OVR: A Dataset for Open Vocabulary Temporal Repetition Counting in Videos
作者: Debidatta Dwibedi, Yusuf Aytar, Jonathan Tompson, Andrew Zisserman
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-07-24
💡 一句话要点
提出OVR数据集用于开放词汇视频时序重复计数,并提出基线模型OVRCounter。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 视频重复计数 开放词汇 时序建模 Transformer 大规模数据集
📋 核心要点
- 现有视频重复计数数据集规模较小,且缺乏开放词汇的注释,限制了模型在复杂场景下的泛化能力。
- 论文构建了大规模开放词汇视频重复数据集OVR,包含丰富的动作和视角,并提供重复次数、时间和描述等详细标注。
- 论文提出了基于Transformer的基线模型OVRCounter,在OVR数据集上验证了其有效性,并与现有方法进行了对比。
📝 摘要(中文)
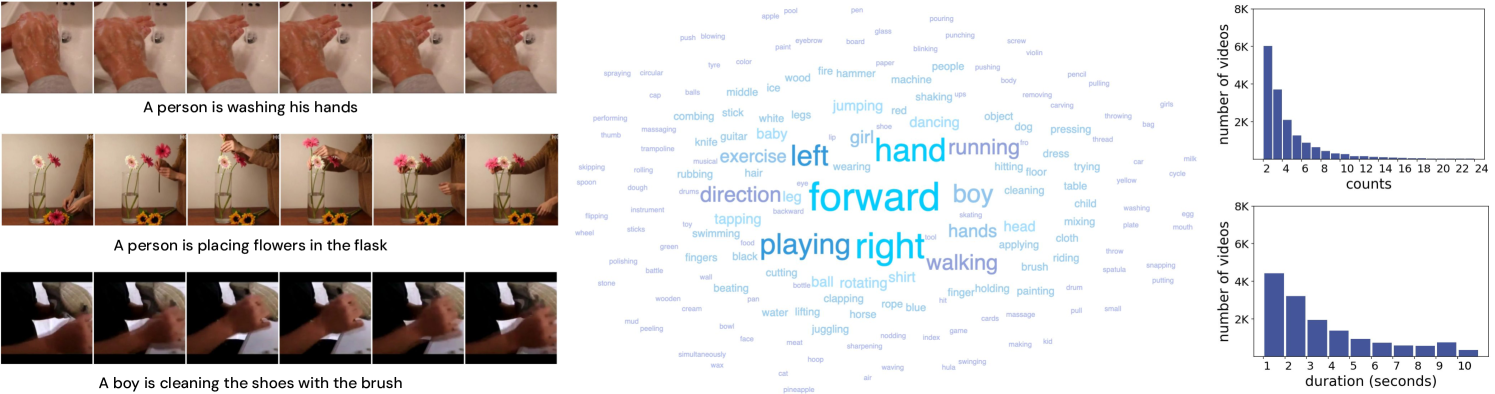
本文介绍了一个视频中时序重复注释的数据集OVR。该数据集包含超过72K个视频的注释,每个注释都指定了重复次数、重复的开始和结束时间,以及对重复内容的自由描述。注释来源于Kinetics和Ego4D视频,因此涵盖了外部视角和自我视角,以及各种各样的动作和活动。此外,OVR比以前的视频重复数据集大近一个数量级。本文还提出了一个基于Transformer的基线计数模型OVRCounter,该模型可以定位和计数长度达320帧的视频中的重复。该模型在OVR数据集上进行训练和评估,并评估了使用和不使用文本来指定要计数的目标类别时的性能。还将性能与先前的重复计数模型进行了比较。该数据集可在以下网址下载:https://sites.google.com/view/openvocabreps/
🔬 方法详解
问题定义:论文旨在解决视频中时序重复计数的问题,即给定一段视频,确定其中特定动作或事件重复出现的次数。现有方法的痛点在于数据集规模小,标注信息不足,难以支持开放词汇场景下的重复计数任务。
核心思路:论文的核心思路是构建一个大规模、开放词汇的视频重复数据集OVR,并基于此训练一个能够理解视频内容并进行重复计数的模型。通过提供丰富的标注信息,包括重复次数、起始时间和自由文本描述,模型可以学习到更鲁棒的特征表示,从而提升重复计数的准确性。
技术框架:OVRCounter模型基于Transformer架构,整体流程如下:首先,使用视频编码器提取视频帧的特征表示;然后,将特征表示输入到Transformer编码器中,学习视频的时序关系;最后,使用计数头预测视频中重复出现的次数。如果提供了文本描述,则将其编码后与视频特征融合,以指导计数过程。
关键创新:论文的关键创新在于构建了大规模开放词汇视频重复数据集OVR,并提出了一个基于Transformer的基线模型OVRCounter。OVR数据集的规模和标注信息远超现有数据集,为研究开放词汇视频重复计数提供了有力支持。OVRCounter模型能够有效地利用视频的时序信息和文本描述,实现准确的重复计数。
关键设计:OVRCounter模型使用预训练的视频编码器(例如I3D或SlowFast)提取视频帧的特征表示。Transformer编码器采用多头注意力机制,学习视频的时序关系。计数头是一个简单的线性层,将Transformer编码器的输出映射到重复次数。损失函数采用均方误差损失,衡量预测重复次数与真实重复次数之间的差异。在训练过程中,可以使用数据增强技术,例如随机裁剪和时间抖动,以提高模型的泛化能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,OVRCounter模型在OVR数据集上取得了良好的性能。在不使用文本描述的情况下,OVRCounter模型能够达到与现有方法相当的性能。当使用文本描述时,OVRCounter模型的性能得到了显著提升,表明文本信息能够有效地指导重复计数过程。OVR数据集的发布将促进开放词汇视频重复计数领域的研究。
🎯 应用场景
该研究成果可应用于视频监控、运动分析、机器人导航等领域。例如,在视频监控中,可以自动检测异常行为的重复次数,及时发出警报;在运动分析中,可以统计运动员重复动作的次数,评估训练效果;在机器人导航中,可以识别重复出现的场景,提高导航的鲁棒性。
📄 摘要(原文)
We introduce a dataset of annotations of temporal repetitions in videos. The dataset, OVR (pronounced as over), contains annotations for over 72K videos, with each annotation specifying the number of repetitions, the start and end time of the repetitions, and also a free-form description of what is repeating. The annotations are provided for videos sourced from Kinetics and Ego4D, and consequently cover both Exo and Ego viewing conditions, with a huge variety of actions and activities. Moreover, OVR is almost an order of magnitude larger than previous datasets for video repetition. We also propose a baseline transformer-based counting model, OVRCounter, that can localise and count repetitions in videos that are up to 320 frames long. The model is trained and evaluated on the OVR dataset, and its performance assessed with and without using text to specify the target class to count. The performance is also compared to a prior repetition counting model. The dataset is available for download at: https://sites.google.com/view/openvocabreps/