MaskInversion: Localized Embeddings via Optimization of Explainability Maps
作者: Walid Bousselham, Sofian Chaybouti, Christian Rupprecht, Vittorio Ferrari, Hilde Kuehne
分类: cs.CV
发布日期: 2024-07-29
备注: Project page: https://walidbousselham.com/MaskInversion
💡 一句话要点
提出MaskInversion,通过优化可解释性图谱为图像局部区域生成上下文相关的嵌入表示。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 局部区域表示 可解释性图谱 嵌入优化 上下文感知
📋 核心要点
- 现有视觉-语言模型在图像区域表示方面存在局限,难以准确捕捉局部上下文信息。
- MaskInversion通过优化嵌入token的可解释性图谱,使其与目标区域掩码对齐,从而生成上下文感知的局部区域嵌入。
- 实验表明,MaskInversion在开放词汇类别检索、指代表达式理解等任务上优于现有方法,并在多个数据集上取得了SOTA结果。
📝 摘要(中文)
CLIP等视觉-语言基础模型在全局视觉-语言对齐方面取得了显著成果,但在为特定图像区域创建表示方面仍存在局限性。为了解决这个问题,我们提出了MaskInversion,一种利用预训练基础模型(如CLIP)的特征表示,在测试时为由掩码指定的查询图像区域生成上下文感知嵌入的方法。MaskInversion首先初始化一个嵌入token,并将其从基础模型导出的可解释性图谱与查询掩码进行比较。然后,通过最小化其可解释性图谱与查询掩码之间的差异,不断优化嵌入token以逼近查询区域。在此过程中,只更新嵌入向量,而底层基础模型保持冻结,从而允许MaskInversion与任何预训练模型一起使用。由于导出可解释性图谱涉及计算梯度,这可能代价高昂,因此我们提出了一种梯度分解策略来简化此计算。学习到的区域表示可用于广泛的任务,包括开放词汇类别检索、指代表达式理解,以及局部字幕和图像生成。我们在PascalVOC、MSCOCO、RefCOCO和OpenImagesV7等多个数据集上评估了所提出的方法在所有这些任务上的性能,并展示了其相对于其他SOTA方法的优势。
🔬 方法详解
问题定义:现有视觉-语言模型,如CLIP,在全局层面的视觉-语言对齐表现出色,但在处理图像局部区域时,其表示能力受到限制。现有方法难以准确捕捉局部区域的上下文信息,导致在细粒度视觉任务中表现不佳。
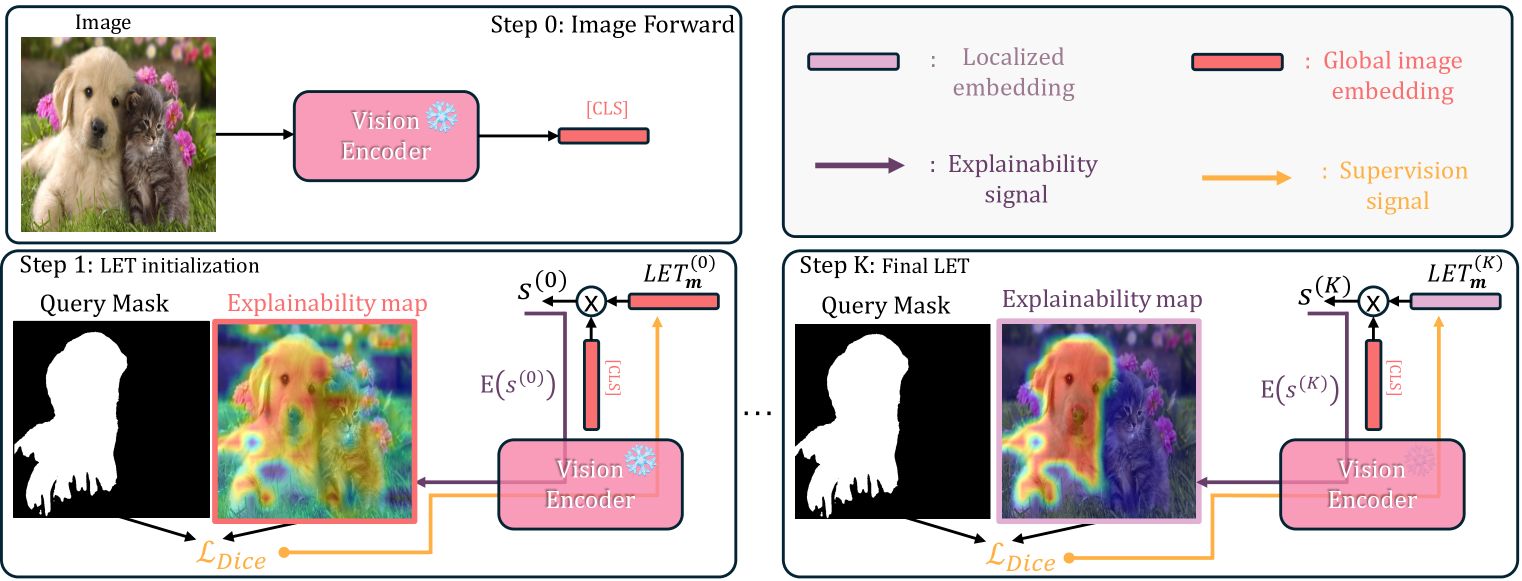
核心思路:MaskInversion的核心思路是通过优化一个可学习的嵌入向量,使其对应的可解释性图谱尽可能地与给定的区域掩码对齐。通过这种方式,嵌入向量能够捕捉到该区域的上下文信息,从而生成更具判别性的局部区域表示。这种方法利用了预训练模型的知识,同时针对特定区域进行优化。
技术框架:MaskInversion的整体流程如下:1) 初始化一个可学习的嵌入token。2) 使用预训练的视觉-语言模型(如CLIP)计算该嵌入token的可解释性图谱。3) 计算可解释性图谱与目标区域掩码之间的差异。4) 通过梯度下降优化嵌入token,使其可解释性图谱更接近目标掩码。5) 重复步骤2-4,直到收敛。在这个过程中,预训练模型保持冻结,只更新嵌入token。
关键创新:MaskInversion的关键创新在于利用可解释性图谱作为桥梁,将嵌入向量与目标区域联系起来。通过优化可解释性图谱,嵌入向量能够捕捉到目标区域的上下文信息,从而生成更具判别性的局部区域表示。此外,论文还提出了一种梯度分解策略,以降低计算可解释性图谱的成本。
关键设计:MaskInversion的关键设计包括:1) 使用梯度下降优化嵌入token。2) 使用预训练模型的梯度计算可解释性图谱。3) 设计损失函数来衡量可解释性图谱与目标掩码之间的差异。具体而言,损失函数通常采用L1或L2损失。为了降低计算成本,论文提出了一种梯度分解策略,将梯度计算分解为多个步骤,从而减少了计算量。
🖼️ 关键图片
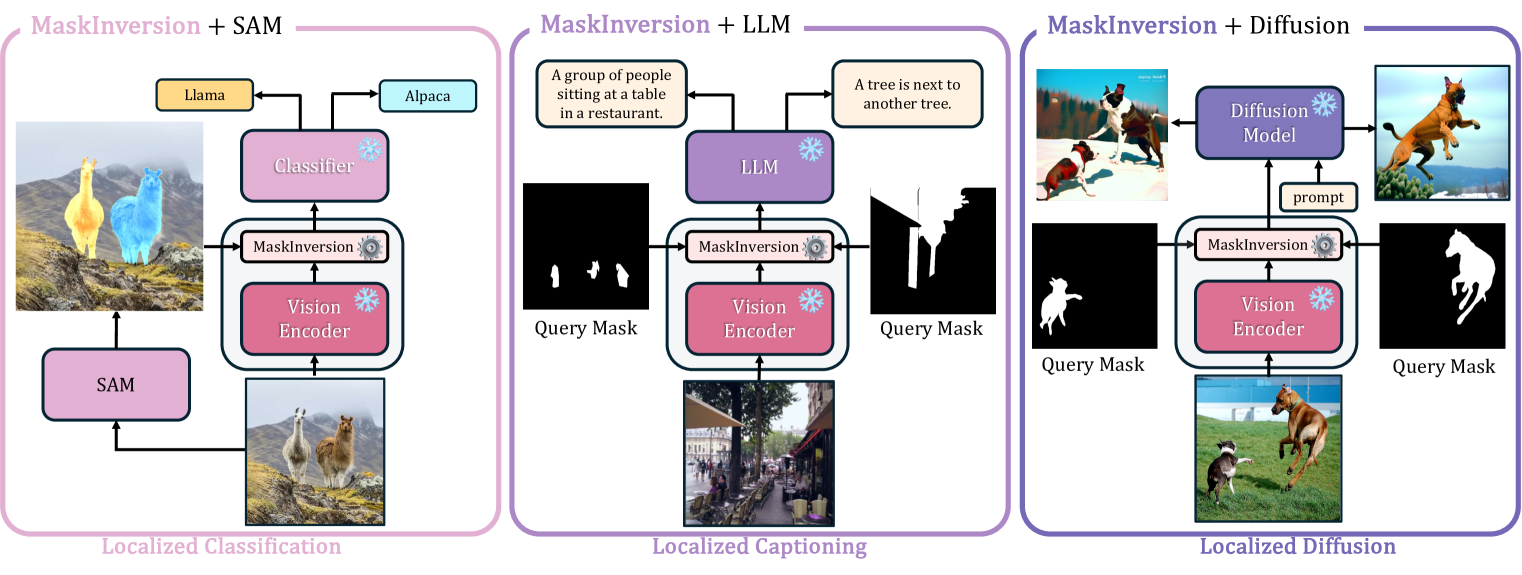

📊 实验亮点
MaskInversion在多个数据集上进行了评估,包括PascalVOC、MSCOCO、RefCOCO和OpenImagesV7。实验结果表明,该方法在开放词汇类别检索、指代表达式理解等任务上显著优于现有方法。例如,在RefCOCO数据集上,MaskInversion在指代表达式理解任务上取得了SOTA结果,相较于之前的最佳方法有显著提升。
🎯 应用场景
MaskInversion具有广泛的应用前景,包括但不限于:细粒度图像检索、视觉问答、机器人导航、图像编辑和生成等。通过提供更精确的局部区域表示,该方法可以提升这些应用在复杂场景下的性能,并为未来的视觉-语言研究提供新的思路。
📄 摘要(原文)
Vision-language foundation models such as CLIP have achieved tremendous results in global vision-language alignment, but still show some limitations in creating representations for specific image regions. % To address this problem, we propose MaskInversion, a method that leverages the feature representations of pre-trained foundation models, such as CLIP, to generate a context-aware embedding for a query image region specified by a mask at test time. MaskInversion starts with initializing an embedding token and compares its explainability map, derived from the foundation model, to the query mask. The embedding token is then subsequently refined to approximate the query region by minimizing the discrepancy between its explainability map and the query mask. During this process, only the embedding vector is updated, while the underlying foundation model is kept frozen allowing to use MaskInversion with any pre-trained model. As deriving the explainability map involves computing its gradient, which can be expensive, we propose a gradient decomposition strategy that simplifies this computation. The learned region representation can be used for a broad range of tasks, including open-vocabulary class retrieval, referring expression comprehension, as well as for localized captioning and image generation. We evaluate the proposed method on all those tasks on several datasets such as PascalVOC, MSCOCO, RefCOCO, and OpenImagesV7 and show its capabilities compared to other SOTA approaches.