RefMask3D: Language-Guided Transformer for 3D Referring Segmentation
作者: Shuting He, Henghui Ding
分类: cs.CV
发布日期: 2024-07-25
备注: ACM MM 2024, Code: https://github.com/heshuting555/RefMask3D
🔗 代码/项目: GITHUB
💡 一句话要点
RefMask3D:一种用于3D指代表达分割的语言引导Transformer网络
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D指代表达分割 视觉-语言融合 Transformer网络 点云处理 几何增强注意力
📋 核心要点
- 现有3D指代表达分割方法难以有效融合视觉和语言特征,尤其是在处理点云的稀疏性和不规则性时。
- RefMask3D通过几何增强的组-词注意力机制和语言基元构建方法,实现了更全面的多模态特征交互和理解。
- 实验结果表明,RefMask3D在多个3D和2D指代表达分割任务上取得了显著的性能提升,尤其在ScanRefer数据集上mIoU提升了3.16%。
📝 摘要(中文)
3D指代表达分割是一项新兴且具有挑战性的视觉-语言任务,旨在分割点云场景中由自然语言表达式描述的对象。这项任务背后的关键挑战是视觉-语言特征融合和对齐。本文提出了RefMask3D,旨在探索全面的多模态特征交互和理解。首先,我们提出了一种几何增强的组-词注意力机制,通过跨模态组-词注意力将语言与几何上连贯的子云集成,有效解决了点云的稀疏性和不规则性带来的挑战。然后,我们引入了一种语言基元构建方法,以产生代表不同语义属性的语义基元,从而极大地增强了解码阶段的视觉-语言理解。此外,我们引入了一个对象聚类模块,该模块分析语言基元之间的相互关系,以巩固它们的见解并查明共同特征,从而有助于捕获整体信息并提高目标识别的精度。所提出的RefMask3D在3D指代表达分割、3D视觉定位以及2D指代图像分割方面均实现了新的最先进的性能。特别是在具有挑战性的ScanRefer数据集上,RefMask3D的mIoU比以前的最先进方法高出3.16%。代码可在https://github.com/heshuting555/RefMask3D 获取。
🔬 方法详解
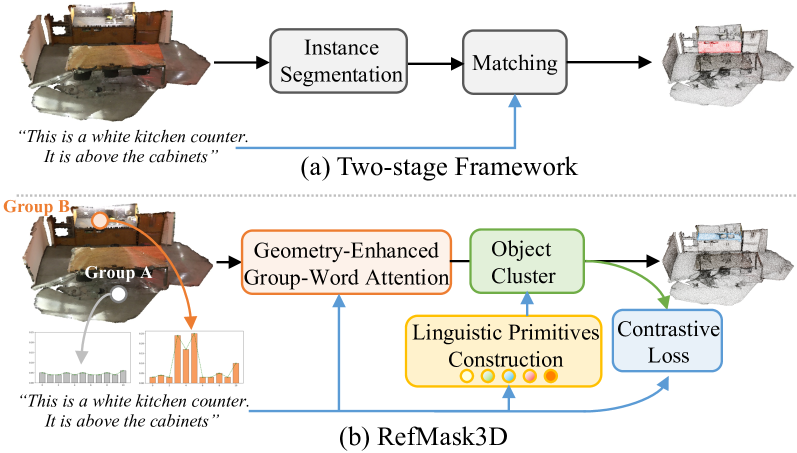
问题定义:3D指代表达分割旨在根据自然语言描述分割3D点云场景中的特定对象。现有方法在处理点云的稀疏性和不规则性,以及有效融合视觉和语言特征方面存在不足,导致分割精度不高。
核心思路:RefMask3D的核心思路是通过多模态特征交互和理解来提高分割精度。具体来说,它利用几何信息增强的组-词注意力机制来处理点云的稀疏性,并构建语言基元来增强视觉-语言理解。
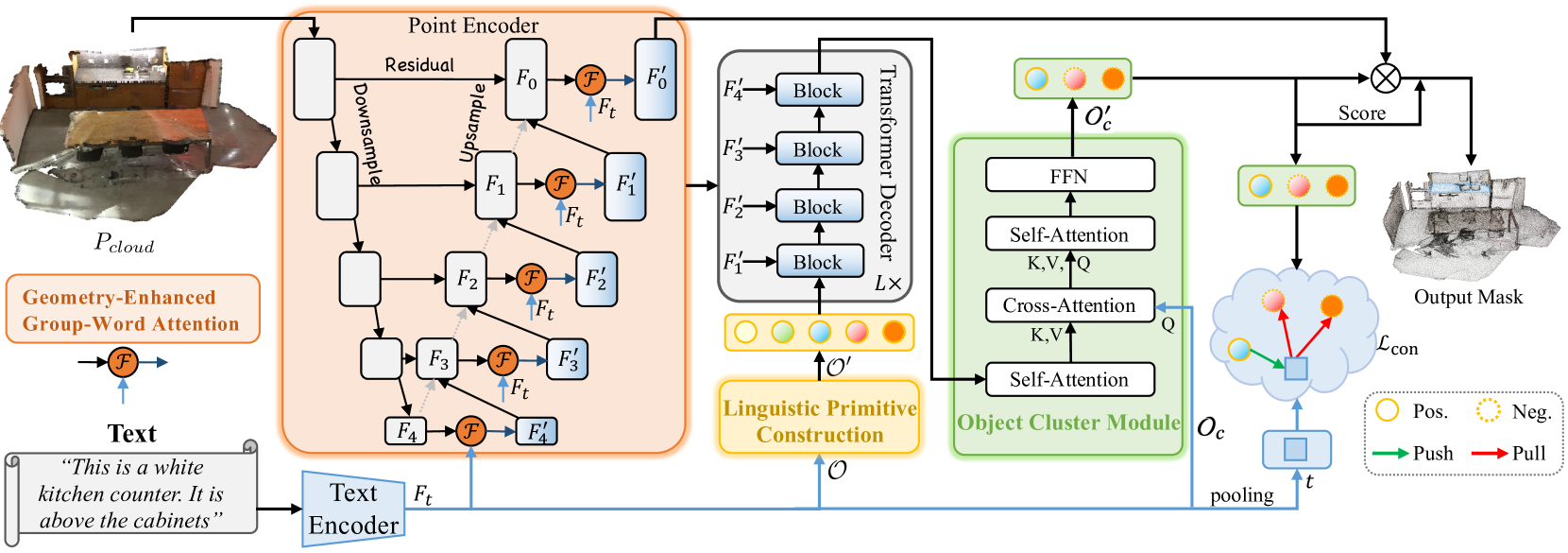
技术框架:RefMask3D的整体架构包括以下几个主要模块:1)几何增强的组-词注意力模块,用于融合视觉和语言特征;2)语言基元构建模块,用于提取语义信息;3)对象聚类模块,用于分析语言基元之间的关系;4)分割解码器,用于生成最终的分割结果。
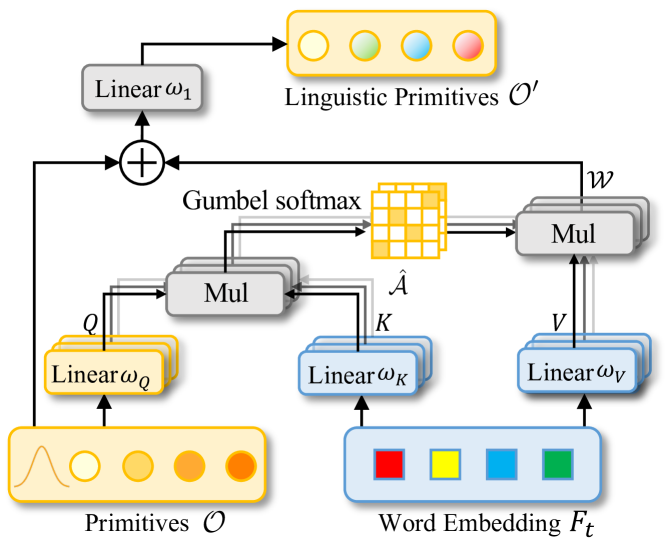
关键创新:RefMask3D的关键创新在于:1)提出了几何增强的组-词注意力机制,能够有效处理点云的稀疏性和不规则性;2)引入了语言基元构建方法,能够提取更丰富的语义信息,从而增强视觉-语言理解;3)设计了对象聚类模块,能够分析语言基元之间的关系,从而提高目标识别的精度。
关键设计:几何增强的组-词注意力机制利用几何信息对点云进行分组,然后通过注意力机制将语言特征与每个组的视觉特征进行融合。语言基元构建方法通过学习一组可学习的向量来表示不同的语义属性。对象聚类模块使用图神经网络来分析语言基元之间的关系。
🖼️ 关键图片
📊 实验亮点
RefMask3D在ScanRefer数据集上取得了显著的性能提升,mIoU达到了46.18%,相比之前最先进的方法提升了3.16%。此外,在Nr3D和Sr3D数据集上也取得了具有竞争力的结果。同时,该方法在3D视觉定位和2D指代图像分割任务上也表现出色,证明了其泛化能力。
🎯 应用场景
RefMask3D在机器人导航、自动驾驶、虚拟现实和增强现实等领域具有广泛的应用前景。例如,在机器人导航中,机器人可以根据自然语言指令识别并分割目标对象,从而实现更智能的交互。在自动驾驶中,可以用于识别和分割交通标志、行人等关键对象,提高驾驶安全性。
📄 摘要(原文)
3D referring segmentation is an emerging and challenging vision-language task that aims to segment the object described by a natural language expression in a point cloud scene. The key challenge behind this task is vision-language feature fusion and alignment. In this work, we propose RefMask3D to explore the comprehensive multi-modal feature interaction and understanding. First, we propose a Geometry-Enhanced Group-Word Attention to integrate language with geometrically coherent sub-clouds through cross-modal group-word attention, which effectively addresses the challenges posed by the sparse and irregular nature of point clouds. Then, we introduce a Linguistic Primitives Construction to produce semantic primitives representing distinct semantic attributes, which greatly enhance the vision-language understanding at the decoding stage. Furthermore, we introduce an Object Cluster Module that analyzes the interrelationships among linguistic primitives to consolidate their insights and pinpoint common characteristics, helping to capture holistic information and enhance the precision of target identification. The proposed RefMask3D achieves new state-of-the-art performance on 3D referring segmentation, 3D visual grounding, and also 2D referring image segmentation. Especially, RefMask3D outperforms previous state-of-the-art method by a large margin of 3.16% mIoU} on the challenging ScanRefer dataset. Code is available at https://github.com/heshuting555/RefMask3D.