SynthVLM: Towards High-Quality and Efficient Synthesis of Image-Caption Datasets for Vision-Language Models
作者: Zheng Liu, Hao Liang, Bozhou Li, Wentao Xiong, Chong Chen, Conghui He, Wentao Zhang, Bin Cui
分类: cs.CV, cs.CL
发布日期: 2024-07-30 (更新: 2025-08-11)
💡 一句话要点
SynthVLM:面向视觉-语言模型的高质量高效图像-文本数据集合成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 数据合成 扩散模型 图像-文本对齐 视觉问答 多模态学习 数据集构建
📋 核心要点
- 现有视觉-语言模型训练依赖大规模数据集,但网络数据的效率、质量和对齐存在挑战。
- SynthVLM利用扩散模型,从高质量文本描述合成图像,生成精确对齐的图像-文本对。
- SynthVLM-100K数据集在VQA和MMLU任务上超越现有数据集,并提升了模型性能。
📝 摘要(中文)
视觉-语言模型(VLMs)近年来涌现,展现了卓越的视觉理解能力。然而,训练这些模型需要大规模数据集,这带来了与网络数据的效率、有效性和质量相关的挑战。本文介绍了一种新的数据合成和管理方法SynthVLM,用于生成图像-文本对。与传统的从图像生成文本的方法不同,SynthVLM利用先进的扩散模型和高质量的文本描述来合成和选择图像,从而创建精确对齐的图像-文本对。我们进一步介绍了SynthVLM-100K,一个由10万个精心策划和合成的图像-文本对组成的高质量数据集。在模型和人工评估中,SynthVLM-100K都优于传统的真实世界数据集。利用该数据集,我们开发了一个新的多模态大型语言模型(MLLM)系列,SynthVLM-7B和SynthVLM-13B,它们在各种视觉问答(VQA)任务上实现了最先进(SOTA)的性能。值得注意的是,我们的模型仅使用18%的预训练数据,就在大多数指标上优于LLaVA。此外,SynthVLM-7B和SynthVLM-13B在MMLU基准测试中也达到了SOTA性能,表明高质量的SynthVLM-100K数据集保留了语言能力。
🔬 方法详解
问题定义:现有视觉-语言模型训练依赖于大规模数据集,但从网络上获取的数据存在质量参差不齐、图像与文本描述对齐不精确等问题,这限制了模型的性能提升。传统方法通常是从图像生成文本,难以保证文本描述的准确性和多样性。
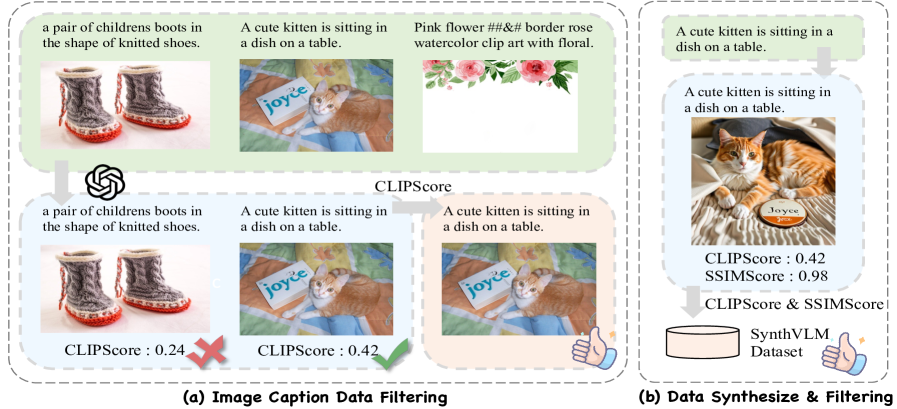
核心思路:SynthVLM的核心思路是反向操作,即从高质量的文本描述出发,利用扩散模型生成对应的图像。这种方法能够确保图像与文本描述的精确对齐,并可以通过控制文本描述来生成具有特定属性的图像,从而提高数据集的多样性和质量。
技术框架:SynthVLM的整体框架包括以下几个主要阶段:1) 文本描述收集:收集高质量的文本描述,作为图像生成的指导。2) 图像合成:利用先进的扩散模型,根据文本描述生成对应的图像。3) 数据集筛选:对生成的图像-文本对进行筛选,去除质量较差的样本,保留高质量的图像-文本对。4) 模型训练:使用合成的数据集训练视觉-语言模型。
关键创新:SynthVLM最重要的技术创新点在于其反向合成图像-文本对的方法。与传统方法相比,SynthVLM能够更好地控制图像的生成过程,从而生成更高质量、更精确对齐的图像-文本对。此外,SynthVLM还引入了数据集筛选机制,进一步提高了数据集的质量。
关键设计:SynthVLM的关键设计包括:1) 使用高质量的文本描述作为图像生成的指导,例如使用GPT-3等大型语言模型生成的文本描述。2) 选择合适的扩散模型,例如Stable Diffusion等,以生成高质量的图像。3) 设计有效的数据集筛选机制,例如使用图像质量评估指标和人工评估相结合的方法,去除质量较差的图像-文本对。
🖼️ 关键图片


📊 实验亮点
SynthVLM-100K数据集在模型和人工评估中均优于传统真实世界数据集。使用该数据集训练的SynthVLM-7B和SynthVLM-13B模型在VQA任务上取得了SOTA性能,且仅使用18%的预训练数据就在大多数指标上超越了LLaVA。此外,这两个模型在MMLU基准测试中也达到了SOTA性能,证明了数据集的有效性。
🎯 应用场景
SynthVLM具有广泛的应用前景,可用于生成高质量的视觉-语言数据集,从而提升各种视觉-语言模型的性能,例如图像描述、视觉问答、图像检索等。该方法还可以应用于生成特定领域的图像-文本数据集,例如医学图像、遥感图像等,从而促进相关领域的发展。未来,SynthVLM有望成为视觉-语言模型训练的重要工具。
📄 摘要(原文)
Vision-Language Models (VLMs) have recently emerged, demonstrating remarkable vision-understanding capabilities. However, training these models requires large-scale datasets, which brings challenges related to efficiency, effectiveness, and quality of web data. In this paper, we introduce SynthVLM, a new data synthesis and curation method for generating image-caption pairs. Unlike traditional methods, where captions are generated from images, SynthVLM utilizes advanced diffusion models and high-quality captions to synthesize and select images from text captions, thereby creating precisely aligned image-text pairs. We further introduce SynthVLM-100K, a high-quality dataset consisting of 100K curated and synthesized image-caption pairs. In both model and human evaluations, SynthVLM-100K outperforms traditional real-world datasets. Leveraging this dataset, we develop a new family of multimodal large language models (MLLMs), SynthVLM-7B and SynthVLM-13B, which achieve state-of-the-art (SOTA) performance on various vision question-answering (VQA) tasks. Notably, our models outperform LLaVA across most metrics with only 18\% pretrain data. Furthermore, SynthVLM-7B and SynthVLM-13B attain SOTA performance on the MMLU benchmark, demonstrating that the high-quality SynthVLM-100K dataset preserves language abilities.