FlexAttention for Efficient High-Resolution Vision-Language Models
作者: Junyan Li, Delin Chen, Tianle Cai, Peihao Chen, Yining Hong, Zhenfang Chen, Yikang Shen, Chuang Gan
分类: cs.CV
发布日期: 2024-07-29
备注: Accepted by ECCV 2024
💡 一句话要点
FlexAttention:一种高效高分辨率视觉-语言模型注意力机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 高分辨率图像 注意力机制 计算效率 多模态学习
📋 核心要点
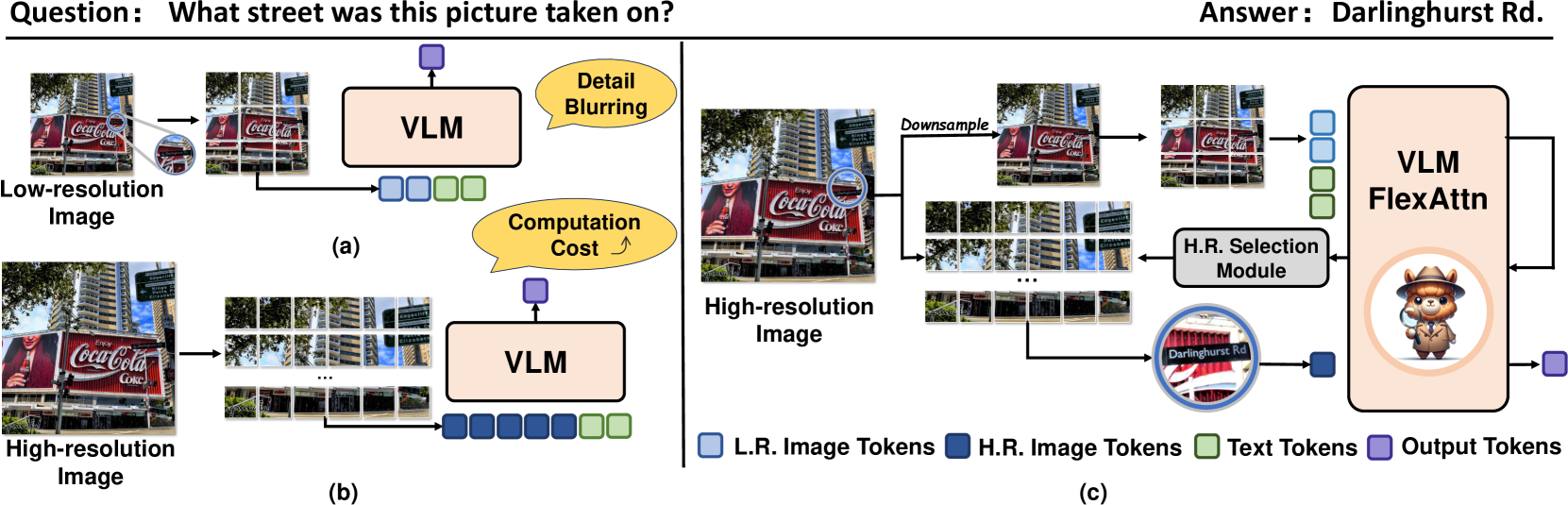
- 现有高分辨率视觉-语言模型计算量大,因为它们需要处理所有高分辨率图像tokens。
- FlexAttention通过选择少量高分辨率tokens和所有低分辨率tokens来计算注意力,从而降低计算成本。
- 实验表明,FlexAttention在多个多模态基准测试中优于现有模型,同时显著降低了计算成本。
📝 摘要(中文)
当前的高分辨率视觉-语言模型将图像编码为高分辨率图像tokens,并穷尽地使用所有这些tokens来计算注意力,这显著增加了计算成本。为了解决这个问题,我们提出了FlexAttention,一种灵活的注意力机制,用于高效的高分辨率视觉-语言模型。具体来说,高分辨率图像被编码为高分辨率tokens和低分辨率tokens。只有低分辨率tokens和少量选定的高分辨率tokens被用于计算注意力图,这大大降低了计算成本。高分辨率tokens通过高分辨率选择模块选择,该模块可以基于输入的注意力图检索相关区域的tokens。然后,选定的高分辨率tokens与低分辨率tokens和文本tokens连接,并输入到分层自注意力层,该层产生可用于下一步高分辨率token选择的注意力图。分层自注意力过程和高分辨率token选择过程针对每个注意力层迭代执行。在多模态基准测试上的实验证明,我们的FlexAttention优于现有的高分辨率VLM(例如,在V* Bench中相对提升约9%,在TextVQA中相对提升约7%),同时显著降低了近40%的计算成本。
🔬 方法详解
问题定义:现有高分辨率视觉-语言模型在处理高分辨率图像时,需要对所有图像tokens进行注意力计算,导致计算成本显著增加。这限制了模型在资源受限环境中的应用,也阻碍了模型处理更高分辨率图像的能力。
核心思路:FlexAttention的核心思想是只选择少量与当前任务相关的高分辨率图像tokens进行注意力计算,同时保留所有低分辨率图像tokens。这样既能减少计算量,又能保证模型能够关注到图像中的关键区域。通过迭代地选择高分辨率tokens,模型可以逐步聚焦于更精细的图像特征。
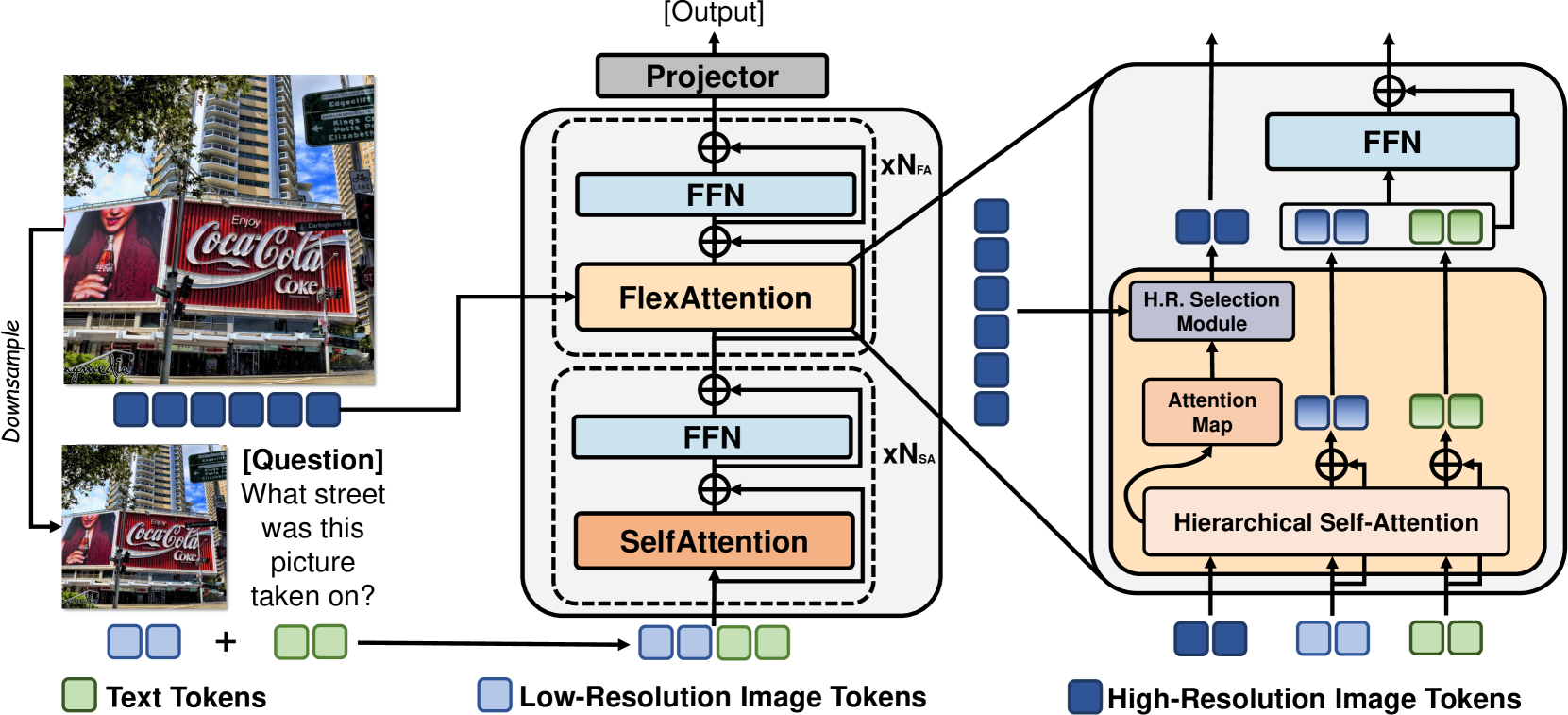
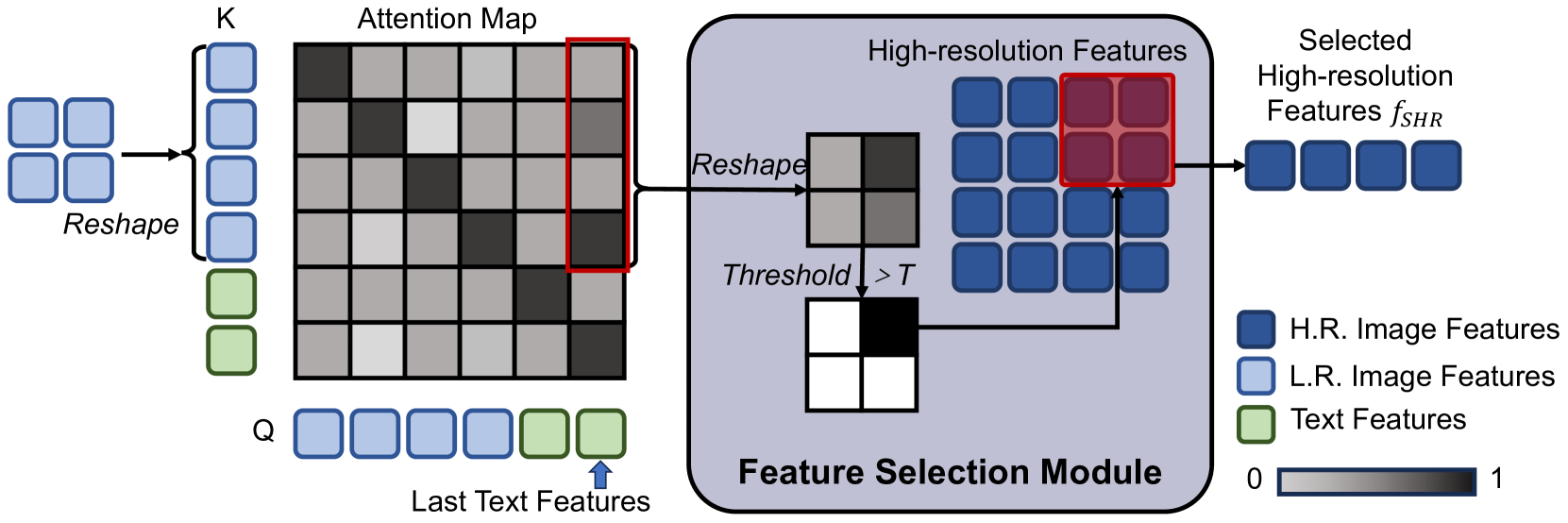
技术框架:FlexAttention包含以下主要模块:1) 高分辨率和低分辨率图像编码器,用于将输入图像编码为两种不同分辨率的tokens;2) 高分辨率token选择模块,用于根据输入的注意力图选择相关区域的高分辨率tokens;3) 分层自注意力层,用于融合低分辨率tokens、选定的高分辨率tokens和文本tokens,并生成新的注意力图。整个流程是迭代的,每一层分层自注意力层都会生成新的注意力图,用于下一轮的高分辨率token选择。
关键创新:FlexAttention的关键创新在于其灵活的注意力机制,它能够根据输入动态地选择需要关注的高分辨率图像tokens。这种选择机制使得模型能够在保持性能的同时显著降低计算成本。与传统的全局注意力机制相比,FlexAttention更加高效,更适合处理高分辨率图像。
关键设计:高分辨率token选择模块的设计至关重要,它需要能够准确地识别出与当前任务相关的图像区域。论文中使用了基于注意力图的token选择方法,即选择注意力权重较高的tokens。分层自注意力层的设计也需要考虑如何有效地融合不同分辨率的tokens。具体的参数设置和网络结构细节在论文中进行了详细描述,但此处未给出。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FlexAttention在V* Bench和TextVQA等基准测试中分别取得了约9%和7%的相对性能提升,同时将计算成本降低了近40%。这些结果表明,FlexAttention能够在保持甚至提升模型性能的同时,显著降低计算成本,使其成为一种高效的高分辨率视觉-语言模型注意力机制。
🎯 应用场景
FlexAttention具有广泛的应用前景,例如图像描述、视觉问答、图像检索等。它可以应用于需要处理高分辨率图像的场景,例如医学图像分析、遥感图像处理等。通过降低计算成本,FlexAttention使得高分辨率视觉-语言模型能够在资源受限的设备上运行,从而促进了其在移动设备和嵌入式系统中的应用。
📄 摘要(原文)
Current high-resolution vision-language models encode images as high-resolution image tokens and exhaustively take all these tokens to compute attention, which significantly increases the computational cost. To address this problem, we propose FlexAttention, a flexible attention mechanism for efficient high-resolution vision-language models. Specifically, a high-resolution image is encoded both as high-resolution tokens and low-resolution tokens, where only the low-resolution tokens and a few selected high-resolution tokens are utilized to calculate the attention map, which greatly shrinks the computational cost. The high-resolution tokens are selected via a high-resolution selection module which could retrieve tokens of relevant regions based on an input attention map. The selected high-resolution tokens are then concatenated to the low-resolution tokens and text tokens, and input to a hierarchical self-attention layer which produces an attention map that could be used for the next-step high-resolution token selection. The hierarchical self-attention process and high-resolution token selection process are performed iteratively for each attention layer. Experiments on multimodal benchmarks prove that our FlexAttention outperforms existing high-resolution VLMs (e.g., relatively ~9% in V* Bench, ~7% in TextVQA), while also significantly reducing the computational cost by nearly 40%.