视频作品,并整合了上下文、视觉帧和背景音乐。特别是,预告片有两个主要优点:(1)主题多样,内容角色类型多样,例如电影、新闻和游戏。(2)相应的背景音乐是定制设计的,使其与视觉上下文更加连贯。基于这些见解,我们提出了一个系统性的字幕框架,实现了超过2.71万小时预告片视频的各种模态标注。为了确保字幕保留音乐视角,同时保持视觉上下文的权威性,我们利用先进的LLM自适应地合并所有标注。通过这种方式,我们的MMtrail数据集可能为细粒度的大型多模态语言模型训练铺平道路。在实验中,我们提供了评估指标和数据集上的基准结果,证明了我们标注的高质量及其对模型训练的有效性。
🔬 方法详解
问题定义:现有视频-语言数据集主要关注视觉和语言模态,忽略了音频信息,特别是背景音乐与视觉内容之间的关联。这导致模型难以理解视频的整体情感和上下文,限制了多模态理解能力。现有方法缺乏对音频模态的细粒度标注和有效融合机制。
核心思路:MMTrail的核心思路是构建一个包含高质量多模态标注的预告片数据集,其中不仅包含视觉字幕,还包含音乐描述。通过利用预告片中定制设计的背景音乐与视觉上下文的强相关性,以及先进的LLM进行标注融合,从而提供更全面、更精确的多模态信息。
技术框架:MMTrail数据集的构建包含以下主要阶段:1) 数据收集:收集超过2000万个预告片片段。2) 视觉字幕标注:为所有片段提供视觉字幕。3) 多模态字幕标注:为200万个高质量片段进行多模态标注,包括音乐描述。4) LLM标注融合:利用大型语言模型自适应地合并视觉和音乐标注,生成最终的多模态字幕。
关键创新:MMTrail的关键创新在于:1) 关注预告片视频中背景音乐与视觉内容的强相关性,提供音乐描述标注。2) 提出系统性的字幕框架,实现各种模态的标注。3) 利用先进的LLM自适应地融合不同模态的标注,保证标注的权威性和连贯性。与现有方法相比,MMTrail更注重多模态信息的全面性和精确性。
关键设计:在标注融合阶段,采用了LLM进行自适应合并,具体的LLM选择和prompt设计未知。数据集规模庞大,包含超过2.71万小时的预告片视频。评估指标包括常用的视频-语言理解指标,具体的指标名称和计算方法未知。
🖼️ 关键图片

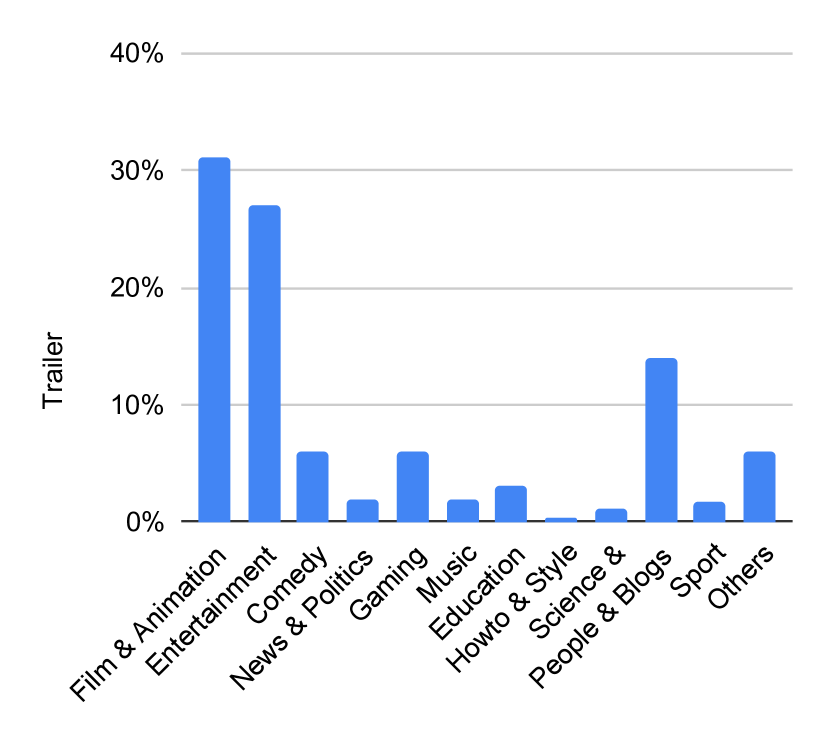
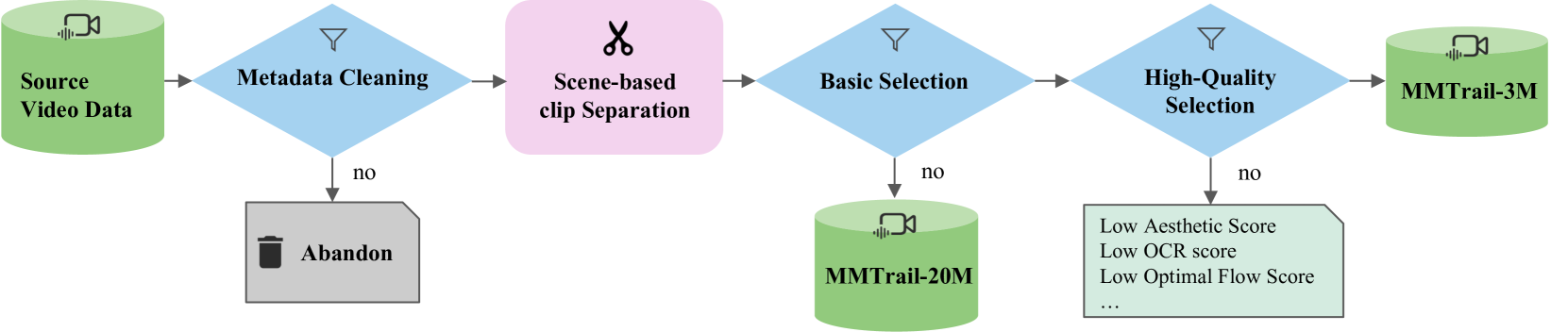
📊 实验亮点
论文提供了MMTrail数据集上的基准测试结果,展示了该数据集对模型训练的有效性。具体的性能数据、对比基线和提升幅度未知,但实验结果表明,使用MMTrail数据集训练的模型在多模态理解任务上表现良好,验证了标注的高质量和数据集的价值。
🎯 应用场景
MMTrail数据集可应用于多模态视频理解、视频摘要、音乐情感分析、跨模态检索等领域。该数据集能够促进多模态预训练模型的发展,提升模型在理解视频内容、捕捉情感信息和进行跨模态推理方面的能力。未来,基于MMTrail数据集训练的模型可以应用于智能推荐、内容审核、人机交互等场景。
📄 摘要(原文)
Massive multi-modality datasets play a significant role in facilitating the success of large video-language models. However, current video-language datasets primarily provide text descriptions for visual frames, considering audio to be weakly related information. They usually overlook exploring the potential of inherent audio-visual correlation, leading to monotonous annotation within each modality instead of comprehensive and precise descriptions. Such ignorance results in the difficulty of multiple cross-modality studies. To fulfill this gap, we present MMTrail, a large-scale multi-modality video-language dataset incorporating more than 20M trailer clips with visual captions, and 2M high-quality clips with multimodal captions. Trailers preview full-length video works and integrate context, visual frames, and background music. In particular, the trailer has two main advantages: (1) the topics are diverse, and the content characters are of various types, e.g., film, news, and gaming. (2) the corresponding background music is custom-designed, making it more coherent with the visual context. Upon these insights, we propose a systemic captioning framework, achieving various modality annotations with more than 27.1k hours of trailer videos. Here, to ensure the caption retains music perspective while preserving the authority of visual context, we leverage the advanced LLM to merge all annotations adaptively. In this fashion, our MMtrail dataset potentially paves the path for fine-grained large multimodal-language model training. In experiments, we provide evaluation metrics and benchmark results on our dataset, demonstrating the high quality of our annotation and its effectiveness for model training.