Adversarial Robustness in RGB-Skeleton Action Recognition: Leveraging Attention Modality Reweighter
作者: Chao Liu, Xin Liu, Zitong Yu, Yonghong Hou, Huanjing Yue, Jingyu Yang
分类: cs.CV
发布日期: 2024-07-29
备注: Accepted by IJCB 2024
💡 一句话要点
提出基于注意力机制的模态重加权方法AMR,提升RGB-骨骼动作识别模型的对抗鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 动作识别 对抗鲁棒性 多模态学习 注意力机制 模态重加权
📋 核心要点
- 现有动作识别模型易受对抗攻击影响,在安全攸关场景存在风险,但针对RGB-骨骼多模态动作识别对抗鲁棒性的研究较少。
- 论文提出注意力模态重加权器(AMR),通过注意力机制动态调整RGB和骨骼模态的权重,使模型关注更鲁棒的特征。
- 实验表明,AMR能显著提升模型对抗鲁棒性,例如在NTU-RGB+D 60数据集上,对PGD20攻击的抵抗能力提升了43.77%。
📝 摘要(中文)
深度神经网络在计算机视觉任务中取得了显著进展。然而,当DNN预测对抗样本时,即在自然样本中加入人眼无法察觉的对抗噪声时,会发生错误分类。这限制了DNN在安全关键领域的应用。为了增强模型的鲁棒性,以往的研究主要集中在单模态领域,如图像识别和视频理解。尽管多模态学习在动作识别等任务中取得了先进的性能,但对RGB-骨骼动作识别模型的鲁棒性研究仍然匮乏。本文系统地研究了如何提高RGB-骨骼动作识别模型的鲁棒性。我们首先对不同模态的鲁棒性进行了实证分析,观察到骨骼模态比RGB模态更鲁棒。受此启发,我们提出了基于注意力的模态重加权器(AMR),它利用注意力层对两种模态进行重加权,使模型能够学习更鲁棒的特征。我们的AMR是即插即用的,可以很容易地与多模态模型集成。为了证明AMR的有效性,我们在各种数据集上进行了广泛的实验。例如,与SOTA方法相比,AMR在NTU-RGB+D 60数据集上对PGD20攻击的抵抗能力提高了43.77%。此外,它有效地平衡了不同模态之间鲁棒性的差异。
🔬 方法详解
问题定义:现有深度神经网络在动作识别任务中表现出色,但容易受到对抗攻击的影响,即通过在输入中添加微小的、人眼难以察觉的扰动,导致模型产生错误的预测。尤其是在RGB-骨骼多模态动作识别中,RGB模态更容易受到攻击,而骨骼模态相对更鲁棒。现有方法缺乏对不同模态鲁棒性差异的有效利用,导致整体模型鲁棒性不足。
核心思路:论文的核心思路是利用注意力机制,动态地对RGB和骨骼模态进行重加权。通过学习不同模态的重要性,使模型更加关注鲁棒性更强的骨骼模态,从而提高整体模型的对抗鲁棒性。这种方法旨在平衡不同模态之间的鲁棒性差异,避免模型过度依赖易受攻击的RGB模态。
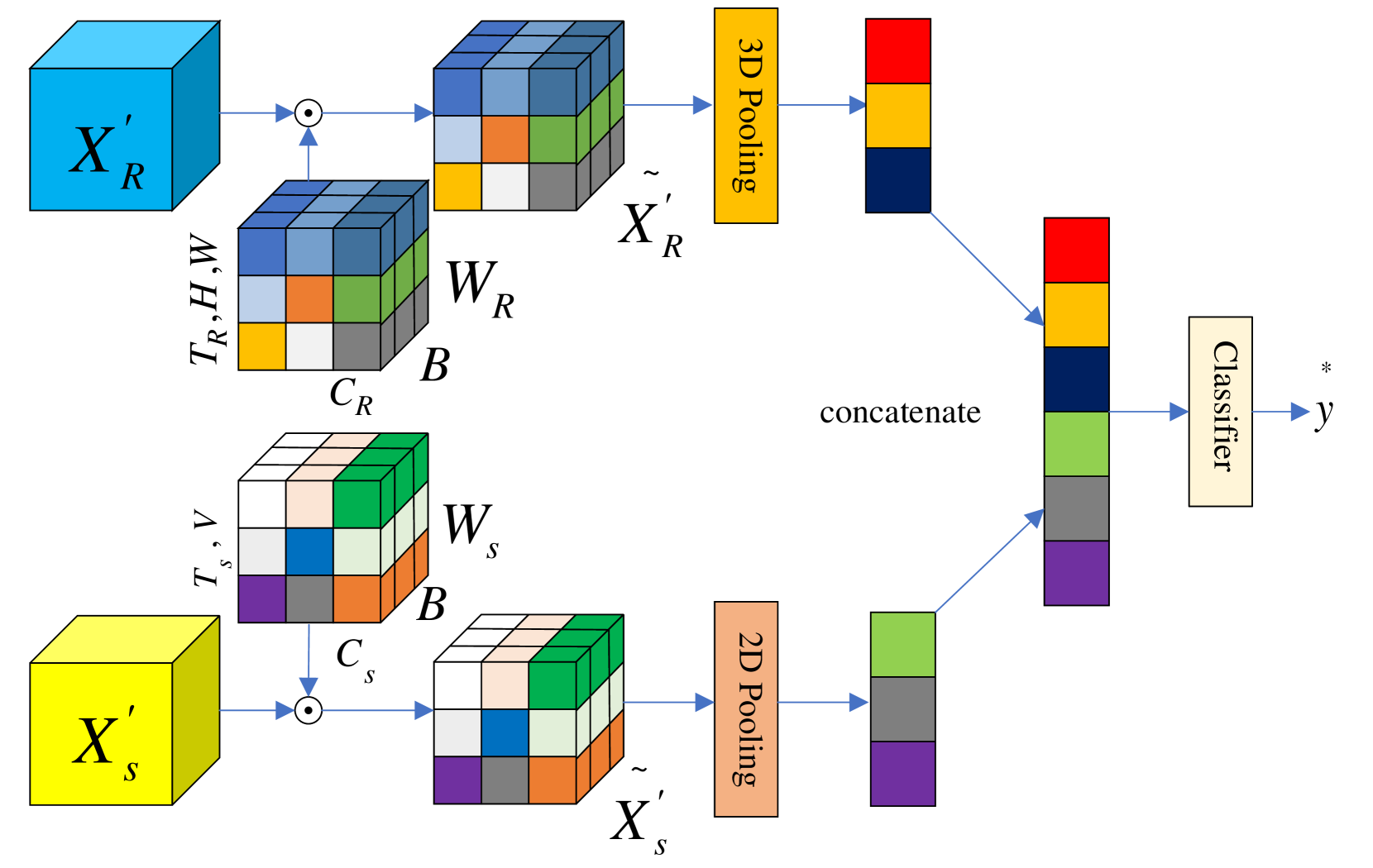
技术框架:整体框架包括以下几个主要步骤:1) 从RGB和骨骼数据中提取特征;2) 将提取的特征输入到注意力模态重加权器(AMR)中;3) AMR根据输入特征计算每个模态的权重;4) 使用计算出的权重对RGB和骨骼特征进行加权融合;5) 将融合后的特征输入到分类器中进行动作识别。
关键创新:最重要的技术创新点在于提出了注意力模态重加权器(AMR)。与传统的模态融合方法不同,AMR不是简单地将不同模态的特征进行拼接或相加,而是通过注意力机制动态地学习每个模态的重要性,并根据其鲁棒性进行加权。这种方法能够更好地利用不同模态的优势,提高模型的整体鲁棒性。
关键设计:AMR的关键设计包括:1) 使用注意力层来学习每个模态的权重。注意力层的输入是RGB和骨骼特征,输出是每个模态的权重。2) 使用sigmoid函数将注意力层的输出归一化到0到1之间,表示每个模态的重要性。3) 使用计算出的权重对RGB和骨骼特征进行加权融合。4) 损失函数采用交叉熵损失函数,用于训练模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的AMR方法能够显著提高RGB-骨骼动作识别模型的对抗鲁棒性。在NTU-RGB+D 60数据集上,与SOTA方法相比,AMR对PGD20攻击的抵抗能力提高了43.77%。此外,实验还证明AMR能够有效地平衡不同模态之间的鲁棒性差异,使模型更加关注鲁棒性更强的骨骼模态。
🎯 应用场景
该研究成果可应用于安全监控、人机交互、智能家居等领域。通过提高动作识别模型的对抗鲁棒性,可以有效防止恶意攻击,确保系统在复杂环境下的稳定性和可靠性。例如,在安全监控中,可以防止攻击者通过对抗样本干扰监控系统,从而保障公共安全。
📄 摘要(原文)
Deep neural networks (DNNs) have been applied in many computer vision tasks and achieved state-of-the-art (SOTA) performance. However, misclassification will occur when DNNs predict adversarial examples which are created by adding human-imperceptible adversarial noise to natural examples. This limits the application of DNN in security-critical fields. In order to enhance the robustness of models, previous research has primarily focused on the unimodal domain, such as image recognition and video understanding. Although multi-modal learning has achieved advanced performance in various tasks, such as action recognition, research on the robustness of RGB-skeleton action recognition models is scarce. In this paper, we systematically investigate how to improve the robustness of RGB-skeleton action recognition models. We initially conducted empirical analysis on the robustness of different modalities and observed that the skeleton modality is more robust than the RGB modality. Motivated by this observation, we propose the \formatword{A}ttention-based \formatword{M}odality \formatword{R}eweighter (\formatword{AMR}), which utilizes an attention layer to re-weight the two modalities, enabling the model to learn more robust features. Our AMR is plug-and-play, allowing easy integration with multimodal models. To demonstrate the effectiveness of AMR, we conducted extensive experiments on various datasets. For example, compared to the SOTA methods, AMR exhibits a 43.77\% improvement against PGD20 attacks on the NTU-RGB+D 60 dataset. Furthermore, it effectively balances the differences in robustness between different modalities.