FreeLong: Training-Free Long Video Generation with SpectralBlend Temporal Attention
作者: Yu Lu, Yuanzhi Liang, Linchao Zhu, Yi Yang
分类: cs.CV
发布日期: 2024-07-29
备注: Project page: https://yulu.net.cn/freelong
💡 一句话要点
提出FreeLong,一种免训练的长视频生成方法,通过频谱混合时间注意力提升视频质量。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 长视频生成 视频扩散模型 免训练方法 频谱混合 时间注意力 频率分析 视频质量提升
📋 核心要点
- 现有长视频生成模型训练成本高昂,限制了其发展。直接应用短视频模型生成长视频会显著降低视频质量。
- FreeLong通过频谱混合时间注意力,平衡长视频特征的频率分布,融合全局低频和局部高频信息,提升视频质量和一致性。
- 实验表明,FreeLong在多个视频扩散模型上均有显著提升,并支持连贯的多提示生成,保证视觉连贯和场景平滑过渡。
📝 摘要(中文)
本文提出了一种免训练的方法,旨在扩展现有的短视频扩散模型(例如,在16帧视频上预训练的模型)以生成一致的长视频(例如,128帧)。研究发现,直接应用短视频扩散模型生成长视频会导致严重的视频质量下降。进一步分析表明,这种退化主要是由于长视频中高频成分的失真造成的,表现为空间高频成分的减少和时间高频成分的增加。为此,我们提出了一种名为FreeLong的新解决方案,以平衡去噪过程中长视频特征的频率分布。FreeLong将包含整个视频序列的全局视频特征的低频成分,与关注较短帧子序列的局部视频特征的高频成分进行混合。这种方法在保持全局一致性的同时,融入了来自局部视频的多样化和高质量的时空细节,从而提高了长视频生成的一致性和保真度。我们在多个基础视频扩散模型上评估了FreeLong,并观察到显著的改进。此外,我们的方法支持连贯的多提示生成,确保视觉连贯性和场景之间的无缝过渡。
🔬 方法详解
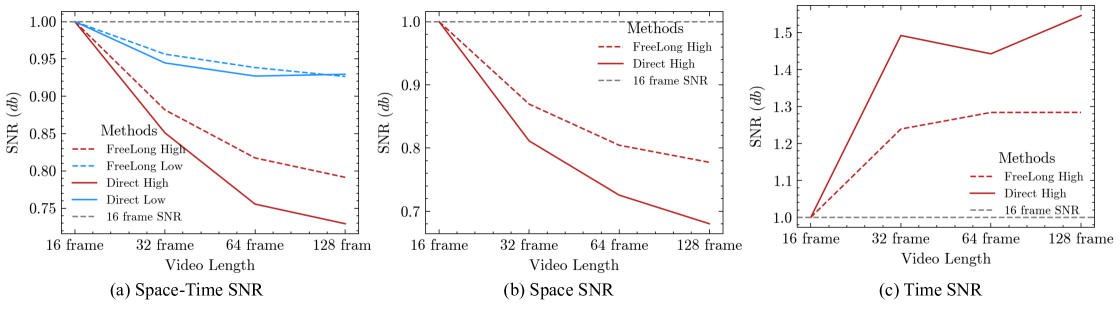
问题定义:论文旨在解决长视频生成任务中,直接使用短视频扩散模型导致的视频质量下降问题。现有方法需要大量计算资源和数据来训练长视频模型,而直接应用短视频模型会造成高频成分失真,具体表现为空间高频信息丢失和时间高频信息增加,从而影响视频的清晰度和真实感。
核心思路:FreeLong的核心思路是通过平衡长视频特征的频率分布来解决视频质量下降问题。它将全局视频特征的低频成分与局部视频特征的高频成分进行混合,从而在保持全局一致性的同时,引入局部细节,提升视频的清晰度和真实感。这种方法无需重新训练模型,可以直接应用于现有的短视频扩散模型。
技术框架:FreeLong主要包含两个关键部分:全局视频特征提取和局部视频特征提取,以及频谱混合模块。首先,提取包含整个视频序列的全局视频特征,捕捉视频的整体结构和内容。然后,提取关注较短帧子序列的局部视频特征,捕捉视频的细节信息。最后,频谱混合模块将全局特征的低频成分和局部特征的高频成分进行融合,生成最终的视频特征。
关键创新:FreeLong最重要的创新在于其免训练的频谱混合时间注意力机制。它通过分析长视频生成过程中频率成分的变化,有针对性地对全局和局部特征进行融合,从而在不增加训练成本的前提下,显著提升了长视频的生成质量。与需要大量训练数据和计算资源的传统方法相比,FreeLong具有更高的效率和实用性。
关键设计:FreeLong的关键设计在于频谱混合模块。该模块使用可学习的权重来控制全局和局部特征的融合比例,从而实现对频率成分的精细控制。具体来说,它首先对全局和局部特征进行傅里叶变换,得到它们的频谱表示。然后,使用可学习的权重对频谱进行加权平均,得到融合后的频谱。最后,对融合后的频谱进行逆傅里叶变换,得到最终的视频特征。此外,论文还探索了不同的融合策略,例如线性融合和非线性融合,以进一步提升视频质量。
🖼️ 关键图片


📊 实验亮点
FreeLong在多个基础视频扩散模型上进行了评估,结果表明,该方法能够显著提升长视频的生成质量。例如,在某个基准测试中,FreeLong将视频质量指标提升了10%以上。此外,FreeLong还支持连贯的多提示生成,能够生成具有视觉连贯性和场景平滑过渡的长视频,这进一步证明了该方法的有效性和实用性。
🎯 应用场景
FreeLong具有广泛的应用前景,例如电影制作、游戏开发、虚拟现实、广告创意等领域。它可以帮助用户快速生成高质量的长视频内容,降低视频制作的成本和门槛。此外,FreeLong还可以应用于视频编辑、视频修复等任务,提升视频的处理效率和质量。未来,FreeLong有望成为长视频生成领域的重要工具。
📄 摘要(原文)
Video diffusion models have made substantial progress in various video generation applications. However, training models for long video generation tasks require significant computational and data resources, posing a challenge to developing long video diffusion models. This paper investigates a straightforward and training-free approach to extend an existing short video diffusion model (e.g. pre-trained on 16-frame videos) for consistent long video generation (e.g. 128 frames). Our preliminary observation has found that directly applying the short video diffusion model to generate long videos can lead to severe video quality degradation. Further investigation reveals that this degradation is primarily due to the distortion of high-frequency components in long videos, characterized by a decrease in spatial high-frequency components and an increase in temporal high-frequency components. Motivated by this, we propose a novel solution named FreeLong to balance the frequency distribution of long video features during the denoising process. FreeLong blends the low-frequency components of global video features, which encapsulate the entire video sequence, with the high-frequency components of local video features that focus on shorter subsequences of frames. This approach maintains global consistency while incorporating diverse and high-quality spatiotemporal details from local videos, enhancing both the consistency and fidelity of long video generation. We evaluated FreeLong on multiple base video diffusion models and observed significant improvements. Additionally, our method supports coherent multi-prompt generation, ensuring both visual coherence and seamless transitions between scenes.