Efficient Inference of Vision Instruction-Following Models with Elastic Cache
作者: Zuyan Liu, Benlin Liu, Jiahui Wang, Yuhao Dong, Guangyi Chen, Yongming Rao, Ranjay Krishna, Jiwen Lu
分类: cs.CV
发布日期: 2024-07-25
备注: Accepted to ECCV 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出Elastic Cache,加速视觉指令跟随模型推理,降低KV缓存内存需求
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉指令跟随 大模型 KV缓存 缓存优化 模型推理加速
📋 核心要点
- 现有视觉语言模型部署面临KV缓存高内存需求挑战,传统缓存淘汰策略难以满足多模态指令跟随模型的特殊性。
- Elastic Cache的核心思想是针对指令编码和输出生成阶段,采用不同的加速策略,并进行重要性驱动的缓存合并。
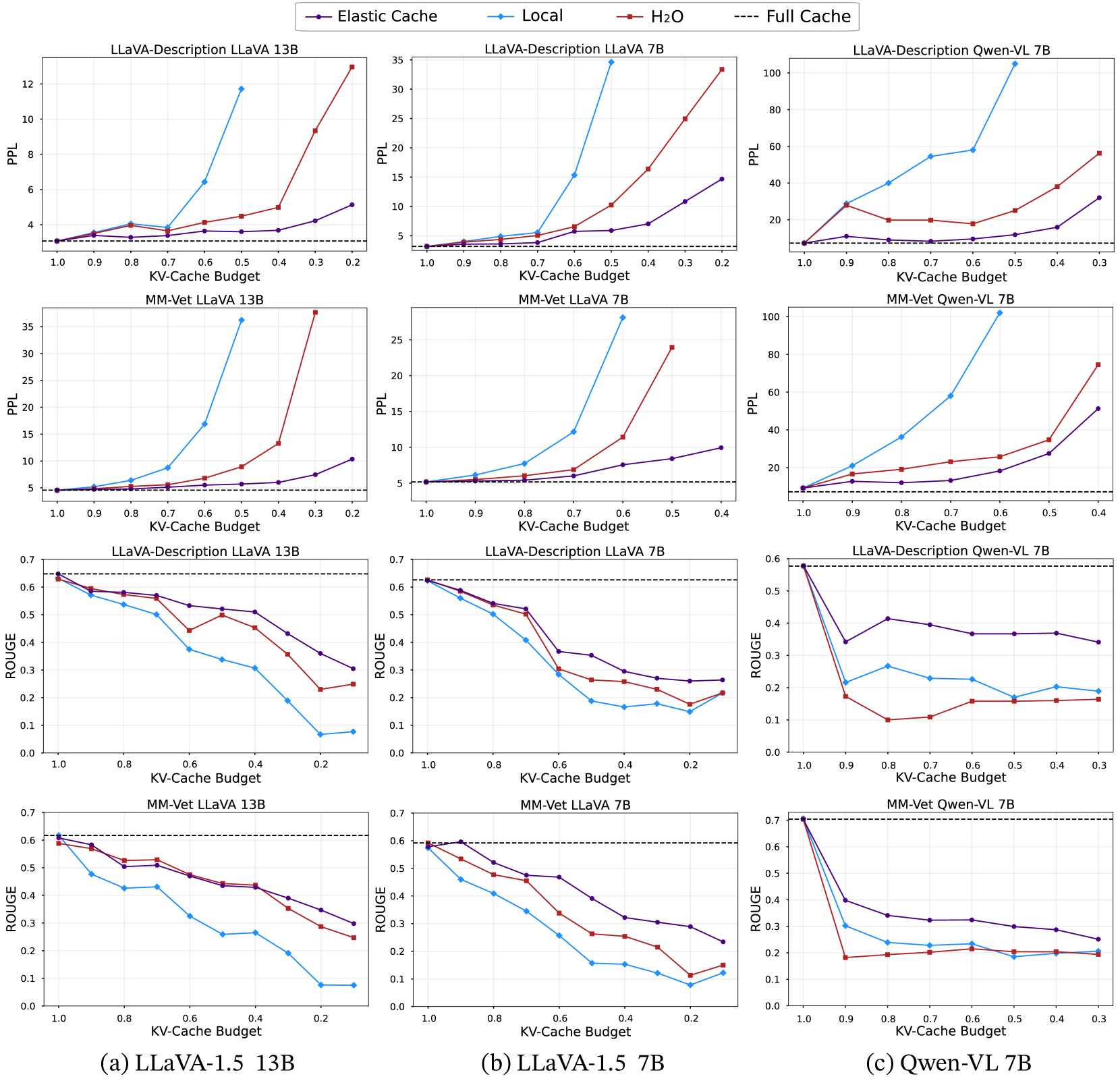
- 实验结果表明,Elastic Cache在提升推理效率的同时,显著优于现有剪枝方法,在语言生成任务上表现更佳。
📝 摘要(中文)
本文针对视觉指令跟随大模型(LVLMs)部署效率问题,特别是KV缓存的高内存需求,提出了Elastic Cache方法。现有LLM缓存管理策略侧重于缓存淘汰,未能充分满足多模态指令跟随模型的特殊需求。Elastic Cache采用指令编码和输出生成阶段差异化加速策略,研究各阶段的重要性指标,并提出重要性驱动的缓存合并策略来减少冗余缓存。该策略不直接丢弃不重要的缓存,而是将重要的键/值向量作为锚点,将周围不重要的缓存合并到这些锚点上,从而在保留上下文信息的同时实现任意加速比。指令编码阶段使用频率评估缓存重要性,输出生成阶段则基于与偏移量的距离确定token优先级,保留初始和最近的token。实验结果表明,Elastic Cache在提升效率的同时,在各种任务的语言生成方面显著优于现有的剪枝方法。
🔬 方法详解
问题定义:视觉指令跟随大模型(LVLMs)在部署时面临着巨大的内存压力,主要来源于KV缓存。传统的LLM缓存管理策略,例如缓存淘汰,通常无法有效地解决LVLMs的特殊需求,因为它们没有充分考虑到多模态输入和指令跟随任务的特性。现有的方法可能会丢弃重要的上下文信息,导致性能下降。
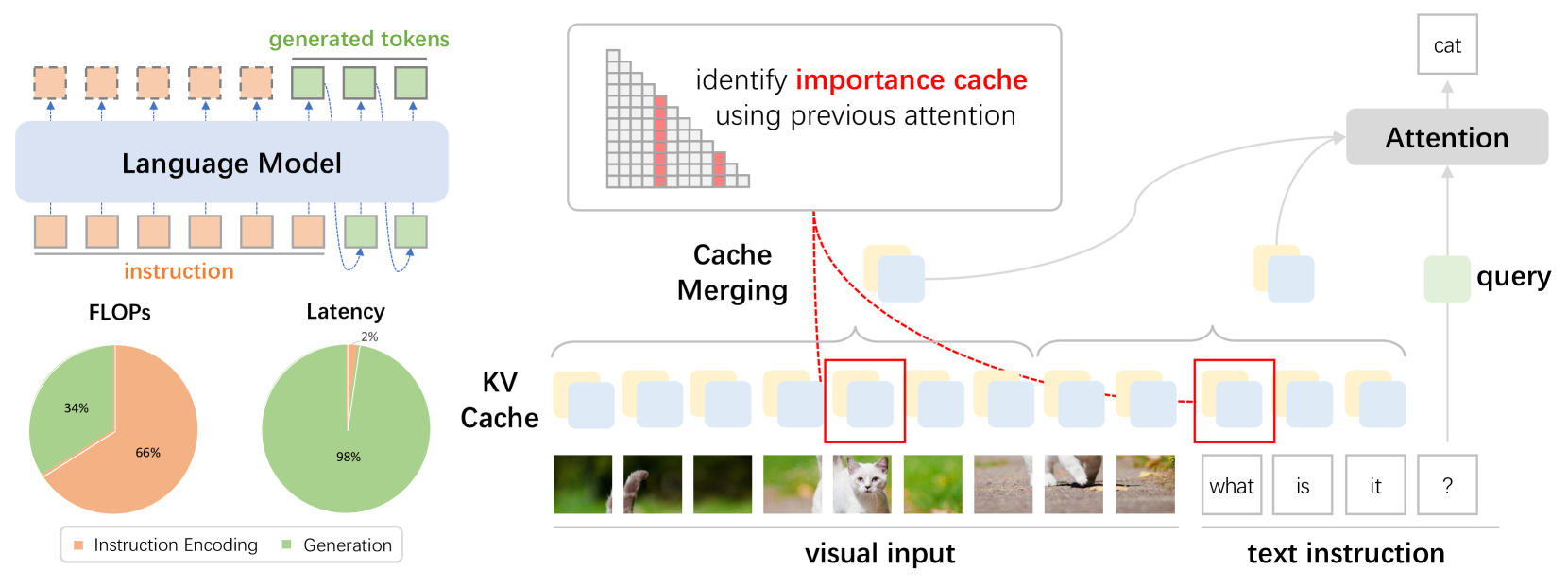
核心思路:Elastic Cache的核心思路是根据指令编码和输出生成两个阶段的不同特点,采用不同的加速策略,并通过重要性驱动的缓存合并来减少冗余缓存。关键在于不直接丢弃不重要的缓存,而是将其合并到重要的“锚点”缓存上,从而在压缩缓存的同时,尽可能保留上下文信息。
技术框架:Elastic Cache主要包含两个阶段的优化:指令编码阶段和输出生成阶段。在指令编码阶段,模型处理视觉和文本输入,生成初始的KV缓存。在输出生成阶段,模型基于指令和上下文生成文本输出。Elastic Cache在这两个阶段分别采用不同的重要性评估方法和缓存合并策略。整体流程是:输入指令 -> 指令编码(频率评估,缓存合并)-> 输出生成(距离评估,缓存合并)-> 输出文本。
关键创新:Elastic Cache最重要的创新点在于其重要性驱动的缓存合并策略。与传统的缓存淘汰方法不同,Elastic Cache不是简单地丢弃不重要的缓存,而是将其合并到重要的缓存上。这种方法能够更好地保留上下文信息,从而在压缩缓存的同时,减少性能损失。此外,针对指令编码和输出生成阶段采用不同的重要性评估方法,也更符合实际需求。
关键设计:在指令编码阶段,使用token出现的频率来评估缓存的重要性。高频token对应的缓存被认为是重要的,作为锚点。在输出生成阶段,使用token与偏移量的距离来评估重要性,保留初始和最近生成的token对应的缓存。缓存合并的具体实现方式未知,但推测可能涉及加权平均或其他融合操作。具体的参数设置和损失函数信息未知。
🖼️ 关键图片

📊 实验亮点
Elastic Cache在多个LVLM模型上进行了验证,实验结果表明,该方法在提升效率的同时,显著优于现有的剪枝方法。具体的性能数据和提升幅度在论文中给出,但摘要中未明确提及具体数值。该方法在语言生成任务上表现更佳,表明其能够更好地保留上下文信息。
🎯 应用场景
Elastic Cache具有广泛的应用前景,可以应用于各种需要高效部署视觉指令跟随大模型的场景,例如智能助手、机器人导航、图像描述生成等。通过降低内存需求,Elastic Cache可以使这些模型更容易部署在资源受限的设备上,例如移动设备和嵌入式系统。此外,该方法还可以加速模型的推理速度,提高用户体验。
📄 摘要(原文)
In the field of instruction-following large vision-language models (LVLMs), the efficient deployment of these models faces challenges, notably due to the high memory demands of their key-value (KV) caches. Conventional cache management strategies for LLMs focus on cache eviction, which often fails to address the specific needs of multimodal instruction-following models. Recognizing this gap, in this paper, we introduce Elastic Cache, a novel approach that benefits from applying distinct acceleration methods for instruction encoding and output generation stages. We investigate the metrics of importance in different stages and propose an importance-driven cache merging strategy to prune redundancy caches. Instead of discarding less important caches, our strategy identifies important key/value vectors as anchor points. Surrounding less important caches are then merged with these anchors, enhancing the preservation of contextual information in the KV caches while yielding an arbitrary acceleration ratio. For instruction encoding, we utilize the frequency to evaluate the importance of caches. Regarding output generation, we prioritize tokens based on their distance with an offset, by which both the initial and most recent tokens are retained. Results on a range of LVLMs demonstrate that Elastic Cache not only boosts efficiency but also notably outperforms existing pruning methods in language generation across various tasks. Code is available at https://github.com/liuzuyan/ElasticCache