Graph-based Unsupervised Disentangled Representation Learning via Multimodal Large Language Models
作者: Baao Xie, Qiuyu Chen, Yunnan Wang, Zequn Zhang, Xin Jin, Wenjun Zeng
分类: cs.CV, cs.LG
发布日期: 2024-07-26
备注: 9 pages, 7 figures
💡 一句话要点
提出基于图和多模态大语言模型的无监督解耦表示学习框架,解决语义因子间相关性问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 解耦表示学习 无监督学习 多模态大语言模型 图神经网络 因子分解 表示学习 β-VAE
📋 核心要点
- 现有解耦表示学习方法假设语义因子相互独立,忽略了现实中因子间的相关性,限制了模型的性能。
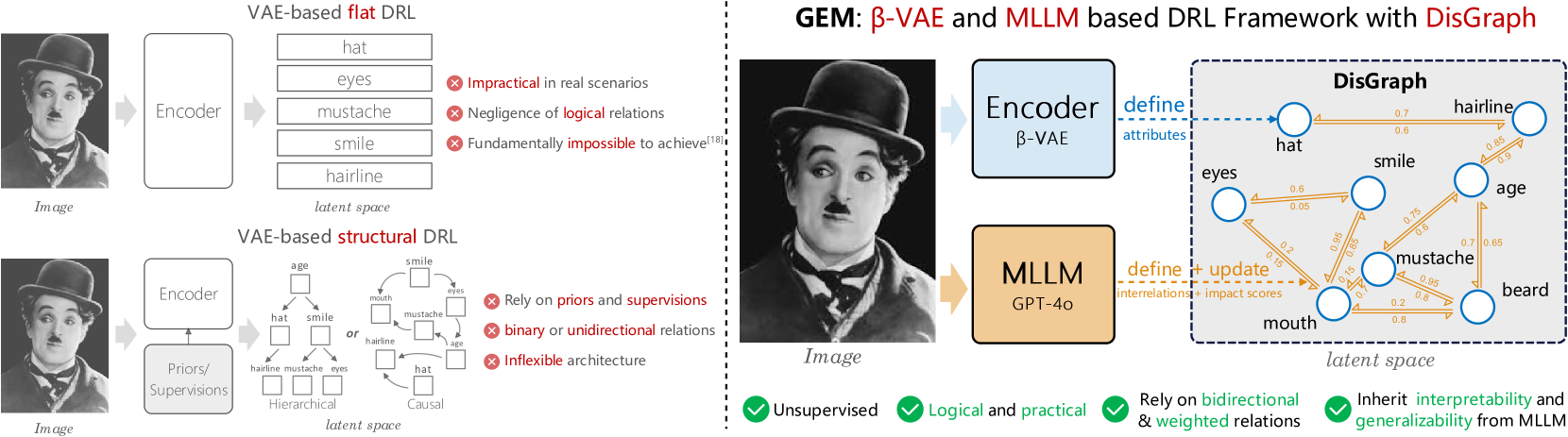
- 提出一种基于双向加权图的框架,利用β-VAE提取因子,并借助多模态大语言模型发现和排序因子间的潜在相关性。
- 实验结果表明,该方法在解耦和重建方面表现优异,并继承了多模态大语言模型的可解释性和泛化能力。
📝 摘要(中文)
解耦表示学习(DRL)旨在识别和分解观测数据背后的潜在因素,从而促进数据感知和生成。然而,现有的DRL方法通常依赖于语义因子在统计上相互独立的非现实假设。实际上,这些因子可能表现出相关性,而现成的解决方案尚未能正确解决这一问题。为了应对这一挑战,我们引入了一个基于双向加权图的框架,以学习复杂数据中分解的属性及其相互关系。具体来说,我们提出了一个基于$β$-VAE的模块来提取因子作为图的初始节点,并利用多模态大语言模型(MLLM)来发现和排序潜在的相关性,从而更新加权边。通过整合这些互补模块,我们的模型成功实现了细粒度、实用和无监督的解耦。实验证明了我们的方法在解耦和重建方面的优越性能。此外,该模型继承了MLLM的增强可解释性和泛化能力。
🔬 方法详解
问题定义:现有的解耦表示学习方法通常假设潜在的语义因子是相互独立的,这与现实世界的数据分布不符。真实数据中,各个因子之间往往存在复杂的关联关系。忽略这些关联关系会导致学习到的表示不够准确,影响下游任务的性能。因此,如何有效地建模和利用因子之间的相关性是当前解耦表示学习面临的一个重要挑战。
核心思路:该论文的核心思路是利用图结构来显式地建模潜在因子之间的关系。首先,使用β-VAE提取潜在因子作为图的节点。然后,利用多模态大语言模型(MLLM)来发现这些因子之间的相关性,并将这些相关性作为图的边,边的权重表示相关性的强度。通过这种方式,模型可以学习到因子之间的复杂关系,从而更好地进行解耦表示学习。
技术框架:该模型主要包含两个模块:基于β-VAE的因子提取模块和基于MLLM的相关性发现模块。首先,β-VAE模块负责从输入数据中提取潜在因子,这些因子作为图的节点。然后,MLLM模块负责分析这些因子之间的相关性,并根据相关性的大小设置图的边的权重。整个框架通过联合优化这两个模块,实现细粒度、实用和无监督的解耦。
关键创新:该论文的关键创新在于利用多模态大语言模型来发现潜在因子之间的相关性。与传统的基于统计的方法不同,MLLM可以利用其强大的语义理解能力,发现更复杂、更细粒度的相关性。此外,通过将因子之间的关系建模为图结构,模型可以更好地利用这些关系进行解耦表示学习。
关键设计:该模型使用β-VAE作为因子提取器,其中β是一个超参数,用于控制解耦的强度。MLLM模块使用预训练的多模态大语言模型,并通过微调来适应特定的任务。损失函数包括重建损失和解耦损失,其中解耦损失用于鼓励学习到的因子之间相互独立。图的边的权重根据MLLM输出的相关性得分进行设置。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在解耦和重建方面取得了显著的提升。与现有的解耦表示学习方法相比,该方法能够学习到更准确、更可解释的表示。具体来说,在多个数据集上,该方法在解耦指标(如Mutual Information Gap)上取得了明显的提升,同时保持了良好的重建性能。
🎯 应用场景
该研究成果可应用于图像生成、视频编辑、自然语言处理等领域。例如,在图像生成中,可以控制不同因子的变化来生成具有特定属性的图像。在视频编辑中,可以独立地编辑视频中的不同元素,如背景、人物等。此外,该方法还可以用于提高模型的可解释性和泛化能力,使其在更广泛的应用场景中发挥作用。
📄 摘要(原文)
Disentangled representation learning (DRL) aims to identify and decompose underlying factors behind observations, thus facilitating data perception and generation. However, current DRL approaches often rely on the unrealistic assumption that semantic factors are statistically independent. In reality, these factors may exhibit correlations, which off-the-shelf solutions have yet to properly address. To tackle this challenge, we introduce a bidirectional weighted graph-based framework, to learn factorized attributes and their interrelations within complex data. Specifically, we propose a $β$-VAE based module to extract factors as the initial nodes of the graph, and leverage the multimodal large language model (MLLM) to discover and rank latent correlations, thereby updating the weighted edges. By integrating these complementary modules, our model successfully achieves fine-grained, practical and unsupervised disentanglement. Experiments demonstrate our method's superior performance in disentanglement and reconstruction. Furthermore, the model inherits enhanced interpretability and generalizability from MLLMs.