ClickDiff: Click to Induce Semantic Contact Map for Controllable Grasp Generation with Diffusion Models
作者: Peiming Li, Ziyi Wang, Mengyuan Liu, Hong Liu, Chen Chen
分类: cs.CV
发布日期: 2024-07-28
备注: ACM Multimedia 2024
🔗 代码/项目: GITHUB
💡 一句话要点
ClickDiff:通过点击诱导语义接触图,实现扩散模型的可控抓取生成
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 抓取生成 扩散模型 语义接触图 可控生成 人机交互
📋 核心要点
- 现有抓取生成方法忽略了手与物体之间的细粒度接触信息,导致生成的抓取不准确且不理想。
- ClickDiff通过引入语义接触图(SCM)作为条件,实现对抓取生成的精确控制,提升交互的真实性。
- 在GRAB和ARCTIC数据集上的实验表明,ClickDiff在单手和双手抓取生成任务中都表现出有效性和鲁棒性。
📝 摘要(中文)
抓取生成旨在创建具有特定物体的复杂手-物交互。传统方法主要关注场景约束下的可见性和多样性,但往往忽略了细粒度的手-物交互,如接触,导致不准确和不理想的抓取。为了解决这些挑战,我们提出了一个可控的抓取生成任务,并引入了ClickDiff,一个可控的条件生成模型,它利用了细粒度的语义接触图(SCM)。特别是在合成交互式抓取时,该方法能够通过用户指定的或算法预测的语义接触图来精确控制抓取合成。具体来说,为了优化利用接触监督约束并准确建模手的复杂物理结构,我们提出了一个双重生成框架。在该框架内,语义条件模块基于细粒度的接触信息生成合理的接触图,而接触条件模块利用接触图以及物体点云来生成逼真的抓取。我们评估了适用于可控抓取生成的评估标准。在GRAB和ARCTIC数据集上的单手和双手生成实验验证了我们提出的方法的有效性,证明了ClickDiff的有效性和鲁棒性,即使对于以前未见过的物体也是如此。我们的代码可在https://github.com/adventurer-w/ClickDiff 获得。
🔬 方法详解
问题定义:现有抓取生成方法主要关注手的可见性和多样性,忽略了手与物体之间的细粒度接触信息,导致生成的抓取不准确,缺乏真实感。因此,需要一种能够精确控制手与物体接触的抓取生成方法。
核心思路:论文的核心思路是利用语义接触图(Semantic Contact Map, SCM)作为条件,引导抓取生成过程。通过SCM,用户或算法可以指定手与物体之间的接触位置和类型,从而实现对抓取姿态的精确控制。这种方法能够更好地模拟真实的人手抓取行为,生成更自然、更合理的抓取姿态。
技术框架:ClickDiff采用双重生成框架,包含两个主要模块:语义条件模块(Semantic Conditional Module)和接触条件模块(Contact Conditional Module)。首先,语义条件模块基于细粒度的接触信息生成合理的语义接触图。然后,接触条件模块利用生成的语义接触图以及物体点云,生成逼真的抓取姿态。整个框架通过扩散模型实现,能够生成高质量的抓取结果。
关键创新:该论文的关键创新在于引入了语义接触图(SCM)作为可控抓取生成的条件。与传统的基于可见性和多样性的方法相比,SCM能够提供更细粒度的手-物交互信息,从而实现对抓取姿态的精确控制。此外,双重生成框架的设计能够更好地利用接触监督约束,并准确建模手的复杂物理结构。
关键设计:语义条件模块和接触条件模块均采用扩散模型。语义条件模块的输入是细粒度的接触信息,输出是语义接触图。接触条件模块的输入是语义接触图和物体点云,输出是抓取姿态。损失函数包括接触损失和姿态损失,用于约束生成的语义接触图和抓取姿态的合理性。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片
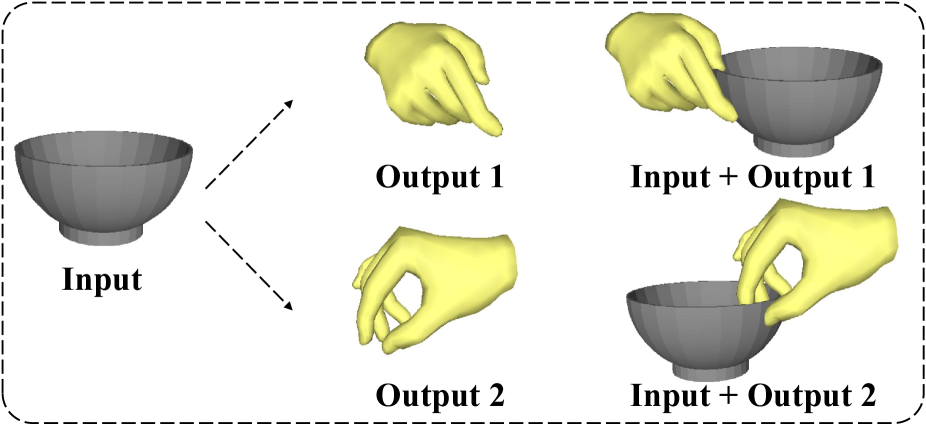


📊 实验亮点
实验结果表明,ClickDiff在GRAB和ARCTIC数据集上取得了显著的性能提升。与现有方法相比,ClickDiff能够生成更准确、更真实的抓取姿态,尤其是在处理未见过的物体时,仍然表现出良好的鲁棒性。实验结果验证了语义接触图作为可控抓取生成条件的有效性。
🎯 应用场景
ClickDiff在机器人抓取、虚拟现实、人机交互等领域具有广泛的应用前景。例如,在机器人抓取中,可以利用ClickDiff生成各种复杂的抓取姿态,提高机器人的操作能力。在虚拟现实中,可以利用ClickDiff生成逼真的手部动画,增强用户的沉浸感。在人机交互中,可以利用ClickDiff实现更自然、更直观的人机交互方式。
📄 摘要(原文)
Grasp generation aims to create complex hand-object interactions with a specified object. While traditional approaches for hand generation have primarily focused on visibility and diversity under scene constraints, they tend to overlook the fine-grained hand-object interactions such as contacts, resulting in inaccurate and undesired grasps. To address these challenges, we propose a controllable grasp generation task and introduce ClickDiff, a controllable conditional generation model that leverages a fine-grained Semantic Contact Map (SCM). Particularly when synthesizing interactive grasps, the method enables the precise control of grasp synthesis through either user-specified or algorithmically predicted Semantic Contact Map. Specifically, to optimally utilize contact supervision constraints and to accurately model the complex physical structure of hands, we propose a Dual Generation Framework. Within this framework, the Semantic Conditional Module generates reasonable contact maps based on fine-grained contact information, while the Contact Conditional Module utilizes contact maps alongside object point clouds to generate realistic grasps. We evaluate the evaluation criteria applicable to controllable grasp generation. Both unimanual and bimanual generation experiments on GRAB and ARCTIC datasets verify the validity of our proposed method, demonstrating the efficacy and robustness of ClickDiff, even with previously unseen objects. Our code is available at https://github.com/adventurer-w/ClickDiff.