Advancing Multimodal Large Language Models in Chart Question Answering with Visualization-Referenced Instruction Tuning
作者: Xingchen Zeng, Haichuan Lin, Yilin Ye, Wei Zeng
分类: cs.CV, cs.AI
发布日期: 2024-07-29 (更新: 2024-08-11)
备注: 11 pages, 7 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出可视化参考指令调优方法,提升多模态大语言模型在图表问答任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图表问答 多模态大语言模型 指令调优 数据增强 视觉编码 混合分辨率 数据引擎
📋 核心要点
- 现有图表问答数据集侧重数据量,忽略了细粒度视觉编码和QA任务的多样性,导致数据分布与实际场景不符。
- 提出可视化参考指令调优方法,通过数据引擎过滤和LLM生成增强数据,并解冻视觉编码器进行混合分辨率训练。
- 实验结果表明,即使使用更少的训练数据,该模型在图表问答基准测试中也优于现有最先进的模型。
📝 摘要(中文)
新兴的多模态大语言模型(MLLM)在图表问答(CQA)方面展现出巨大的潜力。目前的研究主要集中于通过数据收集和合成来扩大训练数据集(即图表、数据表和问答(QA)对)。然而,我们对现有MLLM和CQA数据集的实证研究揭示了显著的差距。首先,当前的数据收集和合成侧重于数据量,缺乏对细粒度视觉编码和QA任务的考虑,导致数据分布不平衡,与实际CQA场景存在差异。其次,现有的工作遵循最初为自然图像设计的MLLM的训练方法,未能充分探索对图表独特特征(如丰富的文本元素)的适应。为了填补这一空白,我们提出了一种可视化参考指令调优方法,以指导训练数据集的增强和模型开发。具体来说,我们提出了一个新的数据引擎,以有效地从现有数据集中过滤多样化和高质量的数据,并随后使用基于LLM的生成技术来改进和扩充数据,从而更好地与实际QA任务和视觉编码对齐。然后,为了促进对图表特征的适应,我们利用丰富的数据来训练MLLM,通过解冻视觉编码器并结合混合分辨率适应策略来增强细粒度识别。实验结果验证了我们方法的有效性。即使使用较少的训练样本,我们的模型在已建立的基准测试中始终优于最先进的CQA模型。我们还贡献了一个数据集分割,作为未来研究的基准。本文的源代码和数据集可在https://github.com/zengxingchen/ChartQA-MLLM获得。
🔬 方法详解
问题定义:论文旨在解决现有图表问答(CQA)模型在处理实际场景时,由于训练数据分布不平衡和对图表特征适应不足而导致的性能瓶颈。现有方法主要关注数据量的增加,忽略了细粒度视觉编码和QA任务的多样性,并且沿用自然图像的训练方式,未能充分利用图表中的文本信息等特征。
核心思路:论文的核心思路是通过可视化参考指令调优,更有效地利用现有数据,并使模型更好地适应图表问答任务的特点。具体来说,首先通过数据引擎筛选高质量数据,然后利用LLM生成技术增强数据,使其更符合实际QA任务和视觉编码。同时,在模型训练阶段,解冻视觉编码器,并采用混合分辨率适应策略,以增强对图表细粒度特征的识别。
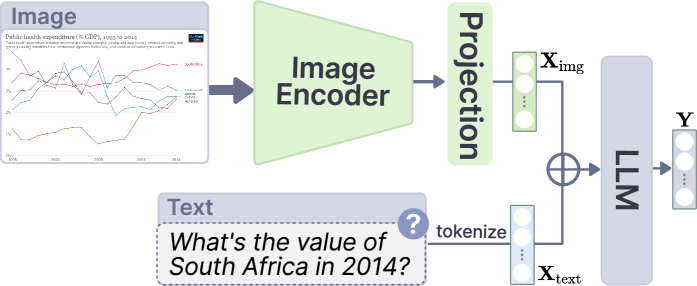
技术框架:整体框架包含两个主要部分:数据增强和模型训练。数据增强部分,首先使用数据引擎从现有数据集中过滤高质量数据,然后利用LLM生成技术对数据进行精炼和扩充。模型训练部分,使用增强后的数据训练MLLM,其中解冻视觉编码器,并采用混合分辨率适应策略。
关键创新:论文的关键创新在于提出了可视化参考指令调优方法,该方法通过数据引擎和LLM生成技术,有效地增强了训练数据,使其更符合实际图表问答场景。此外,解冻视觉编码器和混合分辨率适应策略,使得模型能够更好地适应图表特征,从而提升了性能。
关键设计:数据引擎的设计旨在筛选出多样化和高质量的数据。LLM生成技术用于生成更符合实际QA任务和视觉编码的数据。混合分辨率适应策略的具体实现细节未知,但其目的是增强模型对图表细粒度特征的识别能力。损失函数和网络结构等细节未在摘要中明确说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使使用更少的训练样本,该模型在已建立的图表问答基准测试中始终优于最先进的模型,验证了所提出方法在提升图表问答性能方面的有效性。具体性能提升数据和对比基线未在摘要中明确说明,属于未知信息。
🎯 应用场景
该研究成果可应用于智能报表分析、数据可视化辅助、金融数据解读等领域。通过提升图表问答系统的准确性和效率,可以帮助用户更快速地理解和利用图表信息,辅助决策,具有重要的实际应用价值和商业前景。
📄 摘要(原文)
Emerging multimodal large language models (MLLMs) exhibit great potential for chart question answering (CQA). Recent efforts primarily focus on scaling up training datasets (i.e., charts, data tables, and question-answer (QA) pairs) through data collection and synthesis. However, our empirical study on existing MLLMs and CQA datasets reveals notable gaps. First, current data collection and synthesis focus on data volume and lack consideration of fine-grained visual encodings and QA tasks, resulting in unbalanced data distribution divergent from practical CQA scenarios. Second, existing work follows the training recipe of the base MLLMs initially designed for natural images, under-exploring the adaptation to unique chart characteristics, such as rich text elements. To fill the gap, we propose a visualization-referenced instruction tuning approach to guide the training dataset enhancement and model development. Specifically, we propose a novel data engine to effectively filter diverse and high-quality data from existing datasets and subsequently refine and augment the data using LLM-based generation techniques to better align with practical QA tasks and visual encodings. Then, to facilitate the adaptation to chart characteristics, we utilize the enriched data to train an MLLM by unfreezing the vision encoder and incorporating a mixture-of-resolution adaptation strategy for enhanced fine-grained recognition. Experimental results validate the effectiveness of our approach. Even with fewer training examples, our model consistently outperforms state-of-the-art CQA models on established benchmarks. We also contribute a dataset split as a benchmark for future research. Source codes and datasets of this paper are available at https://github.com/zengxingchen/ChartQA-MLLM.