Monocular Human-Object Reconstruction in the Wild
作者: Chaofan Huo, Ye Shi, Jingya Wang
分类: cs.CV, cs.GR
发布日期: 2024-07-30 (更新: 2024-07-31)
备注: Accepted by MM '24
💡 一句话要点
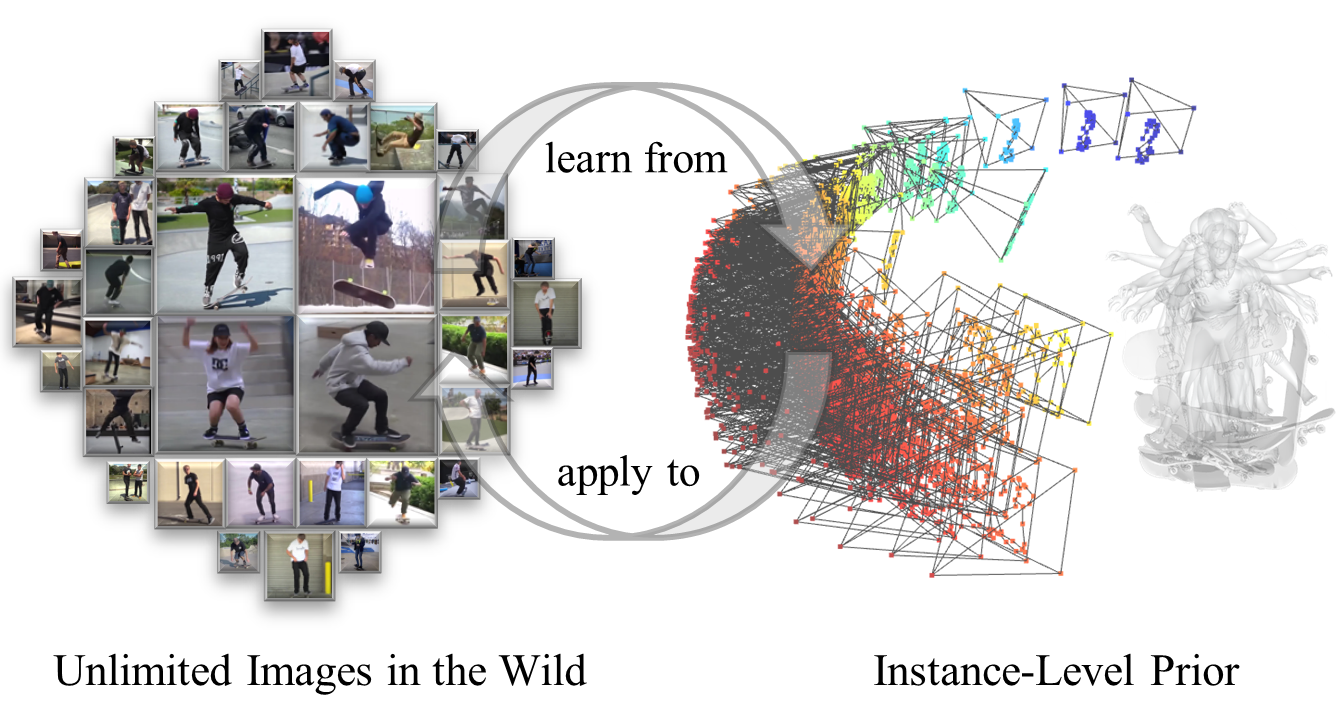
提出一种2D监督方法,用于野外场景下单目人体-物体交互3D重建
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 人体-物体交互 3D重建 2D监督学习 空间关系先验 流模型
📋 核心要点
- 现有方法在受控环境学习人体-物体交互先验,难以泛化到真实野外场景。
- 提出一种2D监督方法,仅从2D图像学习3D人体-物体空间关系先验。
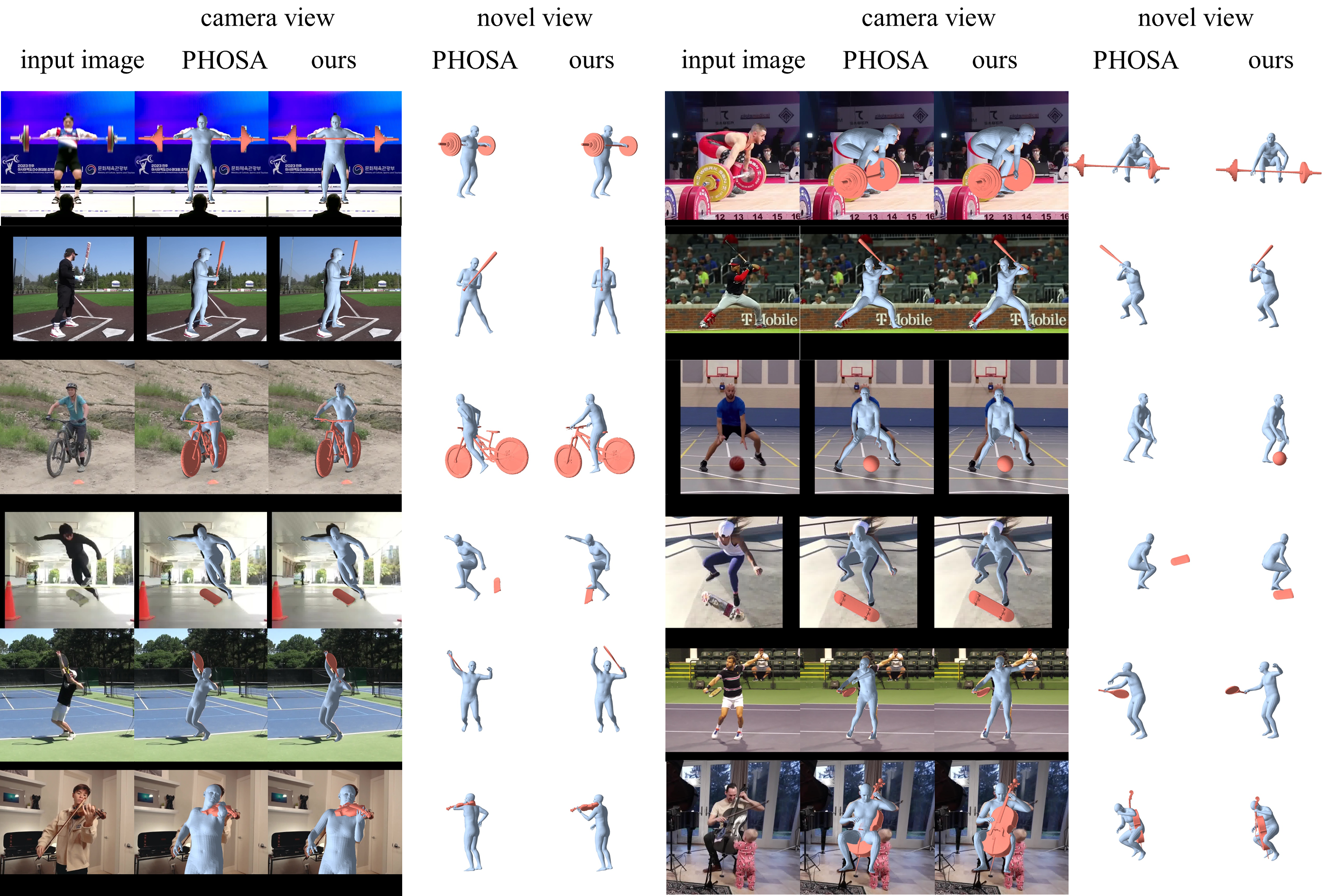
- 实验表明,该方法在野外图像上具有更好的泛化性和交互多样性,性能优于现有方法。
📝 摘要(中文)
本文提出了一种2D监督方法,旨在学习3D人体-物体空间关系的先验知识,从而实现图像中人体-物体交互的重建。现有方法通常在受控环境中收集数据并学习先验知识,但泛化到真实场景时效果不佳。为了克服这一局限,本文方法仅利用野外2D图像学习3D人体-物体空间关系先验。该方法使用基于流的神经网络学习数据集中每张图像的2D人体-物体关键点布局和视口的先验分布。通过将该先验应用于后优化阶段,调整人体和物体之间的相对姿态,从而验证了从2D图像学习到的先验知识在人体-物体重建任务中的有效性。为了验证和评估该方法在野外图像上的性能,我们从YouTube收集了WildHOI数据集,该数据集包含真实场景中与8个物体的各种交互。在室内BEHAVE数据集和室外WildHOI数据集上进行的实验表明,即使仅使用2D布局信息,该方法在BEHAVE数据集上也能达到与完全3D监督方法几乎相当的性能,并且在野外图像的泛化性和交互多样性方面优于以前的方法。
🔬 方法详解
问题定义:现有的人体-物体交互3D重建方法依赖于在受控环境下收集的3D数据,这限制了它们在真实世界场景中的应用。这些方法难以处理野外图像中复杂的光照、遮挡和视角变化,导致重建精度下降。因此,如何仅利用2D图像信息,学习到适用于野外场景的人体-物体交互先验知识,是一个亟待解决的问题。
核心思路:本文的核心思路是利用2D图像中人体和物体的关键点布局信息,学习它们之间的空间关系先验。通过学习2D关键点布局的分布,可以推断出3D空间中人体和物体可能的相对姿态。这种方法避免了对3D数据的依赖,从而提高了模型的泛化能力。
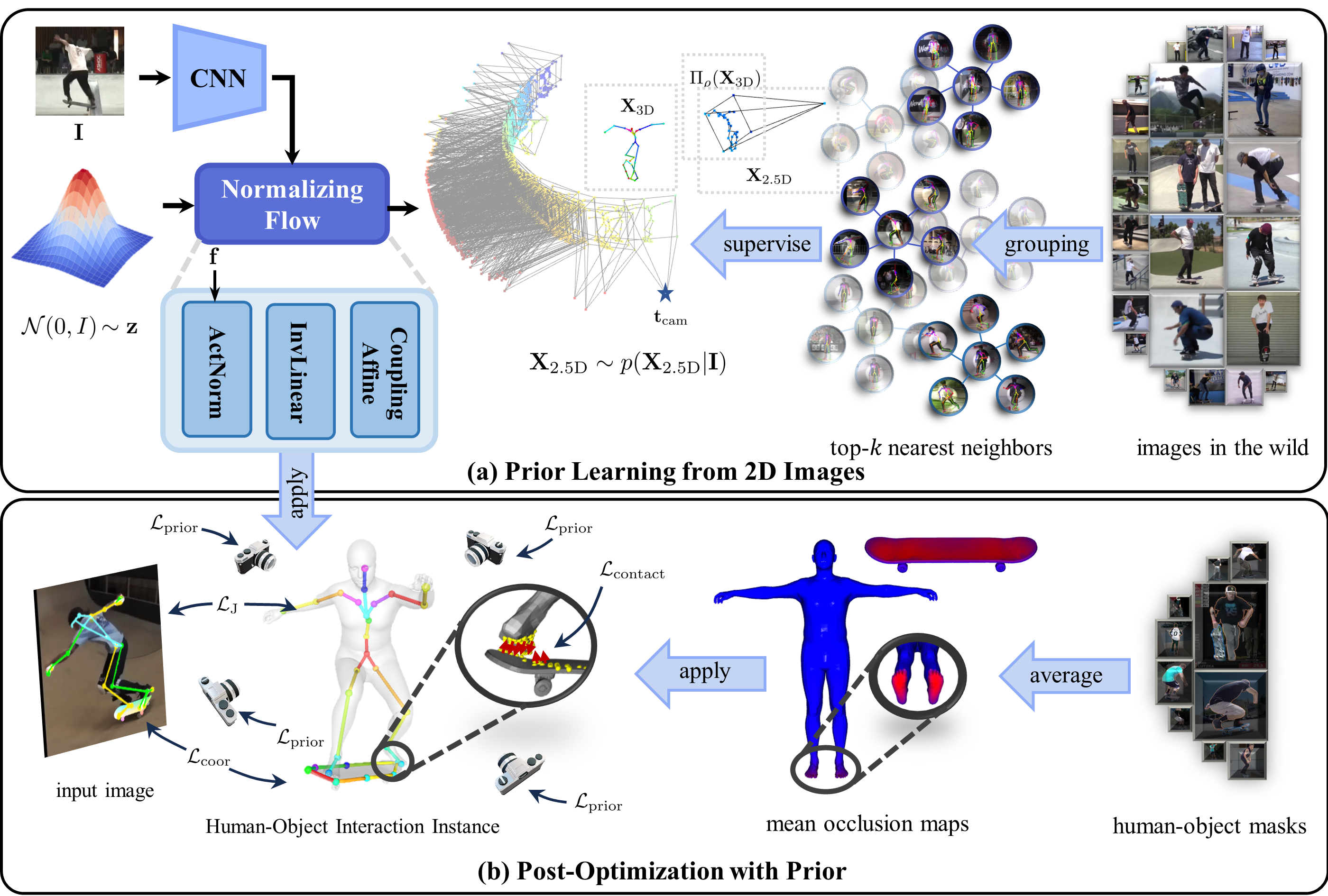
技术框架:该方法主要包含两个阶段:先验学习阶段和后优化阶段。在先验学习阶段,使用一个基于流的神经网络(Flow-based Neural Network)学习2D人体-物体关键点布局和视口的先验分布。在后优化阶段,将学习到的先验知识应用于人体-物体重建任务,通过调整人体和物体之间的相对姿态,优化重建结果。
关键创新:该方法最重要的创新点在于,它提出了一种仅利用2D图像信息学习3D人体-物体空间关系先验的方法。与现有方法相比,该方法不需要3D监督数据,从而提高了模型的泛化能力和适用性。此外,使用基于流的神经网络学习先验分布,可以更好地捕捉复杂的人体-物体交互模式。
关键设计:在先验学习阶段,使用基于流的神经网络学习2D人体-物体关键点布局和视口的先验分布。具体来说,输入是2D关键点坐标和视口参数,输出是先验分布的参数。损失函数包括重构损失和正则化损失,用于保证学习到的先验分布的准确性和平滑性。在后优化阶段,使用学习到的先验分布作为正则项,调整人体和物体之间的相对姿态,优化重建结果。
🖼️ 关键图片
📊 实验亮点
该方法在BEHAVE数据集上取得了与3D监督方法几乎相当的性能,即使仅使用了2D布局信息。在WildHOI数据集上,该方法在泛化性和交互多样性方面优于现有方法。WildHOI数据集的发布也为该领域的研究提供了新的基准。
🎯 应用场景
该研究成果可应用于人机交互、虚拟现实、增强现实、机器人等领域。例如,在人机交互中,可以利用该方法理解用户与物体的交互意图,从而提供更自然、更智能的交互体验。在机器人领域,可以帮助机器人更好地理解周围环境,从而实现更安全、更高效的自主导航和操作。
📄 摘要(原文)
Learning the prior knowledge of the 3D human-object spatial relation is crucial for reconstructing human-object interaction from images and understanding how humans interact with objects in 3D space. Previous works learn this prior from datasets collected in controlled environments, but due to the diversity of domains, they struggle to generalize to real-world scenarios. To overcome this limitation, we present a 2D-supervised method that learns the 3D human-object spatial relation prior purely from 2D images in the wild. Our method utilizes a flow-based neural network to learn the prior distribution of the 2D human-object keypoint layout and viewports for each image in the dataset. The effectiveness of the prior learned from 2D images is demonstrated on the human-object reconstruction task by applying the prior to tune the relative pose between the human and the object during the post-optimization stage. To validate and benchmark our method on in-the-wild images, we collect the WildHOI dataset from the YouTube website, which consists of various interactions with 8 objects in real-world scenarios. We conduct the experiments on the indoor BEHAVE dataset and the outdoor WildHOI dataset. The results show that our method achieves almost comparable performance with fully 3D supervised methods on the BEHAVE dataset, even if we have only utilized the 2D layout information, and outperforms previous methods in terms of generality and interaction diversity on in-the-wild images.