Twins-PainViT: Towards a Modality-Agnostic Vision Transformer Framework for Multimodal Automatic Pain Assessment using Facial Videos and fNIRS
作者: Stefanos Gkikas, Manolis Tsiknakis
分类: cs.CV, cs.AI
发布日期: 2024-07-29
期刊: 2024 International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW)
DOI: 10.1109/ACIIW63320.2024.00007
💡 一句话要点
Twins-PainViT:面向面部视频和fNIRS的多模态疼痛自动评估的模态无关Vision Transformer框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 疼痛评估 多模态融合 Vision Transformer 面部视频 fNIRS 模态无关 深度学习
📋 核心要点
- 现有疼痛评估方法依赖于特定领域知识,缺乏通用性,限制了其在不同模态数据上的应用。
- 提出一种模态无关的框架,采用双Vision Transformer (ViT) 结构,能够处理面部视频和fNIRS数据。
- 实验结果表明,该方法在多级疼痛评估任务中取得了46.76%的准确率,验证了其有效性。
📝 摘要(中文)
本研究旨在解决自动疼痛评估问题,该问题对于提升医疗水平和优化疼痛管理策略至关重要。该研究已提交给下一代疼痛评估多模态感知挑战赛(AI4PAIN)。提出的多模态框架利用面部视频和fNIRS数据,并提出了一种模态无关的方法,从而减轻了对特定领域模型的需求。该方法采用双ViT配置,并将fNIRS以及从两种模态中提取的嵌入表示为波形,证明了所提出方法的有效性,在多级疼痛评估任务中实现了46.76%的准确率。
🔬 方法详解
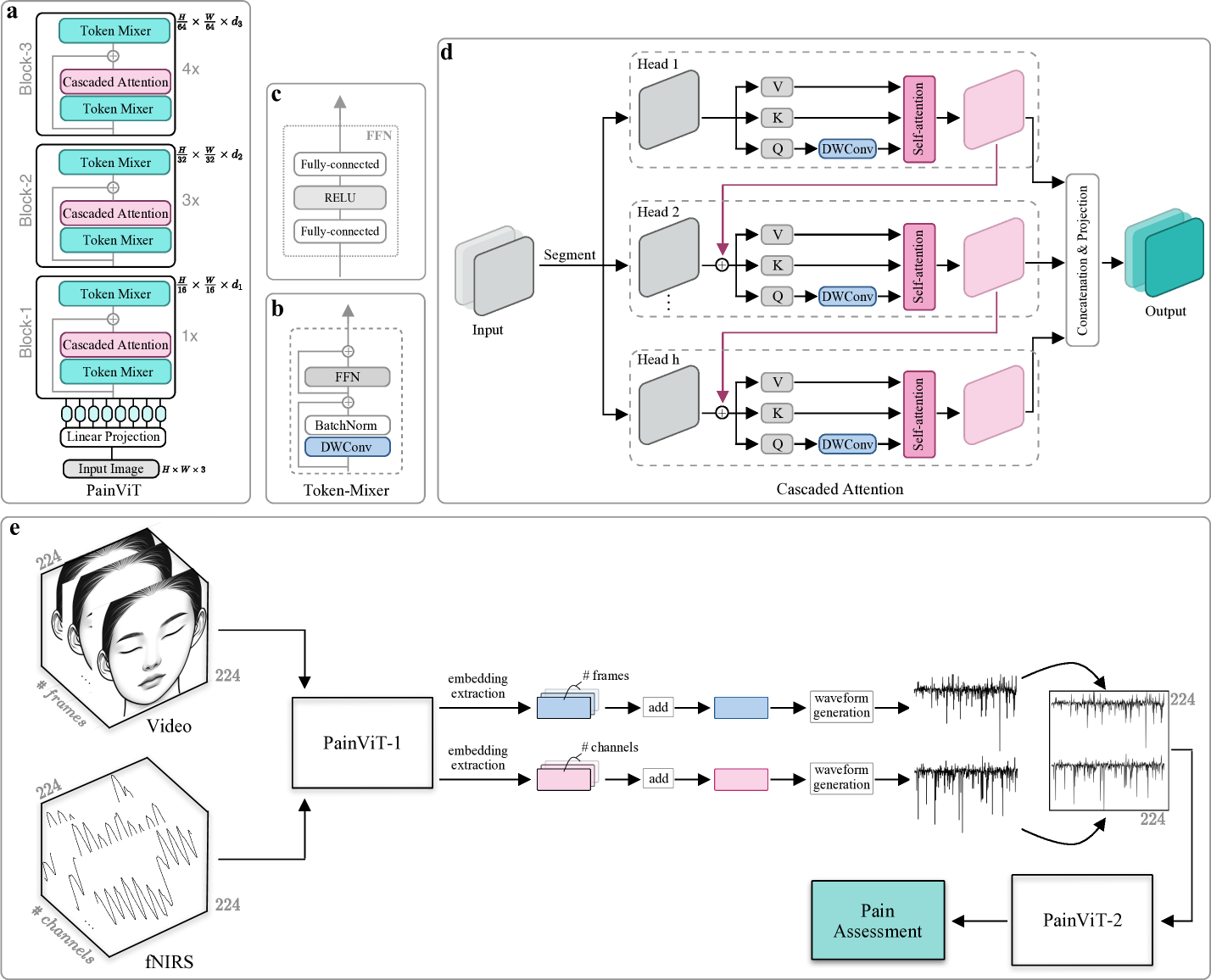
问题定义:论文旨在解决多模态自动疼痛评估问题,具体而言,是利用面部视频和fNIRS数据来判断疼痛等级。现有方法通常针对特定模态设计模型,缺乏通用性,难以有效融合不同模态的信息。此外,如何有效地表示和处理fNIRS信号也是一个挑战。
核心思路:论文的核心思路是提出一种模态无关的框架,即Twins-PainViT,该框架能够同时处理面部视频和fNIRS数据,并学习到它们之间的关联。通过将不同模态的数据都表示为波形,并使用Vision Transformer (ViT) 进行特征提取和融合,从而实现模态无关性。这样设计的目的是为了避免针对特定模态设计复杂的预处理或特征提取步骤,提高模型的泛化能力。
技术框架:整体框架包含两个并行的ViT分支,分别处理面部视频和fNIRS数据。首先,将面部视频提取的嵌入和fNIRS信号都表示为波形。然后,两个ViT分支分别对这些波形进行特征提取。最后,将两个分支提取的特征进行融合,并输入到分类器中进行疼痛等级的预测。
关键创新:最重要的技术创新点在于提出了模态无关的框架,通过将不同模态的数据都表示为波形,并使用ViT进行特征提取和融合,从而避免了针对特定模态设计复杂的预处理或特征提取步骤。这种方法可以更容易地扩展到其他模态的数据上。
关键设计:论文采用了双ViT结构,每个ViT分支都包含多个Transformer层。fNIRS信号被表示为波形,并直接输入到ViT中进行处理。面部视频首先通过预训练的模型提取嵌入,然后将嵌入表示为波形,再输入到ViT中。损失函数采用交叉熵损失函数,用于多级疼痛等级的分类。
🖼️ 关键图片


📊 实验亮点
该研究提出的Twins-PainViT框架在多级疼痛评估任务中取得了46.76%的准确率。虽然绝对数值不高,但考虑到这是一个多模态融合的复杂任务,且该方法具有模态无关性,因此具有一定的潜力。该研究为多模态疼痛评估提供了一种新的思路,并验证了ViT在处理生理信号方面的有效性。
🎯 应用场景
该研究成果可应用于临床疼痛评估、术后疼痛管理、慢性疼痛监测等领域。通过自动分析患者的面部表情和生理信号,可以客观、准确地评估疼痛程度,辅助医生制定个性化的治疗方案,提高患者的生活质量。未来,该技术有望集成到智能医疗设备中,实现远程疼痛监测和管理。
📄 摘要(原文)
Automatic pain assessment plays a critical role for advancing healthcare and optimizing pain management strategies. This study has been submitted to the First Multimodal Sensing Grand Challenge for Next-Gen Pain Assessment (AI4PAIN). The proposed multimodal framework utilizes facial videos and fNIRS and presents a modality-agnostic approach, alleviating the need for domain-specific models. Employing a dual ViT configuration and adopting waveform representations for the fNIRS, as well as for the extracted embeddings from the two modalities, demonstrate the efficacy of the proposed method, achieving an accuracy of 46.76% in the multilevel pain assessment task.