Effectively Leveraging CLIP for Generating Situational Summaries of Images and Videos
作者: Dhruv Verma, Debaditya Roy, Basura Fernando
分类: cs.CV
发布日期: 2024-07-30 (更新: 2025-03-18)
备注: 38 pages, 12 figures. arXiv admin note: text overlap with arXiv:2307.00586
💡 一句话要点
提出ClipSitu,利用CLIP有效生成图像和视频的情境摘要,实现卓越的情境识别与定位。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情境识别 CLIP模型 多模态融合 语义角色标注 交叉注意力 图像理解 视频理解
📋 核心要点
- 现有情境识别方法在处理图像和视频时,常因歧义和缺乏上下文而难以生成准确预测。
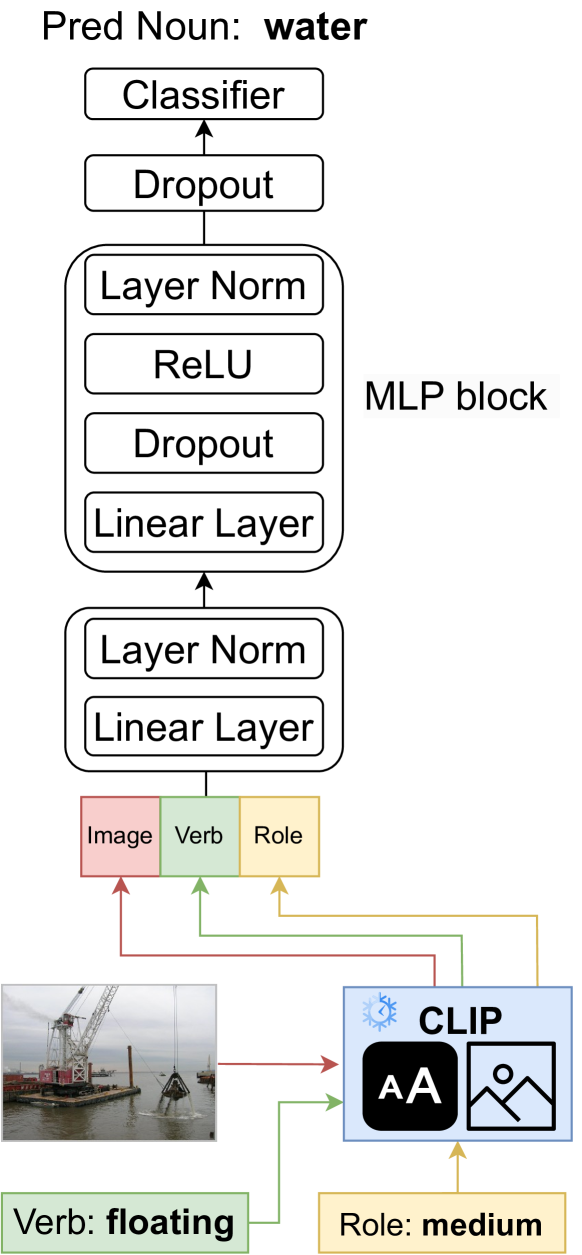
- ClipSitu利用CLIP模型,通过图像、动词和角色嵌入,预测与动词相关的所有角色名词,实现情境理解。
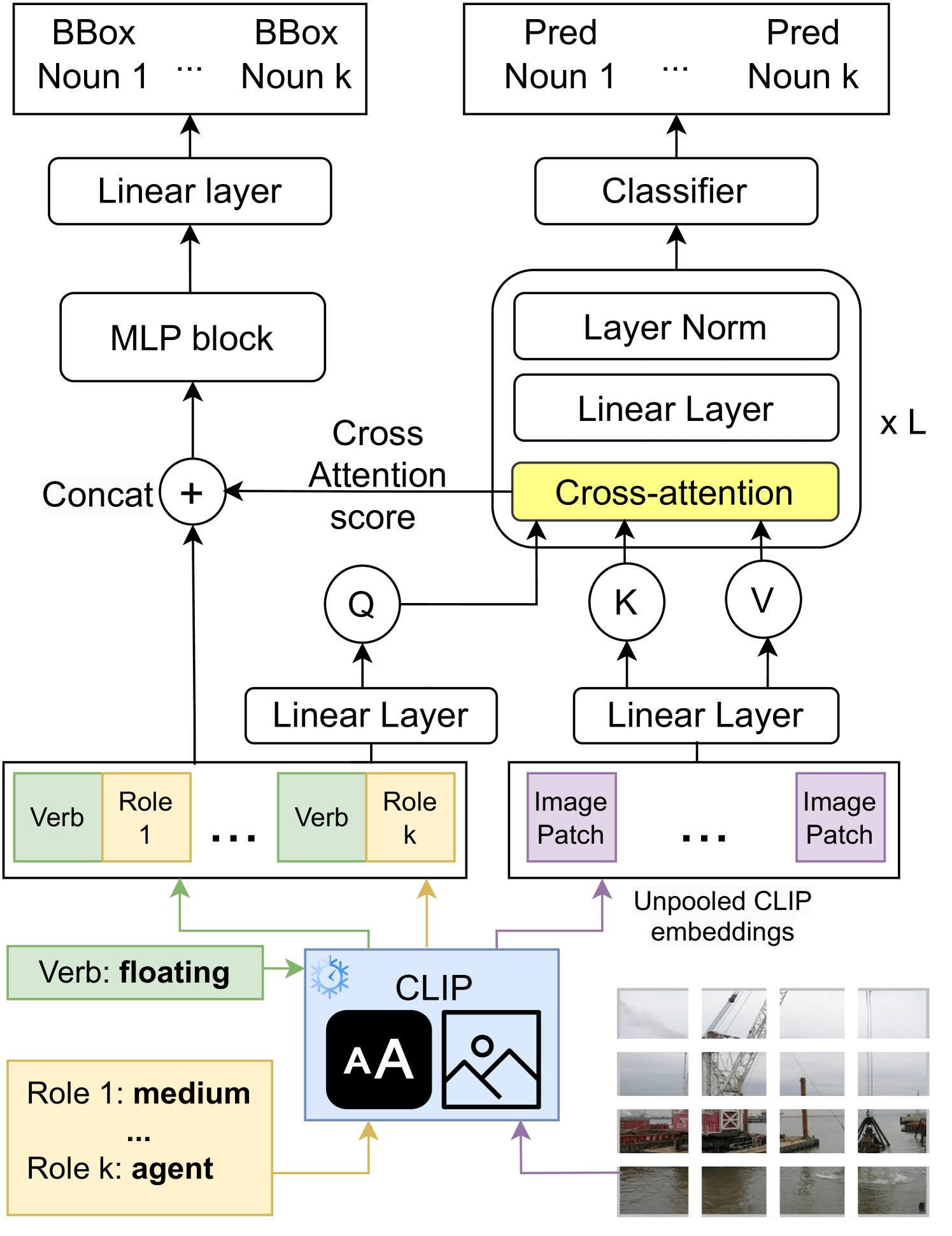
- ClipSitu XTF通过交叉注意力Transformer增强语义角色查询与视觉token的连接,提升情境识别性能。
📝 摘要(中文)
情境识别是指智能体基于可用信息和感官输入来识别和理解各种情境或上下文的能力。它涉及解释环境数据的认知过程,以确定正在发生的事情、涉及的因素以及导致这些情境的行动。在基于计算机视觉的情境识别中,这种情境解释被形式化为语义角色标注问题。图像和视频中描绘的情境包含关键信息,对于图像和视频字幕、多媒体检索、自主系统和事件监控等各种应用至关重要。然而,现有方法通常难以应对歧义和缺乏上下文的问题,难以生成有意义和准确的预测。本文提出ClipSitu,利用CLIP等模态模型,无需完全微调即可在情境识别和定位任务中实现最先进的结果。ClipSitu利用基于CLIP的图像、动词和角色嵌入来预测满足与动词相关的所有角色的名词,从而全面理解所描绘的场景。通过交叉注意力Transformer,ClipSitu XTF增强了语义角色查询和视觉token表示之间的连接,从而在情境识别中实现了卓越的性能。我们还提出了一个动词相关的角色预测模型,该模型具有接近完美的准确性,从而创建了一个端到端框架,用于生成领域外图像的情境摘要。我们表明,与通用字幕相比,情境摘要使我们的ClipSitu模型能够生成具有减少歧义的结构化描述。最后,我们将ClipSitu扩展到视频情境识别,以展示其多功能性,并产生与最先进方法相当的性能。
🔬 方法详解
问题定义:论文旨在解决图像和视频情境识别中存在的歧义性和上下文信息不足的问题。现有方法在生成有意义和准确的预测方面存在困难,无法充分理解图像或视频中描绘的复杂场景。
核心思路:论文的核心思路是利用预训练的CLIP模型,通过其强大的多模态表示能力,将图像、动词和角色信息进行有效融合,从而实现更准确的情境识别。这种方法避免了从头开始训练模型的需要,并能够利用CLIP模型学习到的丰富语义知识。
技术框架:ClipSitu框架主要包含以下几个模块:1) CLIP图像编码器:用于提取图像的视觉特征。2) 动词和角色嵌入:使用预训练的词嵌入或通过训练得到动词和角色的向量表示。3) 角色预测模块:预测与给定动词相关的角色。4) 跨模态融合模块:将图像特征、动词嵌入和角色嵌入进行融合,预测每个角色对应的名词。ClipSitu XTF在此基础上引入了交叉注意力Transformer,以增强语义角色查询和视觉token表示之间的连接。
关键创新:该论文的关键创新在于有效地利用了预训练的CLIP模型进行情境识别,并提出了ClipSitu XTF,通过交叉注意力机制增强了视觉和语义信息的融合。此外,论文还提出了一个动词相关的角色预测模型,用于生成领域外图像的情境摘要。
关键设计:ClipSitu的关键设计包括:1) 使用CLIP的图像编码器提取视觉特征。2) 使用预训练的词嵌入表示动词和角色。3) 使用交叉注意力Transformer (ClipSitu XTF) 融合视觉和语义信息。4) 设计动词相关的角色预测模型,提高角色预测的准确性。损失函数方面,可能采用了交叉熵损失或类似的损失函数来训练角色预测和名词预测模块。
🖼️ 关键图片
📊 实验亮点
ClipSitu在情境识别和定位任务中取得了最先进的结果,无需完全微调。ClipSitu XTF通过交叉注意力Transformer增强了语义角色查询和视觉token表示之间的连接,从而在情境识别中实现了卓越的性能。动词相关的角色预测模型具有接近完美的准确性,能够为领域外图像生成情境摘要。
🎯 应用场景
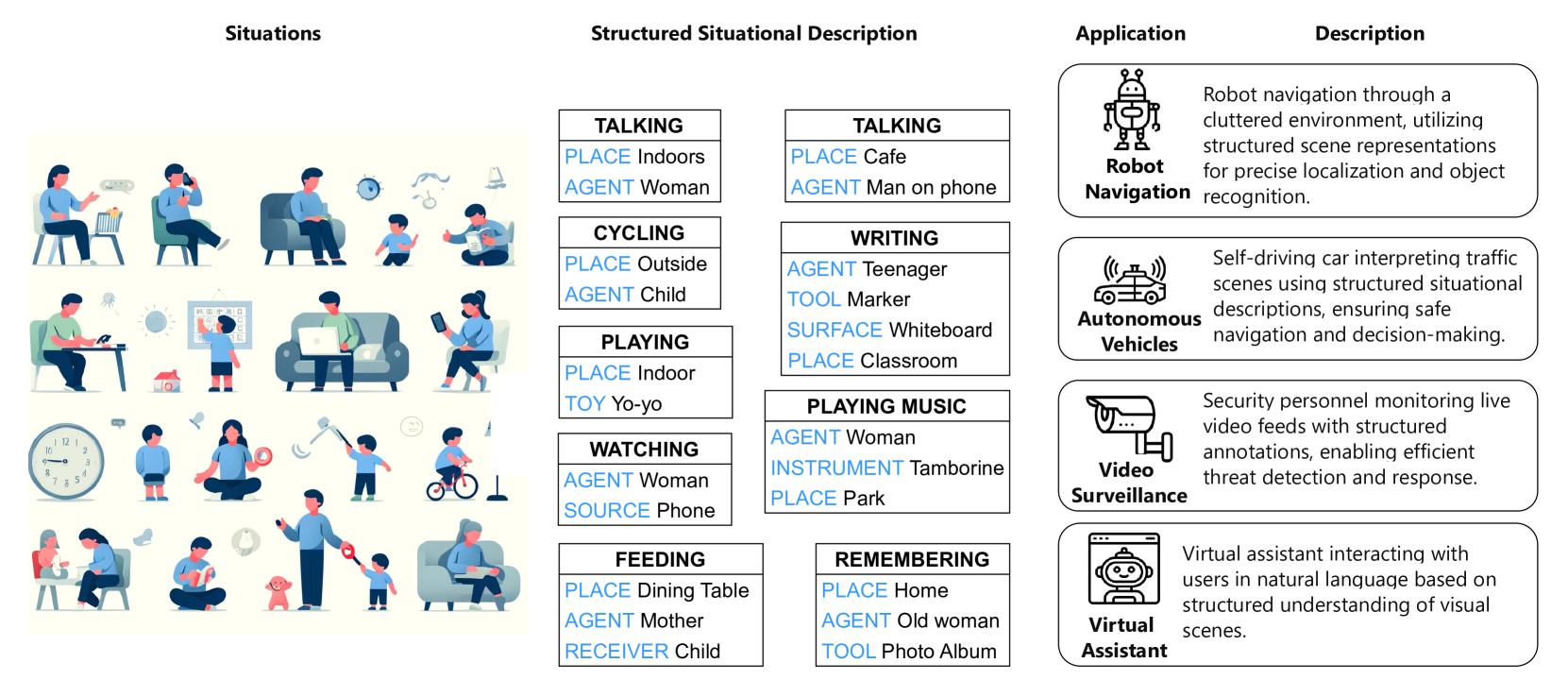
该研究成果可广泛应用于图像和视频理解领域,例如图像和视频字幕生成、多媒体检索、智能监控、自动驾驶等。通过提供更准确和全面的情境信息,可以提升这些应用的用户体验和性能。未来,该技术有望应用于更复杂的场景理解和人机交互任务中。
📄 摘要(原文)
Situation recognition refers to the ability of an agent to identify and understand various situations or contexts based on available information and sensory inputs. It involves the cognitive process of interpreting data from the environment to determine what is happening, what factors are involved, and what actions caused those situations. This interpretation of situations is formulated as a semantic role labeling problem in computer vision-based situation recognition. Situations depicted in images and videos hold pivotal information, essential for various applications like image and video captioning, multimedia retrieval, autonomous systems and event monitoring. However, existing methods often struggle with ambiguity and lack of context in generating meaningful and accurate predictions. Leveraging multimodal models such as CLIP, we propose ClipSitu, which sidesteps the need for full fine-tuning and achieves state-of-the-art results in situation recognition and localization tasks. ClipSitu harnesses CLIP-based image, verb, and role embeddings to predict nouns fulfilling all the roles associated with a verb, providing a comprehensive understanding of depicted scenarios. Through a cross-attention Transformer, ClipSitu XTF enhances the connection between semantic role queries and visual token representations, leading to superior performance in situation recognition. We also propose a verb-wise role prediction model with near-perfect accuracy to create an end-to-end framework for producing situational summaries for out-of-domain images. We show that situational summaries empower our ClipSitu models to produce structured descriptions with reduced ambiguity compared to generic captions. Finally, we extend ClipSitu to video situation recognition to showcase its versatility and produce comparable performance to state-of-the-art methods.